Archive
Mutation testing: its days in the limelight are over
How good a job does a test suite do in detecting coding mistakes in the program it tests?
Mutation testing provides one answer to this question. The idea behind mutation testing is to make a small change to the source code of the program under test (i.e., introduce a coding mistake), and then run the test suite through the mutated program (ideally one or more tests fail, as-in different behavior should be detected); rinse and repeat. The mutation score is the percentage of mutated programs that cause a test failure.
While Mutation testing is 50-years old this year (although the seminal paper did not get published until 1978), the computing resources needed to research it did not start to become widely available until the late 1980s. From then, until fuzz testing came along, mutation testing was probably the most popular technique studied by testing researchers. A collected bibliography of mutation testing lists 417 papers and 16+ PhD thesis (up to May 2014).
Mutation testing has not been taken up by industry because it tells managers what they already know, i.e., their test suite is not very good at finding coding mistakes.
Researchers concluded that the reason industry had not adopted mutation testing was that it was too resource intensive (i.e., mutate, compile, build, and run tests requires successively more resources). If mutation testing was less resource intensive, then industry would use it (to find out faster what they already knew).
Creating a code mutant is not itself resource intensive, e.g., randomly pick a point in the source and make a random change. However, the mutated source may not compile, or the resulting mutant may be equivalent to one created previously (e.g., the optimised compiled code is identical), or the program takes ages to compile and build; techniques for reducing the build overhead include mutating the compiler intermediate form and mutating the program executable.
Some changes to the source are more likely to be detected by a test suite than others, e.g., replacing <= by > is more likely to be detected than replacing it by < or ==. Various techniques for context dependent mutations have been proposed, e.g., handling of conditionals.
While mutation researchers were being ignored by industry, another group of researchers were listening to industry's problems with testing; automatic test case generation took off. How might different test case generators be compared? Mutation testing offers a means of evaluating the performance of tools that arrived on the scene (in practice, many researchers and tool vendors cite statement or block coverage numbers).
Perhaps industry might have to start showing some interest in mutation testing.
A fundamental concern is the extent to which mutation operators modify source in a way that is representative of the kinds of mistakes made by programmers.
The competent programmer hypothesis is often cited, by researchers, as the answer to this question. The hypothesis is that competent programmers write code/programs that is close to correct; the implied conclusion being that mutations, which are small changes, must therefore be like programmer mistakes (the citation often given as the source of this hypothesis discusses data selection during testing, but does mention the term competent programmer).
Until a few years ago, most analysis of fixes of reported faults looked at what coding constructs were involved in correcting the source code, e.g., 296 mistakes in TeX reported by Knuth. This information can be used to generate a probability table for selecting when to mutate one token into another token.
Studies of where the source code was changed, to fix a reported fault, show that existing mutation operators are not representative of a large percentage of existing coding mistakes; for instance, around 60% of 290 source code fixes to AspectJ involved more than one line (mutations usually involve a single line of source {because they operate on single statements and most statements occupy one line}), another study investigating many more fixes found only 10% of fixes involved one line, and similar findings for a study of C, Java, Python, and Haskell (a working link to the data, which is a bit disjointed of a mess).
These studies, which investigated the location of all the source code that needs to be changed, to fix a mistake, show that existing mutation operators are not representative of most human coding mistakes. To become representative, mutation operators need to be capable of making coupled changes across multiple lines/functions/methods and even files.
While arguments over the validity of the competent programmer hypothesis rumble on, the need for multi-line changes remains.
Given the lack of any major use-cases for mutation testing, it does not look like it is worth investing lots of resources on this topic. Researchers who have spent a large chunk of their career working on mutation testing will probably argue that you never know what use-cases might crop up in the future. In practice, mutation research will probably fade away because something new and more interesting has come along, i.e., fuzz testing.
There will always be niche use-cases for mutation. For instance, how likely is it that a random change to the source of a formal proof will go unnoticed by its associated proof checker (i.e., the proof checking tool output remains unchanged)?
A study based on mutating the source of Coq verification projects found that 7% of mutations had no impact on the results.
Code bureaucracy can reduce the demand for cognitive resources
A few weeks ago I discussed why I thought that research code was likely to remain a tangled mess of spaghetti code.
Everybody’s writing, independent of work-place, starts out as a tangled mess of spaghetti code; some people learn to write code in a less cognitively demanding style, and others stick with stream-of-conscious writing.
Why is writing a tangled mess of spaghetti code (sometimes) not cost-effective, and what are the benefits in making a personal investment in learning to write code in another style?
Perhaps the defining characteristic of a tangled mess of spaghetti code is that everything appears to depend on everything else, consequently: working out the impact of a change to some sequence of code requires an understanding of all the other code (to find out what really does depend on what).
When first starting to learn to program, the people who can hold the necessary information on increasing amounts of code in their head are the ones who manage to create running (of sorts) programs; they have the ‘knack’.
The limiting factor for an individual’s software development is the amount of code they can fit in their head, while going about their daily activities. The metric ‘code that can be fitted in a person’s head’ is an easy concept to grasp, but its definition in terms of the cognitive capacity to store, combine and analyse information in long term memory and the episodic memory of earlier work is difficult to pin down. The reason people live a monks existence when single-handedly writing 30-100 KLOC spaghetti programs (the C preprocessor Richard Stallman wrote for gcc is a good example), is that they have to shut out all other calls on their cognitive resources.
Given time, and the opportunity for some trial and error, a newbie programmer who does not shut their non-coding life down can create, say, a 1,000+ LOC program. Things work well enough, what is the problem?
The problems start when the author stops working on the code for long enough for them to forget important dependencies; making changes to the code now causes things to mysteriously stop working. Our not so newbie programmer now has to go through the frustrating and ego-denting experience of reacquainting themselves with how the code fits together.
There are ways of organizing code such that less cognitive resources are needed to work on it, compared to a tangled mess of spaghetti code. Every professional developer has a view on how best to organize code, what they all have in common is a lack of evidence for their performance relative to other possibilities.
Code bureaucracy does not sound like something that anybody would want to add to their program, but it succinctly describes the underlying principle of all the effective organizational techniques for code.
Bureaucracy compartmentalizes code and arranges the compartments into some form of hierarchy. The hoped-for benefit of this bureaucracy is a reduction in the cognitive resources needed to work on the code. Compartmentalization can significantly reduce the amount of a program’s code that a developer needs to keep in their head, when working on some functionality. It is possible for code to be compartmentalized in a way that requires even more cognitive resources to implement some functionality than without the bureaucracy. Figuring out the appropriate bureaucracy is a skill that comes with practice and knowledge of the application domain.
Once a newbie programmer is up and running (i.e., creating programs that work well enough), they often view the code bureaucracy approach as something that does not apply to them (and if they rarely write code, it might not apply to them). Stream of conscious coding works for them, why change?
I have seen people switch to using code bureaucracy for two reasons:
- peer pressure. They join a group of developers who develop using some form of code bureaucracy, and their boss tells them that this is the way they have to work. In this case there is the added benefit of being able to discuss things with others,
- multiple experiences of the costs of failure. The costs may come from the failure to scale a program beyond some amount of code, or having to keep investing in learning how previously written programs work.
Code bureaucracy has many layers. At the bottom there is splitting code up into functions/methods, then at the next layer related functions are collected together into files/classes, then the layers become less generally agreed upon (different directories are often involved).
One of the benefits of bureaucracy, from the management perspective, is interchangeability of people. Why would somebody make an investment in code bureaucracy if they were not the one likely to reap the benefit?
A claimed benefit of code bureaucracy is ease of wholesale replacement of one compartment by a new one. My experience, along with the little data I have seen, suggests that major replacement is rare, i.e., this is not a commonly accrued benefit.
Another claimed benefit of code bureaucracy is that it makes programs easier to test. What does ‘easier to test’ mean? I have seen reliable programs built from spaghetti code, and unreliable programs packed with code bureaucracy. A more accurate claim is that it can be unexpectedly costly to test programs built from spaghetti code after they have been changed (because of the greater likelihood of the changes having unexpected consequences). A surprising number of programs built from spaghetti code continue to be used in unmodified form for years, because nobody dare risk the cost of checking that they continue to work as expected after a modification
Source code discovery, skipping over the legal complications
The 2020 US elections introduced the issue of source code discovery, in legal cases, to a wider audience. People wanted to (and still do) check that the software used to register and count votes works as intended, but the companies who wrote the software wouldn’t make it available and the courts did not compel them to do so.
I was surprised to see that there is even a section on “Transfer of or access to source code” in the EU-UK trade and cooperation agreement, agreed on Christmas Eve.
I have many years of experience in discovering problems in the source code of programs I did not write. This experience derives from my time as a compiler implementer (e.g., a big customer is being held up by a serious issue in their application, and the compiler is being blamed), and as a static analysis tool vendor (e.g., managers want to know about what serious mistakes may exist in the code of their products). In all cases those involved wanted me there, I could talk to some of those involved in developing the code, and there were known problems with the code. In court cases, the defence does not want the prosecution looking at the code, and I assume that all conversations with the people who wrote the code goes via the lawyers. I have intentionally stayed away from this kind of work, so my practical experience of working on legal discovery is zero.
The most common reason companies give for not wanting to make their source code available is that it contains trade-secrets (they can hardly say that it’s because they don’t want any mistakes in the code to be discovered).
What kind of trade-secrets might source code contain? Most code is very dull, and for some programs the only trade-secret is that if you put in the implementation effort, the obvious way of doing things works, i.e., the secret sauce promoted by the marketing department is all smoke and mirrors (I have had senior management, who have probably never seen the code, tell me about the wondrous properties of their code, which I had seen and knew that nothing special was present).
Comments may detail embarrassing facts, aka trade-secrets. Sometimes the code interfaces to a proprietary interface format that the company wants to keep secret, or uses some formula that required a lot of R&D (management gets very upset when told that ‘secret’ formula can be reverse engineered from the executable code).
Why does a legal team want access to source code?
If the purpose is to check specific functionality, then reading the source code is probably the fastest technique. For instance, checking whether a particular set of input values can cause a specific behavior to occur, or tracing through the logic to understand the circumstances under which a particular behavior occurs, or in software patent litigation checking what algorithms or formula are being used (this is where trade-secret claims appear to be valid).
If the purpose is a fishing expedition looking for possible incorrect behaviors, having the source code is probably not that useful. The quantity of source contained in modern applications can be huge, e.g., tens to hundreds of thousands of lines.
In ancient times (i.e., the 1970s and 1980s) programs were short (because most computers had tiny amounts of memory, compared to post-2000), and it was practical to read the source to understand a program. Customer demand for more features, and the fact that greater storage capacity removed the need to spend time reducing code size, means that source code ballooned. The following plot shows the lines of code contained in the collected algorithms of the Transactions on Mathematical Software, the red line is a fitted regression model of the form:  (code+data):
(code+data):
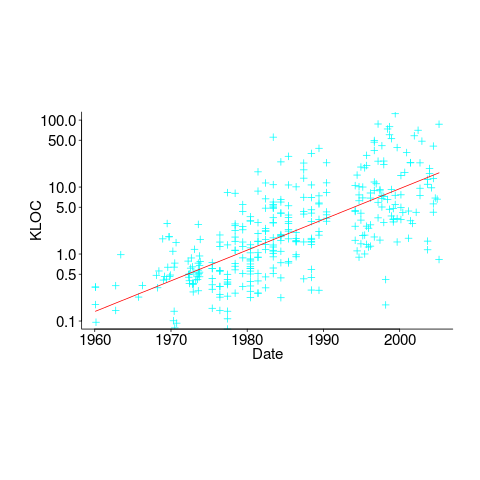
How, by reading the source code, does anybody find mistakes in a 10+ thousand line program? If the program only occasionally misbehaves, finding a coding mistake by reading the source is likely to be very very time-consuming, i.e, months. Work it out yourself: 10K lines of code is around 200 pages. How long would it take you to remember all the details and their interdependencies of a detailed 200-page technical discussion well enough to spot an inconsistency likely to cause a fault experience? And, yes, the source may very well be provided as a printout, or as a pdf on a protected memory stick.
From my limited reading of accounts of software discovery, the time available to study the code may be just days or maybe a week or two.
Reading large quantities of code, to discover possible coding mistakes, are an inefficient use of human time resources. Some form of analysis tool might help. Static analysis tools are one option; these cost money and might not be available for the language or dialect in which the source is written (there are some good tools for C because it has been around so long and is widely used).
Character assassination, or guilt by innuendo is another approach; the code just cannot be trusted to behave in a reasonable manner (this approach is regularly used in the software business). Software metrics are deployed to give the impression that it is likely that mistakes exist, without specifying specific mistakes in the code, e.g., this metric is much higher than is considered reasonable. Where did these reasonable values come from? Someone, somewhere said something, the Moon aligned with Mars and these values became accepted ‘wisdom’ (no, reality is not allowed to intrude; the case is made by arguing from authority). McCabe’s complexity metric is a favorite, and I have written how use of this metric is essentially accounting fraud (I have had emails from several people who are very unhappy about me saying this). Halstead’s metrics are another favorite, and at least Halstead and others at the time did some empirical analysis (the results showed how ineffective the metrics were; the metrics don’t calculate the quantities claimed).
The software development process used to create software is another popular means of character assassination. People seem to take comfort in the idea that software was created using a defined process, and use of ad-hoc methods provides an easy target for ridicule. Some processes work because they include lots of testing, and doing lots of testing will of course improve reliability. I have seen development groups use a process and fail to produce reliable software, and I have seen ad-hoc methods produce reliable software.
From what I can tell, some expert witnesses are chosen for their ability to project an air of authority and having impressive sounding credentials, not for their hands-on ability to dissect code. In other words, just the kind of person needed for a legal strategy based on character assassination, or guilt by innuendo.
What is the most cost-effective way of finding reliability problems in software built from 10k+ lines of code? My money is on fuzz testing, a term that should send shivers down the spine of a defense team. Source code is not required, and the output is a list of real fault experiences. There are a few catches: 1) the software probably to be run in the cloud (perhaps the only cost/time effective way of running the many thousands of tests), and the defense is going to object over licensing issues (they don’t want the code fuzzed), 2) having lots of test harnesses interacting with a central database is likely to be problematic, 3) support for emulating embedded cpus, even commonly used ones like the Z80, is currently poor (this is a rapidly evolving area, so check current status).
Fuzzing can also be used to estimate the numbers of so-far undetected coding mistakes.
Having all the source code in one file
An early, and supposedly influential, analysis of the Coronavirus outbreak was based on results from a model whose 15,000 line C implementation was contained in a single file. There has been lots of tut-tutting from the peanut gallery, about the code all being in one file rather than distributed over many files. The source on Github has been heavily reworked.
Why do programmers work with all the code in one file, rather than split across multiple files? What are the costs and benefits of having the 15K of source in one file, compared to distributing it across multiple files?
There are two kinds of people who work with code all in one file, novices and really capable developers. Richard Stallman is an example of a very capable developer who worked using files containing huge amounts of code, as anybody who looked at the early sources of gcc will be all to familiar.
The benefit of having all the code in one file is that it is easy to find stuff and make global changes. If the source is scattered over multiple files, then working on the code entails knowing which file to look in to find whatever; there is a learning curve (these days screens have lots of pixels, and editors support multiple windows with a different file in each window; I’m sure lots of readers work like this).
Many years ago, when 64K was a lot of memory, I sometimes had to do developer support: people would come to me complaining that the computer was preventing them writing a larger program. What had happened was they had hit the capacity limit of the editor. The source now had to be spread over multiple files to get over this ‘limitation’. In practice people experienced the benefits of using multiple files, e.g., editor loading files faster (because they were a lot smaller) and reduced program build time (because only the code that changed needed to be recompiled).
These days, 15K of source can be loaded or compiled in a blink of an eye (unless a really cheap laptop is being used). Computing power has significantly reduced these benefits that used to exist.
What costs might be associated with keeping all the source in one file?
Monolithic code makes sharing difficult. I don’t know anything about the development environment within which these researched worked. If there were lots of different programs using the same algorithms, or reading/writing the same file formats, then code reuse often provides a benefit that makes it worthwhile splitting off the common functionality. But then the researchers has to learn how to build a program from multiple source files, which a surprising number are unwilling to do (at least it has always been surprising to me).
Within a research group, sharing across researchers might be a possible (assuming they are making some use of the same algorithms and file formats). Involving multiple people in the ongoing evolution of software creates a need for some coordination. At the individual level it may be more cost-efficient for people to have their own private copies of the source, with savings only occurring at the group level. With software development having a low status in academia, I don’t see any of the senior researchers willingly take on a management role, for this code. Perhaps one of the people working on the code is much better than the others (it often happens), but are they going to volunteer themselves as chief dogs body for the code?
In the world of Open Source, where source code is available, cut-and-paste is rampant (along with wholesale copying of files). Working with a copy of somebody else’s source removes a dependency, and if their code works well enough, then go for it.
A cost often claimed by the peanut gallery is that having all the code in a single file is a signal of buggy code. Given that most of the programmers who do this are novices, rather than really capable developers, such code is likely to contain many mistakes. But splitting the code up into multiple files will not reduce the number of mistakes it contains, just distribute them among the files. Correlation is not causation.
For an individual developer, the main benefit of splitting code across multiple files is that it makes developers think about the structure of their code.
For multi-person projects there are the added potential benefits of reusing code, and reducing the time spent reading other people’s code (it’s no fun having to deal with 10K lines when only a few functions are of interest).
I’m not saying that the original code is good, bad, or indifferent. What I am saying is that the having all the source in one file may, or may not, be the most effective way of working. It’s complicated, and I have no problem going with the flow (and limiting the size of the source files I write), but let’s not criticise others for doing what works for them.
Motzkin paths and source code silhouettes
Consider a language that just contains assignments and if-statements (no else arm). Nesting level could be used to visualize programs written in such a language; an if represented by an Up step, an assignment by a Level step, and the if-terminator (e.g., the } token) by a Down step. Silhouettes for the nine possible four line programs are shown in the figure below (image courtesy of Wikipedia). I use the term silhouette because the obvious terms (e.g., path and trace) have other common usage meanings.

How many silhouettes are possible, for a function containing  statements? Motzkin numbers provide the answer; the number of silhouettes for functions containing from zero to 20 statements is: 1, 1, 2, 4, 9, 21, 51, 127, 323, 835, 2188, 5798, 15511, 41835, 113634, 310572, 853467, 2356779, 6536382, 18199284, 50852019. The recurrence relation for Motzkin numbers is (where is the total number of steps, i.e., statements):
statements? Motzkin numbers provide the answer; the number of silhouettes for functions containing from zero to 20 statements is: 1, 1, 2, 4, 9, 21, 51, 127, 323, 835, 2188, 5798, 15511, 41835, 113634, 310572, 853467, 2356779, 6536382, 18199284, 50852019. The recurrence relation for Motzkin numbers is (where is the total number of steps, i.e., statements):
m_n = (2n+1)m_{n-1}+3(n-1)m_{n-2}")
Human written code contains recurring patterns; the probability of encountering an if-statement, when reading code, is around 17% (at least for the C source of some desktop applications). What does an upward probability of 17% do to the Motzkin recurrence relation? For many years, I have been keeping my eyes open for possible answers (solving the number theory involved is well above my mathematics pay grade). A few days ago, I discovered weighted Motzkin paths.
A weighted Motzkin path is one where the Up, Level and Down steps each have distinct weights. The recurrence relationship for weighted Motzkin paths is expressed in terms of number of colored steps, where:  is the number of possible colors for the Level steps, and
is the number of possible colors for the Level steps, and  is the number of possible colors for Down steps; Up steps are assumed to have a single color:
is the number of possible colors for Down steps; Up steps are assumed to have a single color:
m_n = d(2n+1)m_{n-1}+(4c-d^2)(n-1)m_{n-2}")
setting:  and
and  (i.e., all kinds of step have one color) recovers the original relation.
(i.e., all kinds of step have one color) recovers the original relation.
The different colored Level steps might be interpreted as different kinds of non-nesting statement sequences, and the different colored Down steps might be interpreted as different ways of decreasing nesting by one (e.g., a goto statement).
The connection between weighted Motzkin paths and probability is that the colors can be treated as weights that add up to 1. Searching on “weighted Motzkin” returns the kind of information I had been looking for; it seems that researchers in other fields had already discovered weighted Motzkin paths, and produced some interesting results.
If an automatic source code generator outputs the start of an if statement (i.e., an Up step) with probability  , an assignment (i.e., a Level step) with probability
, an assignment (i.e., a Level step) with probability  , and terminates the
, and terminates the if (i.e., a Down step) with probability  , what is the probability that the function will contain at least
, what is the probability that the function will contain at least  statements? The answer, courtesy of applying Motzkin paths in research into clone cell distributions, is:
statements? The answer, courtesy of applying Motzkin paths in research into clone cell distributions, is:
![P_n=sum{i=0}{delim{[}{(n-2)/2}{]}}(matrix{2}{1}{{n-2} {2i}})C_{2i}a^{i}b^{n-2-2i}c^{i+1}](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_960.5_57086dac25a2ff31c2230f0791800e35.png "P_n=sum{i=0}{delim{[}{(n-2)/2}{]}}(matrix{2}{1}{{n-2} {2i}})C_{2i}a^{i}b^{n-2-2i}c^{i+1}")
where:  is the
is the  ‘th Catalan number, and that
‘th Catalan number, and that [...] is a truncation; code for an implementation in R.
In human written code we know that  , because the number of statements in a compound-statement roughly has an exponential distribution (at least in C).
, because the number of statements in a compound-statement roughly has an exponential distribution (at least in C).
There has been some work looking at the number of peaks in a Motzkin path, with one formula for the total number of peaks in all Motzkin paths of length n. A formula for the number of paths of length , having  peaks, would be interesting.
peaks, would be interesting.
Motzkin numbers have been extended to what is called higher-rank, where Up steps and Level steps can be greater than one. There are statements that can reduce nesting level by more than one, e.g., breaking out of loops, but no constructs increase nesting by more than one (that I can think of). Perhaps the rather complicated relationship can be adapted to greater Down steps.
Other kinds of statements can increase nesting level, e.g., for-statements and while-statements. I have not yet spotted any papers dealing with the case where an Up step eventually has a corresponding Down step at the appropriate nesting level (needed to handle different kinds of nest-creating constructs). Pointers welcome. A related problem is handling if-statements containing else arms, here there is an associated increase in nesting.
What characteristics does human written code have that results in it having particular kinds of silhouettes? I have been thinking about this for a while, but have no good answers.
If you spot any Motzkin related papers that you think could be applied to source code analysis, please let me know.
Update
A solution to the Number of statement sequences possible using N if-statements problem.
Source code chapter of ‘evidence-based software engineering’ reworked
The Source code chapter of my evidence-based software engineering book has been reworked (draft pdf).
When writing the first version of this chapter, I was not certain whether source code was a topic warranting a chapter to itself, in an evidence-based software engineering book. Now I am certain. Source code is the primary product delivery, for a software system, and it is takes up much of the available cognitive effort.
What are the desirable characteristics that source code should have, to minimise production costs per unit of functionality? This is what an evidence-based chapter on source code is all about.
The release of this chapter completes my second pass over the material. Readers will notice the text still contains ... and ?‘s. The third pass will either delete these, or say something interesting (I suspect mostly the former, because of lack of data).
Talking of data, February has been a bumper month for data (apologies if you responded to my email asking for data, and it has not appeared in this release; a higher than average number of people have replied with data).
The plan is to spend a few months getting a beta release ready. Have the beta release run over the summer, with the book in the shops for Christmas.
I’m looking at getting a few hundred printed, for those wanting paper.
The only publisher that did not mind me making the pdf freely available was MIT Press. Unfortunately one of the reviewers was foaming at the mouth about the things I had to say about software engineering researcher (it did not help that I had written a blog post containing a less than glowing commentary on academic researchers, the week of the review {mid-2017}); the second reviewer was mildly against, and the third recommended it.
If any readers knows the editors at MIT Press, do suggest they have another look at the book. I would rather a real publisher make paper available.
Next, getting the ‘statistics for software engineers’ second half of the book ready for a beta release.
Source code has a brief and lonely existence
The majority of source code has a short lifespan (i.e., a few years), and is only ever modified by one person (i.e., 60%).
Literate programming is all well and good for code written to appear in a book that the author hopes will be read for many years, but this is a tiny sliver of the source code ecosystem. The majority of code is never modified, once written, and does not hang around for very long; an investment is source code futures will make a loss unless the returns are spectacular.
What evidence do I have for these claims?
There is lots of evidence for the code having a short lifespan, and not so much for the number of people modifying it (and none for the number of people reading it).
The lifespan evidence is derived from data in my evidence-based software engineering book, and blog posts on software system lifespans, and survival times of Linux distributions. Lifespan in short because Packages are updated, and third-parties change/delete APIs (things may settle down in the future).
People who think source code has a long lifespan are suffering from survivorship bias, i.e., there are a small percentage of programs that are actively used for many years.
Around 60% of functions are only ever modified by one author; based on a study of the change history of functions in Evolution (114,485 changes to functions over 10 years), and Apache (14,072 changes over 12 years); a study investigating the number of people modifying files in Eclipse. Pointers to other studies that have welcome.
One consequence of the short life expectancy of source code is that, any investment made with the expectation of saving on future maintenance costs needs to return many multiples of the original investment. When many programs don’t live long enough to be maintained, those with a long lifespan have to pay the original investments made in all the source that quickly disappeared.
One benefit of short life expectancy is that most coding mistakes don’t live long enough to trigger a fault experience; the code containing the mistake is deleted or replaced before anybody notices the mistake.
Update: a few days later
I was remiss in not posting some plots for people to look at (code+data).
The plot below shows number of function, in Evolution, modified a given number of times (left), and functions modified by a given number of authors (right). The lines are a bi-exponential fit.

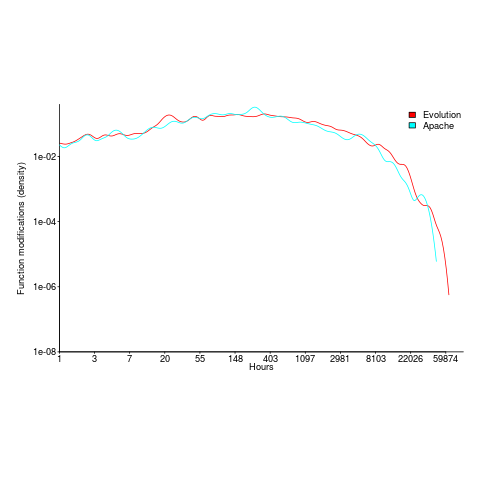
What is the interval (in hours) between between modifications of a function? The plot below has a logarithmic x-axis, and is sort-of flat over most of the range (you need to squint a bit). This is roughly saying that the probability of modification in hours 1-3 is the same as in hours 3-7, and hours, 7-15, etc (i.e., keep doubling the hour interval). At round 10,000 hours function modification probability drops like a stone.
Source code chapter added to “Evidence-based software engineering using R”
The Source Code chapter of my evidence-based software engineering book has been added to the draft pdf (download here).
This chapter has suffered from coming last and there is still lots of work to be done. Almost all the source code related data has been plundered to fill up earlier chapters. Some data did not make the cut-off for release of the draft; a global review will probably result in some data migrating back to this chapter.
When talking to developers about the book I am constantly being asked ‘what is empirical software engineering?’ My explanation uses the phrase ‘evidence-based’, which everybody seems to immediately understand. It is counterproductive having a title that has to be explained, so I have changed the title to “Evidence-based Software Engineering using R”.
What is the purpose of a chapter discussing source code in a book on evidence-based software engineering? Source code is obviously an essential component of the topics discussed in the other chapters, but what is so particular to source code that it could not be said elsewhere? Having spent most of my professional life studying source code, first as a compiler writer and then involved with static analysis, am I just being driven by an attachment to the subject?
My view of source code is very different from most other developers: when developers talk about code, they spend most of the time talking about how they do things, when I talk about code I spend most of the time talking about how other developers do things (I’m a mongrel writer of code). Developers’ blinkered view of code prevents them seeing bigger pictures. I take a Gricean view of code and refrain from using meaningless marketing terms such as maintainability, readability and testability.
I have lots of source code data of interest to compiler writers (who are not the target audience) and I have lots of data related to static analysis (tool developers are not the audience). The target audience is professional software developers and hopefully what has been written is of interest to that readership.
I have been promised all sorts of data. Hopefully some of it will arrive. If somebody tells you they promised to send me data, please encourage them to take some time to sort out the data and send it.
As always, if you know of any interesting software engineering data, please tell me.
Finalizing the statistical analysis material in the second half of the book (released almost two years ago) next.
First use of: software, software engineering and source code
While reading some software related books/reports/articles written during the 1950s, I suddenly realized that the word ‘software’ was not being used. This set me off looking for the earliest use of various computer terms.
My search process consisted of using pfgrep on my collection of pdfs of documents from the 1950s and 60s, and looking in the index of the few old computer books I still have.
Software: The Oxford English Dictionary (OED) cites an article by John Tukey published in the American Mathematical Monthly during 1958 as the first published use of software: “The ‘software’ comprising … interpretive routines, compilers, and other aspects of automotive programming are at least as important to the modern electronic calculator as its ‘hardware’.”
I have a copy of the second edition of “An Introduction to Automatic Computers” by Ned Chapin, published in 1963, which does a great job of defining the various kinds of software. Earlier editions were published in 1955 and 1957. Did these earlier edition also contain various definitions of software? I cannot find any reasonably prices copies on the second-hand book market. Do any readers have a copy?
Update: I now have a copy of the 1957 edition of Chapin’s book. It discusses programming, but there is no mention of software.
Software engineering: The OED cites a 1966 “letter to the ACM membership” by Anthony A. Oettinger, then ACM President: “We must recognize ourselves … as members of an engineering profession, be it hardware engineering or software engineering.”
The June 1965 issue of COMPUTERS and AUTOMATION, in its Roster of organizations in the computer field, has the list of services offered by Abacus Information Management Co.: “systems software engineering”, and by Halbrecht Associates, Inc.: “software engineering”. This pushes the first use of software engineering back by a year.
Source code: The OED cites a 1965 issue of Communications ACM: “The PUFFT source language listing provides a cross-reference between the source code and the object code.”
The December 1959 Proceedings of the EASTERN JOINT COMPUTER CONFERENCE contains the article: “SIMCOM – The Simulator Compiler” by Thomas G. Sanborn. On page 140 we have: “The compiler uses this convention to aid in distinguishing between SIMCOM statements and SCAT instructions which may be included in the source code.”
Update: The October 1956 issue of Computers and Automation contains an extensive glossary. It does not have any entries for software or source code.
Running pdfgrep over the archive of documents on bitsavers would probably throw up all manners of early users of software related terms.
The paper: What’s in a name? Origins, transpositions and transformations of the triptych Algorithm -Code -Program is a detailed survey of the use of three software terms.
A 1931 article using the term Super Computing machine to refer to a Punched card machine that could do arithmetic on numeric values contained on the card.
Collecting all of the publicly available source code
Collecting together all the software ever written is impossible, but collecting everything that can be found would create something very useful (since I have always been interested in source code analysis, my opinion is biased).
Collecting together source available on the internet is easy. Creating a copy of Github is one of the first actions of anybody with ambitions of collecting lots of source (back in the day it was collecting shareware 5″ 1/4, then 3″ 1/2 floppy discs, then CDs and then DVDs).
The very hard to collect items “exist” on line-printer paper, punched cards, rolls of punched tape and mag tape. These are the items where serious collectors should concentrate their efforts (NASA lost a lot of Voyager data when magnetic particles fell off the plastic strips of tape reels in storage, because the adhesive had degraded).
The Internet Archive is doing a great job of collecting and making available ‘antique’ source code (old computer games is a popular genre; other collectors concentrate on being able to execute ROM images of games), but they are primarily US based.
Collecting the World’s source code requires collection organizations in every country. Collecting old code is a people intensive business and requires lots of local knowledge.
A new source code collection organization has recently been setup in France; the Software Heritage currently aims to collect all software that is publicly available. So far they have done what everybody else does, made a copy of Github and a couple of the well-known source repos.
I hope this organization is not just the French government throwing money at another one-upmanship US vs. France project.
If those involved are serious about collecting source code, rather than enjoying the perks of a tax-funded show project, they will realise that lots of French specific source code is dotted around the country needing to be collected now (before the media decomposes and those who know how to read it die).
Recent Comments