Archive
Long term growth of programming language use
The names of files containing source code often include a suffix denoting the programming language used, e.g., .c for C source code. These suffixes provide a cheap and cheerful method for estimating programming language use within a file system directory.
This method has its flaws, with two main factors introducing uncertainty into the results:
- The suffix denoting something other than the designated programming language.
- Developer choice of suffix can change over time and across development environments, e.g., widely used Fortran suffixes include
.f,.for,.ftn, and .f77(Fortran77 was the second revision of the ANSI, and the version I used intensely for several years; ChatGPT only lists later versions, i.e.,f90,f95, etc).
The paper: 50 Years of Programming Language Evolution through the Software Heritage looking glass by A. Desmazières, R. Di Cosmo, and V. Lorentz uses filename suffixes to track the use of programming languages over time. The suffix data comes from the Software Heritage, which aims to collect, and share all publicly available source code, and it currently hosts over 20 billion unique source files.
The authors extract and count all filename suffixes from the Software Heritage archive, obtaining 2,836,119 unique suffixes. GitHub’s linguist catalogue of file extensions was used to identify programming languages. The top 10 most used programming languages, since 2000, are found and various quantities plotted.
A 1976 report found that at least 450 programming languages were in use at the US Department of Defense, and as of 2020 close to 9,000 languages are listed on hopl.info. The linguist catalogue contains information on 512 programming languages, with a strong bias towards languages to write open source. It is missing entries for Cobol and Ada, and its Fortran suffix list does not include .for, .ftn and .f77.
The following analysis takes an all encompassing approach. All suffixes containing at up to three characters, the first of which is alphabetic, and occurring at least 1,000 times in any year, are initially assumed to denote a programming language; the suffixes .html, .java and .json are special cased (4,050 suffixes). This initial list is filtered to remove known binary file formats, e.g., .zip and .jar. The common file extensions listed on FileInfo were filtered using the algorithm applied to the Software Heritage suffixes, producing 3,990 suffixes (the .ftn suffix, and a few others, were manually spotted and removed). Removing binary suffixes reduced the number of assumed language suffixes from 4,050 (15,658,087,071 files) to 2,242 (9,761,794,979 files).
This approach is overly generous, and includes suffixes that have not been used to denote programming language source code.
The plot below shows the number of assumed source code files created in each year (only 50% of files have a creation date), with a fitted regression line showing a 31% annual growth in files over 52 years (code+data):
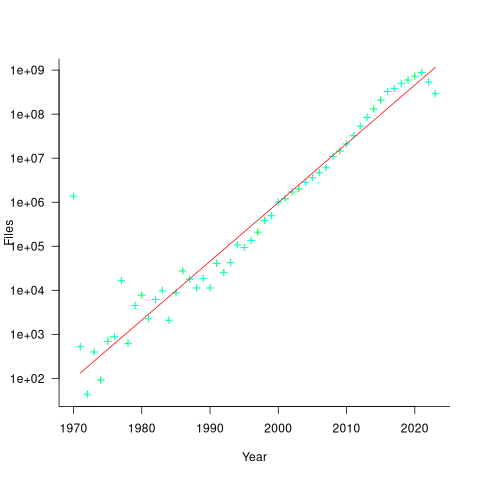
Some of the apparent growth is actually the result of older source being more likely to be lost.
Unix timestamps start on 1 Jan 1970. Most of the 1,411,277 files with a 1970 creation date probably acquired this date because of a broken conversion between version control systems.
The plot below shows the number of files assumed to contain source code in a given language per year, with some suffixes used before the language was invented (its starts in 1979, when total file counts stat always being over 1,000; code+data):
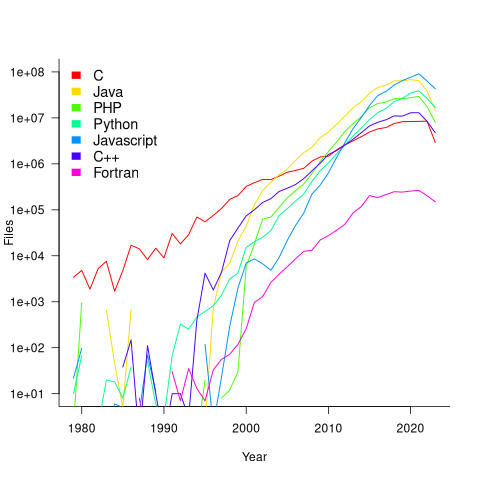
Over the last few years, survey results have been interpreted as showing declining use of C. This plot suggests that use of C is continuing to grow at around historical rates, but that use of other languages has grown rapidly to claim a greater percentage of developer implementation effort.
The major issue with this plot is what is not there. Where is the Cobol, once the most widely used language? Did Fortran only start to be used during the 1990s? Millions of lines of Cobol and Fortran were written between 1960 and 1985, but very little of this code is publicly available.
Quantity of source in a given language
How much source code exists in a particular language?
Traditionally, indicators of the quantity of source in a language is the number of people making a living working on software written in the language. Job adverts are a proxy for the number of people employed to write/support programs implemented in a language (i.e., number of times a language is specified in the text of an advert), another proxy used to be the financial wellbeing of compiler vendors (many years ago, Open source compilers drove most companies out of the business of selling compilers).
Current job adverts are a measure of the code that likely to be worked now and in the near future. While Cobol dominated the job adverts decades ago, it is only occasionally seen today, suggesting that a lot of Cobol source is no longer actively used.
There now exists a huge quantity of Open source, and it has permeated into all the major, and many minor, software ecosystems. As a measure of all existing source code, how representative is Open source?
The Software Heritage’s mission statement “… is to collect, preserve, and share all software that is publicly available in source code form.” With over  files, as of July 2023 it is the largest available collection of Open source, and furthermore the BigCode project has collated this source into 658 constituent languages, known the Stack version 2.
files, as of July 2023 it is the largest available collection of Open source, and furthermore the BigCode project has collated this source into 658 constituent languages, known the Stack version 2.
To be representative of all existing source code, the Stack v2 would need to contain a representative sample of source written in all the languages that have been used to implement a non-trivial quantity of code. The plot below shows the number of source files assumed to be from a given year, storage by the Software Heritage; green lines are fitted exponentials (code+data):
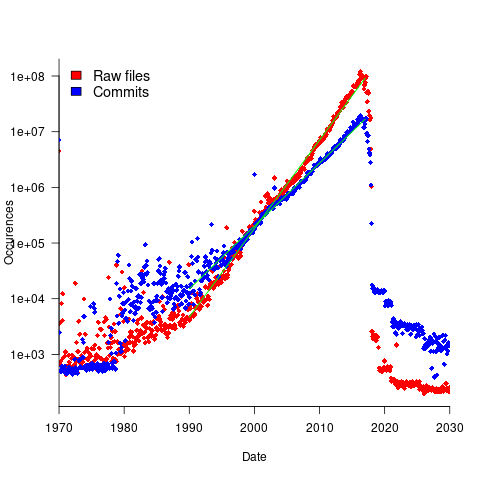
Less Open source was written in years gone by because there were fewer developers writing code, and code tends to get lost.
The Wikipedia list of programming languages currently contains links to articles on 682 languages, although some entries do appear to stretch the definition of programming language, e.g., Geometric Description Language. The Stack v2 contains code in 658 languages. However, even the broadest definition of programming language would not include some of the entries, e.g., Vim Help File. There are 176 language names shared between lists (around 27%; code+data).
Wikipedia languages not contained in Stack v2 include dialects of Basic, C, Lisp, Pascal, and shell, along with languages I recognised. Stack v2 languages not contained in the Wikipedia list include a variety of build and configuration files, names I did not recognise and what looked like documentation and data files.
Stack v2 has a broad brush approach to language classification. There is only one Pascal (perhaps the most widely used language in the early days of the IBM PC, Turbo Pascal, does not get a mention, and neither does UCSD Pascal), and assembler languages can vary a lot between cpus (Stack v2 lists: Assembly, Motorola 68K Assembly, Parrot Assembly, WebAssembly, Unix Assembly).
The Online Historical Encyclopaedia of Programming Languages lists information on 8,945 languages. Most of these probably got no further than being implemented in themselves by the language designer (often for a PhD thesis).
The Stack v2’s definition of a non-trivial quantity is at least 1,000 files having a given filename suffix, e.g., .cpp denoting C++ source. I can understand that this limit might exclude some niche languages from long ago (e.g., Coral 66), but why isn’t there any Algol 60 source?
I suspect that many ‘earlier’ languages are not included because the automated source submission process requires that the code be accessible via one of five version control systems. A lot of older source is stored in tar/zip files, accessed via ftp directories or personal web pages. Software Heritage’s Collect and Curate Legacy Code does not yet appear to provide a process for submitting source available in these forms.
While I think that Open source code has the same language usage characteristics as Closed source, I continue to meet people who question this assumption. I doubt that the question will ever get a definitive answer, not least because of an unwillingness to invest the resources needed to do a large sample comparison.
I would expect there to be at least 100 times as much Closed source as Open source, if only because there are a lot more people writing Closed source.
Obtaining source code for training LLMs
Training a large language model to be a coding assistant requires huge amounts of source code.
Github is a very well known publicly available repository of code, and various sites have created substantial collections of GitHub repos, e.g., GitTorrent, and Google’s BigQuery. Since 2017 the Software Heritage has been amassing the world’s source code, and now looks like it will become the default site for those seeking LLM source code training data. The benefits of using the Software_Heritage, include:
- deduplication at the file level for free. Files are organized using a cryptographic hash of their contents (i.e., a Merkle tree), which is user visible. GitHub may deduplicate internally, but the user visible data structure is based on individual repositories. One study found that 70% of code on GitHub are clones. Deduplication has been a major housekeeping task when creating a source code training dataset.
A single space character or newline is enough to cause a cryptographic hash to change and a file to be treated as different. Studies of file contents has found them differing by the presence/absence of a license at the start of the file, and other non-consequential differences. The LLM training dataset “The Stack v2” has further deduplicated the Software Heritage dataset, removing over 50% of files,
- accessed using AWS. The 11TiB of data can be bulk downloaded from the S3 bucket s3://softwareheritage/graph/. An Amazon Athena hosted version of the dataset can be queried using the Presto distributed SQL engine (filename suffix could be used to extract files likely to contain source in particular languages). Amazon also have an Azure Databricks hosted version.
Suggestions for the best way of accessing this data, for LLM training, welcome,
- Software_Heritage hosts more code than GitHub, although measurements from late 2021 suggests that at the time, over 95% originated on GitHub.
StarCoder2, released at the end of February, is an open weights model trained in partnership with the Software Heritage (a year ago, version 1 of StarCoder was trained using an order of magnitude less source).
How much source is available via the Software Heritage?
As of July 2023 the site hosted files.
Let’s assume 64 lines per file, and 26 non-whitespace characters per line, giving  non-whitespace characters. How many tokens is this?
non-whitespace characters. How many tokens is this?
The most common statement is assignment, which typically contains 4 language tokens (e.g., a = b ; ). There is an exponential decline in language tokens per line (Fig 770.17). The question is how many LLM tokens per computer language identifier, which tend to be abbreviated; I have no idea how these map to LLM tokens.
Assuming 10 LLM tokens per line, we get:  LLM tokens; this is 2.7 non-whitespace characters per token, which feels about right.
LLM tokens; this is 2.7 non-whitespace characters per token, which feels about right.
The Stack v2 Hugging Face page lists the deduplicated dataset as containing  tokens. However, they only include files in the main branch (the Software Heritage dataset includes files containing branches and commits), and the total number of files in the full Stack v2 dataset is
tokens. However, they only include files in the main branch (the Software Heritage dataset includes files containing branches and commits), and the total number of files in the full Stack v2 dataset is  , with the deduped training dataset containing
, with the deduped training dataset containing  files (they do not train using copyleft files, which are approximately 20-25% of the files on GitHub).
files (they do not train using copyleft files, which are approximately 20-25% of the files on GitHub).
My calculation probably overestimated the number of tokens on a line. LLM’s specifically trained on source code have tokenisers optimized for the characteristics of code, e.g., allowing tokens to span whitespace to allow for idioms such as import numpy as np to be treated as single tokens.
Given the exponential growth of files available on the Software Heritage, it is possible that several orders of magnitude more tokens will eventually become available.
Licensing, in the form of the GPL, is a complication that hangs over the use of some public source code (maybe 25%). An ongoing class-action suit will likely take years to resolve, and it’s possible that model training will have improved to the extent that any loss of GPL’d code will not seriously impact model performance:
- When source is licensed under the GNU General Public License, do models that use it during training have themselves to be released under a GPL license? In November 2022 a class-action lawsuit was filed, challenging the legality of GitHub Copilot and related OpenAI products. This case has yet to reach jury trial, and after that there will no doubt be appeals. The resolution is years in the future,
- if the plaintiffs win, with models trained using GPL’d code required to release the weights under a GPL license. The different source files used to build a project sometimes have different, incompatible, Open source licenses. LLM training does not require complete sets of project source files, so the presence of GPL’d source is not contagious within a project. If the same file appears with different licenses, one of which is the GPL, the simplest option may be to exclude it. One study found the GPL-3 license present under 2,871 different filenames.
Given that around 50% of GitHub repos don’t specify any license, and around 30% specify an MIT license, not using GPL’d code for training does not look like it will affect the training of general coding models. However, these models will have problems dealing with issues that require interfacing to GPL’d code.
Recent Comments