Archive
Top, must-read paper on software fault analysis
What is the top, must read, paper on software fault analysis?
Software Reliability: Repetitive Run Experimentation and Modeling by Phyllis Nagel and James Skrivan is my choice (it’s actually a report, rather than a paper). Not only is this report full of interesting ideas and data, but it has multiple replications. Replication of experiments in software engineering is very rare; this work was replicated by the original authors, plus Scholz, and then replicated by Janet Dunham and John Pierce, and then again by Dunham and Lauterbach!
I suspect that most readers have never heard of this work, or of Phyllis Nagel or James Skrivan (I hadn’t until I read the report). Being published is rarely enough for work to become well-known, the authors need to proactively advertise the work. Nagel, Dunham & co worked in industry and so did not have any students to promote their work and did not spend time on the academic seminar circuit. Given enough effort it’s possible for even minor work to become widely known.
The study run by Nagel and Skrivan first had three experienced developers independently implement the same specification. Each of these three implementations was then tested, multiple times. The iteration sequence was: 1) run program until fault experienced, 2) fix fault, 3) if less than five faults experienced, goto step (1). The measurements recorded were fault identity and the number of inputs processed before the fault was experienced.
This process was repeated 50 times, always starting with the original (uncorrected) implementation; the replications varied this, along with the number of inputs used.
For a fault to be experienced, there has to be a mistake in the code and the ‘right’ input values have to be processed.
How many input values need to be processed, on average, before a particular fault is experienced? Does the average number of inputs values needed for a fault experience vary between faults, and if so by how much?
The plot below (code+data) shows the numbers of inputs processed, by one of the implementations, before individual faults were experienced, over 50 runs (sorted by number of inputs):
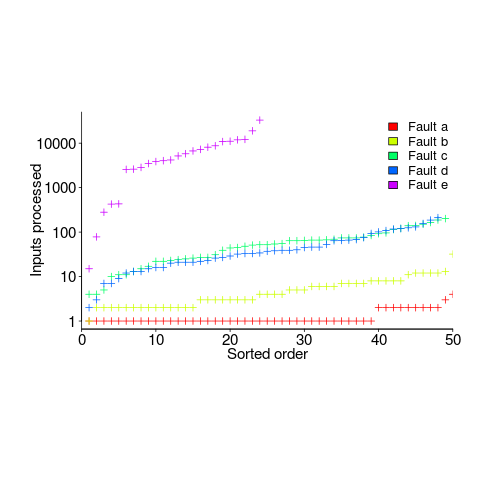
Different faults have different probabilities of being experienced, with fault a being experienced on almost any input and fault e occurring much less frequently (a pattern seen in the replications). There is an order of magnitude variation in the number of inputs processed before particular faults are experienced (this pattern is seen in the replications).
Faults were fixed as soon as they were experienced, so the technique for estimating the total number of distinct faults, discussed in a previous post, cannot be used.
A plot of number of faults found against number of inputs processed is another possibility. More on that another time.
Suggestions for top, must read, paper on software faults, welcome (be warned, I think that most published fault research is a waste of time).
Software Reliability: Lots of detailed data and thoughtful analysis
The 1978 book “Software Reliability” by Thayer, Lipow and Nelson is the only wide-ranging publicly available source of detailed software development project data that I am aware of. While analysis of Open Source, which started around 10 years ago, has added much more detail in some areas it has added almost nothing in other areas (e.g., manpower and requirements data). The analysis in this book is also very thorough, making good use of the statistical techniques available back in the day.
A few weeks ago I found an online pdf of the report from which the book is very closely derived. Anyone interested in software engineering should read this report, I’m not sure much of the state of the art has progressed that much since its publication in 1976.
The pdf was created from a microfiche copy of the original document and the numbers in some tables are illegible. I have photographed, in my copy of the book, the tables containing numbers printed using a small point size and you can download the jpegs (I don’t have the time to transcribe them to ascii text; please let me know if you do this).
Why did this book/report rapidly disappear into almost total obscurity? Perhaps it contained too much data and did too good a job of analysing it, compared to what came soon after it. Perhaps because it did not have a champion to sing its praises (wanting to build a personal career can have benefits for those other than the person doing the building).
Ethereum: Is it cost effective to create reliable contracts?
The idea of embedding of a virtual machine supporting user executable code inside a cryptocurrency continues to fascinate me. I attended the Ethereum workshop on using Solidity to develop dapps (distributed apps) yesterday.
Solidity seems to have been settled on as the high-level language in which programs for the EVM (Ethereum Virtual Machine) will be written, at least at launch. While Ethereum appear to know what they are doing in the design of the cryptocurrency (at least to my non-expert eyes), they are rank amateurs at language design. A good place to start learning is the rationales for Ada, Eiffel and Frink for starters.
Ethereum uses the term Contracts to describe programs executed by the EVM.
Anybody publishing a Contract that involves transferring something that has a real-world impact on their financial state (e.g., funds in cryptocurrency that are exchangeable for government backed currency) will want a high degree of confidence in the reliability of the code.
It is easy to imagine that people will be actively reverse engineering all published Contracts looking for flaws that can be exploited to siphon off funds into their personal accounts.
Writing high reliability code is time consuming and expensive. One way of reducing time/cost is to use a language that implicitly performs lots of checking, rather than requiring the developer to insert lots of explicit checks.
The following is an example of a variable definition providing information to the compiler that can be used to insert checks in the generated code (e.g., that no value outside the range 1 to 1000 is assigned to amount_to_pay); the developer does to not need to worry about explicitly adding checks in all the necessary places. This language functionality was invented in 1970 (in Pascal) but went out of fashion, for new languages, in the 1990s.
var amount_to_pay : 1..1000;
Languages such as Ada and Frink improve program reliability by providing functionality that reduces the effort developers need to invest in checking for unintended behavior.
Whatever language the code is written in, what happens if an attempt is made to assign 1001 to amount_to_pay? It does not matter whether the check is implicit or explicit, an error has occurred and has to be handled. As a developer of this code I want to know about the error (so I can fix it) and as a user of the code I do not want to lose money for executing a failed transaction.
At the moment the only Ethereum error handling solution I can think of is writing error information to the blockchain (in place of the information that would have been written on successful program execution); the user will still get charged for executing the program but at least will now have the evidence needed to obtain a refund (the user has to be charged to prevent denial of service attacks using Contracts containing a known fault).
I wonder who will find it worthwhile investing in creating the high reliability code needed for Contracts to be a viable solution to a problem?
Unreliable cpus and memory: The end result of Moore’s law?
Where is the evolution of commodity cpu and memory chips going to take its customers? I think the answer is cheap and unreliable products (just like many household appliances are priced low and have a short expected lifetime).
We have had the manufacturer-customer win-win phase of Moore’s law and I think we are now entering the win-loose phase.
The reason chip manufacturers, such as Intel, invest so heavily on continually shrinking dies is the same reason all companies invest, they expect to get a good return on their investment. The cost of processing the wafer from which individual chips are cut is more or less constant, reducing the size of a chip enables more to fitted on the same wafer, giving more product to sell for more or less the same wafer processing cost.
The fact that dies with smaller feature sizes have reduce power consumption and can run at faster clock speeds (up until around 10 years ago) is a secondary benefit to manufacturers (it created a reason for customers to replace what they already owned with a newer product); chip manufacturers would still have gone down the die shrink path if these secondary benefits had not existed, but perhaps at a slower rate. Customers saw, or were marketed, this strinkage story as one of product improvement for their benefit rather than as one of unit cost reduction for Intel’s benefit (Intel is the end-customer facing company that pumped billions into marketing).
Until recently both manufacturer and customer have benefited from die shrinks through faster cpus/lower power consumption and lower unit cost.
A problem that was rarely encountered outside of science fiction a few decades ago is now regularly encountered by all owners of modern computers, cosmic rays (plus more local source of ‘rays’) altering the behavior of running programs (4 GB of RAM is likely to experience a single bit-flip once every 33 hours of operation). As die shrink continues this problem will get worse. Another problem with ever smaller transistors is their decreasing mean time to failure (very technical details); we have seen expected chip lifetimes drop from 10 years to 7 and now less and decreasing.
Decreasing chip lifetimes is actually good for the manufacturer, it creates a reason for customers to buy a new product. Buying a new computer every 2-3 years has been accepted practice for many years (because the new ones were much better). Are we, the customer, in danger of being led to continue with this ‘accepted practice’ (because computers reliability is poor)?
Surely it is to the customer’s advantage to not buy devices that contain chips with even smaller features? Is it only the manufacturer that will obtain a worthwhile benefit from future die shrinks?
Estimating the reliability of compiler subcomponent
Compiler stress testing can be used for more than finding bugs in compilers, it can also be used to obtain information about the reliability of individual components of a compiler. A recent blog post by John Regehr, lead investigator for the Csmith project, covered a proposal to improve an often overlooked aspect of automated compiler stress testing (removing non-essential code from a failing test case so it is small enough to be acceptable in a bug report; attaching 500 lines of source to a report in a sure fire way for it to be ignored) triggered this post. I hope that John’s proposal is funded and it would be great if the researchers involved also received funding to investigate component reliability using the data they obtain.
One process for estimating the reliability of the components of a compiler, or any other program, is:
- divide the compiler into a set of subcomponents. These components might be a collection of source files obtained through cluster analysis of the source, obtained from a functional analysis of the implementation documents or some other means,
- count the number of times each component executes correctly and incorrectly (this requires associating bugs with components by tracing bug fixes to the changes they induce in source files; obtaining this information will consume the largest amount of the human powered work) while processing lots of source. The ratio of these two numbers, for a given component, is an estimate of the reliability of that component.
How important is one component to the overall reliability of the whole compiler? This question can be answered if the set of components is treated as a Markov chain and the component transition probabilities are obtained using runtime profiling (see Large Empirical Case Study of Architecture–based Software Reliability by Goševa-Popstojanova, Hamill and Perugupalli for a detailed discussion).
Reliability is a important factor in developers’ willingness to enable some optimizations. Information from a component reliability analysis could be used to support an option that only enabled optimization components having a reliability greater than a developer supplied value.
The one big threat to validity of this approach is that stress tests are not representative of typical code. One possibility is to profile the compiler processing lots of source (say of the order of a common Linux distribution) and merge the transition probabilities, probably weighted, to those obtained from stress tests.
Recent Comments