Archive
Deciding whether a conclusion is possible or necessary
Psychologists studying human reasoning have primarily focused on syllogistic reasoning, i.e., the truthfulness of a necessary conclusion from two stated premises, as in the following famous example:
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal. |
Another form of reasoning is modal reasoning, which deals with possibilities and necessities; for example:
All programmers like jelly beans,
Tom likes jelly beans,
Therefore, it is possible Tom is a programmer. |
Possibilities and necessities are fundamental to creating software. I would argue (without evidence) that possibility situations occur much more frequently during software development than necessarily situations.
What is the coding impact of incorrect Possible/Necessary decisions (the believability of a syllogism has been found to influence subject performance)?
- Conclusion treated as possible, while being necessary: A possibility involves two states, while necessity is a single state. A possible condition implies coding an
if/else(or perhaps one arm of anif), while a necessary condition is at most one arm of anif(or perhaps nothing).The likely end result of making this incorrect decision is some dead code.
- Conclusion treated as necessary, while being possible: Here two states are considered to be a single state.
The likely end result of making this incorrect decision is incorrect code.
What have the psychology studies found?
The 1999 paper: Reasoning About Necessity and Possibility: A Test of the Mental Model Theory of Deduction by J. St. B. T. Evans, S. J. Handley, C. N. J. Harper, and P. N. Johnson-Laird, experimentally studied three predictions (slightly edited for readability):
- People are more willing to endorse conclusions as Possible than as Necessary.
- It is easier to decide that a conclusion is Possible if it is also Necessary. Specifically, we predict more endorsements of Possible for Necessary than for Possible problems.
- It is easier to decide that a conclusion is not Necessary if it is also not Possible. Specifically, we predict that more Possible than Impossible problems will be endorsed as Necessary.
Less effort is required to decide that a conclusion is Possible because just one case needs to be found, while making a Necessary decision requires evaluating all cases.
In one experiment, subjects (120 undergraduates studying psychology) saw a screen containing a question such as the following (an equal number of questions involved NECESSARY/POSSIBLE):
GIVEN THAT
Some A are B
IS IT NECESSARY THAT
Some B are not A |
Subjects saw each of the 28 possible combinations of four Premises and seven Conclusions. The table below shows eight combinations of the four Premises and seven conclusions, the Logic column shows the answer (N=Necessary; I=Impossible; P=Possible), and the Necessary/Possible columns show the number of subjects answering that the conclusion was Necessary/Possible:
Premise Conclusion Logic Necessary Possible All A are B Some A are B N 65 82 All A are B No A are B I 3 12 Some A are B All A are B P 3 53 Some A are B No A are B I 8 55 No A are B Some A are not B N 77 80 No A are B No B are A I 7 25 Some A are not B All A are B I 2 3 Some A are not B Some B are A P 70 95 |
The table below shows the percentage of answer specifying that the conclusion was Necessary/Possible (2nd/3rd rows), when the Logical answer was one of Impossible/Necessary/Possible (code+data):
Logic I N P
N 8% 59% 38%
P 19% 71% 60% |
The percentage of Possible answers is always much higher than Necessary answers (when a Conclusion is Necessary, it is also Possible), even when the Conclusion is Impossible. The 38% of Necessary answers for when the Conclusion is only Possible is somewhat concerning, as this decision could produce coding mistakes.
The paper ran a second experiment involving two premises, like the Jelly bean example, attempting to distinguish strong/weak forms of Possible.
Do these results replicate?
The 2024 study Necessity, Possibility and Likelihood in Syllogistic Reasoning by D. Brand, S. Todorovikj, and M. Ragni, replicated the results. This study also investigated the effect of using Likely, as well as Possible/Necessary. The results showed that responses for Likely suggested it was a middle ground between Possible/Necessary.
After writing the above, I asked Grok: list papers that have studied the use of syllogistic reasoning by software developers: nothing software specific. The same question for modal reasoning returned answers on the use of Modal logic, i.e., different subject. Grok did a great job of summarising the appropriate material in my Evidence-base Software Engineering book.
Modular Reasoning, Knowledge and Language systems
The spectrum of models of the human mind run from it being a general purpose computer to it being a collection of integrated specialist modules (each performing one function, e.g., speech or language). The Modularity of mind hypothesis offers a halfway house.
ChatGPT sits at the general purpose computer end of the spectrum; there is a single ‘processor’ that accepts a particular kind of input and produces a particular kind of output.
While predict-the-next-token systems like ChatGTP have proven to be good at analysing and constructing sentences, they are often unable to carry out the actions described by these sentences; for instance, they are capable of describing mathematical operations that they are incapable of performing (unless the answer happens to be in their training).
A Modular Reasoning, Knowledge and Language system (MRKL; the suggested pronunciation is miracle), is, as the name suggests, a system built from specialist modules. In this approach, a large language model (LLM), such as ChatGTP, is the language processing module.
In a MRKL system, the input is processed (by an LLM) to figure out which specialist modules have to be queried to obtain the information needed to answer the question, the appropriate text (generated by an LLM) is fed as input to the corresponding modules, and the module outputs are collected and fed to an LLM to generate an answer to the question.
A user question may involve querying multiple modules in some sequence. For instance, the question “What is the average age of the last five British Prime ministers?” might involve querying Google/Alexa answers to obtain a list of previous Prime ministers, followed by extracting individual ages from Wikipedia, followed by querying a maths module to obtain the average of the five ages obtained.
The extent to which an application using an LLM might be said to be a MRKL system is a matter of degree. The following shell script is unlikely to qualify:
curl https://api.openai.com/v1/completions \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer '{$OPENAI_API_KEY} \
-d '{
"model": "text-davinci-003",
"prompt": "Say I found The Shape of Code to be an interesting blog",
"temperature": 0
}' |
The OpenAI API focuses on how to drive their various language models, along with lots of examples. There is no API offering a higher level abstraction or functionality.
An API designed for building MRKL systems, that is starting to gain traction, is langchain; a collection of Python packages, with JavaScript libraries playing catchup.
langchain Module categories include: LLM interaction (e.g., specifying which LLM to use, API keys, and changing default values), document loaders (e.g., readers for pdf, HTML, Gitbook, and Microsoft Word), Agents (these use an LLM to process the input text to find out what actions need to be performed, and to create the input actions that the selected modules need to perform), Memory (store information from previous interactions; other modules can be stateless), and Chat (handle the mechanics of holding a conversation).
What does langchain offer that is making it attractive to a growing number of developers?
- Making use of an LLM within an application will involve some subset of the functionality provided by langchain. The advantage of using langchain is that it provides a framework, MRKL, along with a (sometimes skeleton) existing implementation,
- first mover advantage for an Open source implementation has enabled langchain to attract a growing number of active contributors; it also helps that the core developers have been making regular updates (almost daily), and half-decent documentation is available.
Given the current volume of discussion around LLMs, why has there been so little written about MRKL systems?
Building a MRKL system requires coding ability, and developers are a small percentage of those contributing to the discussion avalanche.
Building a MRML system takes a lot of time and work. Being able to break down a question into subcomponents that can be answered by the available modules, and sequencing them appropriately is a non-trivial problem.
Once Apps solving real-world problems start becoming widely used, and the novelty of generic chat systems wears off, the discussion will switch to more grounded issues.
Human reasoning is generally not logic based
From around 350 BC until the 1960s, the students were taught that people reasoned using logic, and teachers believed this to be true. In the 1960s psychologists started running experiments that asked subjects to solve reasoning problems, the results showed that people often failed to give the answers dictated by logic.
Some recurring patterns were present in the answers given, and small changes in the wording of the question asked were found to produce different answer patterns. Very few researchers were willing to give up the idea that subjects were reasoning using logic, there must be another explanation, e.g., subjects must be interpreting the experimental questions asked in a way that differed from that assumed by the researchers. The social context of reasoning was one of the early drivers of evolutionary psychology; reasoning must provide some survival benefit by solving problems that regularly occur in natural human environments.
After a myriad of detailed theories did little more than predict small subsets of subject responses, mainstream reasoning research finally gave up the belief that logic is the default technique used by people to solve reasoning problems. Theories of reasoning behavior are now based around people estimating probabilities and picking the answer with the highest probability; this approach does a much better job of predicting common patterns in subject answers.
Experimental studies of reasoning often use psychology undergraduates as subjects (the historical norm, with Mechanical Turk workers becoming more common). While researchers may be concerned about how well undergraduate behavior mimics the general population, my concern is the extent to which these results apply to software developers. Is a necessary condition for being a professional software developer that a person, by default, uses logic to solve reasoning problems?
Of course, software developers claim that their reasoning is logic based, but then so do people in the general population (or at least the non-developers I interact with do). The dual-process theory of reasoning contains two reasoning systems, one unconscious/intuitive and the second a conscious/deliberate system; it has been said that the purpose of the second system is to come up with reasons to justify the answers produced by the first system.
Until reasoning experiments are run with professional developer subjects, we won’t know the extent to which existing results in reasoning research apply to this specialist subset of the population.
The Wason selection task is to studies of reasoning, like the fruit fly is to studies of genetics. What pattern of behavior do you show on this task (code)?
The plot below shows a set of four cards, of which you can see only the exposed face but not the hidden back. On each card, there is a number on one side and a letter on the other.
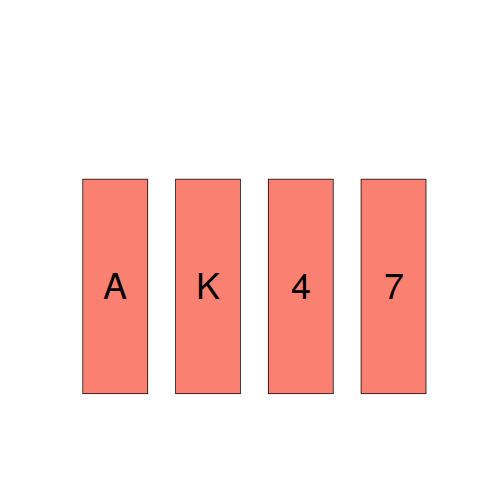
- Given the statement: “If there is a vowel on one side, then there is an even number on the other side.”
Your task is to decide, which, if any, of these four cards must be turned over to decide whether this statement is true. - Specify the cards you would turn over. Don’t turn unnecessary cards.
————————————
Most people correct specify that the card showing a vowel must be turned over to verify that an even number appears on the other side. A common mistake is to specify that the card showing an even number also has to be turned over. However, there is no requirement on the letter appearing on the other side of a card showing an even number. A second necessary condition involves a negative test (something that developers are known to overlook); for the statement to hold, a vowel must not appear on the other side of the card showing an odd number, this is the second card that must be turned over.
Some human biases in conditional reasoning
Tracking down coding mistakes is a common developer activity (for which training is rarely provided).
Debugging code involves reasoning about differences between the actual and expected output produced by particular program input. The goal is to figure out the coding mistake, or at least narrow down the portion of code likely to contain the mistake.
Interest in human reasoning dates back to at least ancient Greece, e.g., Aristotle and his syllogisms. The study of the psychology of reasoning is very recent; the field was essentially kick-started in 1966 by the surprising results of the Wason selection task.
Debugging involves a form of deductive reasoning known as conditional reasoning. The simplest form of conditional reasoning involves an input that can take one of two states, along with an output that can take one of two states. Using coding notation, this might be written as:
if (p) then q if (p) then !q if (!p) then q if (!p) then !q |
The notation used by the researchers who run these studies is a 2×2 contingency table (or conditional matrix):
OUTPUT
1 0
1 A B
INPUT
0 C D |
where: A, B, C, and D are the number of occurrences of each case; in code notation, p is the input and q the output.
The fertilizer-plant problem is an example of the kind of scenario subjects answer questions about in studies. Subjects are told that a horticultural laboratory is testing the effectiveness of 31 fertilizers on the flowering of plants; they are told the number of plants that flowered when given fertilizer (A), the number that did not flower when given fertilizer (B), the number that flowered when not given fertilizer (C), and the number that did not flower when not given any fertilizer (D). They are then asked to evaluate the effectiveness of the fertilizer on plant flowering. After the experiment, subjects are asked about any strategies they used to make judgments.
Needless to say, subjects do not make use of the available information in a way that researchers consider to be optimal, e.g., Allan’s  index
index -P(B vert D)=A/{A+B}-C/{C+D}") (sorry about the double,
(sorry about the double,  , rather than single, vertical lines).
, rather than single, vertical lines).
What do we know after 40+ years of active research into this basic form of conditional reasoning?
The results consistently find, for this and other problems, that the information A is given more weight than B, which is given by weight than C, which is given more weight than D.
That information provided by A and B is given more weight than C and D is an example of a positive test strategy, a well-known human characteristic.
Various models have been proposed to ‘explain’ the relative ordering of information weighting: gtw(B) gt w(C) gt w(D)") , e.g., that subjects have a bias towards sufficiency information compared to necessary information.
, e.g., that subjects have a bias towards sufficiency information compared to necessary information.
Subjects do not always analyse separate contingency tables in isolation. The term blocking is given to the situation where the predictive strength of one input is influenced by the predictive strength of another input (this process is sometimes known as the cue competition effect). Debugging is an evolutionary process, often involving multiple test inputs. I’m sure readers will be familiar with the situation where the output behavior from one input motivates a misinterpretation of the behaviour produced by a different input.
The use of logical inference is a commonly used approach to the debugging process (my suggestions that a statistical approach may at times be more effective tend to attract odd looks). Early studies of contingency reasoning were dominated by statistical models, with inferential models appearing later.
Debugging also involves causal reasoning, i.e., searching for the coding mistake that is causing the current output to be different from that expected. False beliefs about causal relationships can be a huge waste of developer time, and research on the illusion of causality investigates, among other things, how human interpretation of the information contained in contingency tables can be ‘de-biased’.
The apparently simple problem of human conditional reasoning over two variables, each having two states, has proven to be a surprisingly difficult to model. It is tempting to think that the performance of professional software developers would be closer to the ideal, compared to the typical experimental subject (e.g., psychology undergraduates or Mturk workers), but I’m not sure whether I would put money on it.
The impact of believability on reasoning performance
What are the processes involved in reasoning? While philosophers have been thinking about this question for several thousand years, psychologists have been running human reasoning experiments for less than a hundred years (things took off in the late 1960s with the Wason selection task).
Reasoning is a crucial ability for software developers, and I thought that there would be lots to learn from the cognitive psychologists research into reasoning. After buying all the books, and reading lots of papers, I realised that the subject was mostly convoluted rabbit holes individually constructed by tiny groups of researchers. The field of decision-making is where those psychologists interested in reasoning, and a connection to reality, hang-out.
Is there anything that can be learned from research into human reasoning (other than that different people appear to use different techniques, and some problems are more likely to involve particular techniques)?
A consistent result from experiments involving syllogistic reasoning is that subjects are more likely to agree that a conclusion they find believable follows from the premise (and are more likely to disagree with a conclusion they find unbelievable). The following is perhaps the most famous syllogism (the first two lines are known as the premise, and the last line is the conclusion):
All men are mortal.
Socrates is a man.
Therefore, Socrates is mortal. |
Would anybody other than a classically trained scholar consider that a form of logic invented by Aristotle provides a reasonable basis for evaluating reasoning performance?
Given the importance of reasoning ability in software development, there ought to be some selection pressure on those who regularly write software, e.g., software developers ought to give a higher percentage of correct answers to reasoning problems than the general population. If the selection pressure for reasoning ability is not that great, at least software developers have had a lot more experience solving this kind of problem, and practice should improve performance.
The subjects in most psychology experiments are psychology undergraduates studying in the department of the researcher running the experiment, i.e., not the general population. Psychology is a numerate discipline, or at least the components I have read up on have a numeric orientation, and I have met a fair few psychology researchers who are decent programmers. Psychology undergraduates must have an above general-population performance on syllogism problems, but better than professional developers? I don’t think so, but then I may be biased.
A study by Winiger, Singmann, and Kellen asked subjects to specify whether the conclusion of a syllogism was valid/invalid/don’t know. The syllogisms used were some combination of valid/invalid and believable/unbelievable; examples below:
Believable Unbelievable
Valid
No oaks are jubs. No trees are punds.
Some trees are jubs. Some Oaks are punds.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees.
Invalid
No tree are brops. No oaks are foins.
Some oaks are brops. Some trees are foins.
Therefore, some trees Therefore, some oaks
are not oaks. are not trees. |
The experiment was run using an online crowdsource site, and 354 data sets were obtained.
The plot below shows the impact of conclusion believability (red)/unbelievability (blue/green) on subject performance, when deciding whether a syllogism was valid (left) or invalid (right), (code+data):
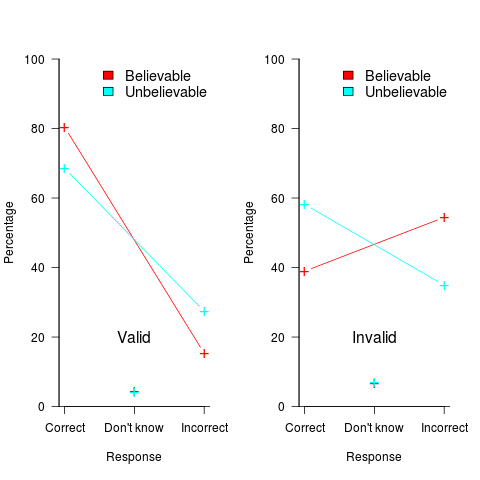
The believability of the conclusion biases the responses away/towards the correct answer (the error bars are tiny, and have not been plotted). Building a regression model puts numbers to the difference, and information on the kind of premise can also be included in the model.
Do professional developers exhibit such a large response bias (I would expect their average performance to be better)?
People tend to write fewer negative tests, than positive tests. Is this behavior related to the believability that certain negative events can occur?
Believability is an underappreciated coding issue.
Hopefully people will start doing experiments to investigate this issue 🙂
Recent Comments