Archive
Cognitive effort, whatever it might be
Software developers spend a lot of time acquiring knowledge and understanding of the software system they are working on. This mental activity fits within the field of Cognition, which covers all aspects of intellectual functions and processes. Human cognition as it related to software development is covered in chapter 2 of my book Evidence-based software engineering; a reading list.
Cognitive effort (e.g., thinking) is hard work, or at least mental effort feels like hard work. It has become fashionable for those extolling the virtues of some development technique/process to claim that one of its benefits is a reduction in cognitive effort; sometimes the term cognitive load is used, but I suspect this is not a reference to cognitive load theory (which is working memory based).
A study by Arai, with herself as the subject, measured the time taken to mentally multiply two four-digit values (e.g., 2,645 times 5,784). Over 2-weeks, Arai practiced on four days, on each day multiplying over 20 four-digit value pairs. A week later Arai multiplied 40 four-digit value pairs (starting at 1:45pm, finishing at 6:31pm), had dinner between 6:31-7:41 pm, and then, multiplied 20 four-digit value pairs (starting at 7:41, finishing at 10:07). The plot below shows the time taken for each mental multiplication sequence, with fitted regression lines (code+data):
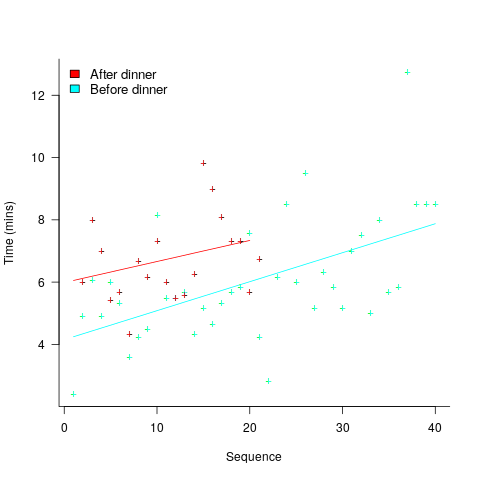
Over the course of the first, 5-hour session, average time taken slowed from four to eight minutes. The slope of the regression fit for the second session is poor, although the fit for the start value (6 minutes) is good.
The average increase in time taken is assumed to be driven by a reduction in mental effort, caused by the mental fatigue experienced during an extended period of continuous mental work.
What do we know about cognitive effort?
TL;DR Many theories and little evidence.
Cognitive psychologists are still at the stage of figuring out what exactly cognitive effort is. For instance, what is going on when we try harder (or decide to give up), and what is being conserved when we conserve our mental resources? The major theories include:
- Cognitive control: Mental processes form a continuum, from those that can be performed automatically with little or no effort, to those requiring concentrated conscious effort. Here, cognitive control is viewed as the force through which cognitive effort is exerted. The idea is that mental effort regulates the engagement of cognitive control in the same way as physical effort regulates the engagement of muscles.
- Metabolic constraints: Mental processes consume energy (glucose is the brain’s primary energy source), and the feeling of mental effort is caused by reduced levels of glucose. The extent to which mental effort is constrained by glucose levels is an ongoing debate.
- Capacity constraints: Working memory has a limited capacity (i.e., the oft quoted 7±2 limit), and tasks that fill this capacity do feel effortful. Cognitive load theory is based around this idea. A capacity limited working memory, as a basis of cognitive effort, suffers from the problem that people become mentally tired in the sense that later tasks feel like they require more effort. A capacity constrained model does not predict this behavior. Neither does a constraints model predict that increasing rewards can result in people exerting more cognitive effort.
How might cognitive effort be measured?
TL;DR It’s all relative or not at all.
To date, experiments have compared relative expenditure of effort between different tasks (some comparing cognitive with physical effort, other purely cognitive). For instance, showing that subjects are willing to perform a task requiring more cognitive effort when the expected reward is higher.
As always with human experiments, people can have very different behavioral characteristics. In particular, people differ in what is known as need for cognition, i.e., their willingness to invest cognitive effort.
While a lot of research has investigated the characteristics of working memory, the only real metric studied has been capacity, e.g., the longest sequence of digits that can be remembered/recalled, or span tasks involving having to remember words while performing simple arithmetic operations.
Experimental research on cognitive effort seems to be picking up, but don’t hold your breadth for reliable answers. Research of human characteristics can start out looking straight forward, but tends to quickly disappear down multiple, inconclusive rabbit holes.
The Weirdest people in the world
Western, Educated, Industrialized, Rich and Democratic: WEIRD people are the subject of Joseph Henrich’s latest book “The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous”.
This book is in the mold of Jared Diamond’s Guns, Germs, and Steel: The Fates of Human Societies, but comes at the topic from a psychological/sociological angle.
This very readable book is essential reading for anyone wanting to understand how very different WEIRD people are, along with the societies they have created, compared to people and societies in the rest of the world today and the entire world up until around 500 years ago.
The analysis of WEIRD people/societies has three components: why we are different (I’m assuming that most of this blog’s readers are WEIRD), the important differences that are known about, and the cultural/societal consequences (the particularly prosperous in the subtitle is a big clue).
Henrich cites data to back up his theories.
Starting around 1,500 years ago the Catholic church started enforcing a ban on cousin marriage, which was an almost universal practice at the time and is still widely practiced in non-WEIRD societies. Over time the rules got stricter, until by the 11th century people were not allowed to marry anyone related out to their sixth cousin. The rules were not always strictly enforced, as Henrich documents, but the effect was to change the organization of society from being kin-based to being institution-based (in particular institutions such as the Church and state). Finding a wife/husband required people to interact with others outside their extended family.
Effects claimed, operating over centuries, of the shift from extended families to nuclear families are that people learned what Henrich calls “impersonal prosociality”, e.g., feeling comfortable dealing with strangers. People became more altruistic, the impartial rule of law spread (including democracy and human rights), plus other behaviors needed for the smooth running of large social units (such as towns, cities and countries).
The overall impact was that social units of WEIRD people could grow to include tens of thousands, even millions, or people, and successfully operate at this scale. Information about beneficial inventions could diffuse rapidly and people were free(ish) to try out new things (i.e., they were not held back by family customs), and operating in a society with free movement of people there were lots of efficiencies, e.g., companies were not obligated to hire family members, and could hire the best person they could find.
Consequently, the West got to take full advantage of scientific progress, invent and mass produce stuff. Outcompeting the non-WEIRD world.
The big ideas kind of hang together. Some of the details seem like a bit of a stretch, but I’m no expert.
My WEIRD story occurred about five years ago, when I was looking for a publisher for the book I was working on. One interested editor sent out an early draft for review. One of the chapters discusses human cognition, and I pointed out that it did not matter that most psychology experiments had been done using WEIRD subjects, because software developers were WEIRD (citing Henrich’s 2010 WEIRD paper). This discussion of WEIRD people was just too much for one of the reviewers, who sounded like he was foaming at the mouth when reviewing my draft (I also said a few things about academic researchers that upset him).
Experimental Psychology by Robert S. Woodworth
I have just discovered “Experimental Psychology” by Robert S. Woodworth; first published in 1938, I have a reprinted in Great Britain copy from 1951. The Internet Archive has a copy of the 1954 revised edition; it’s a very useful pdf, but it does not have the atmospheric musty smell of an old book.
The Archives of Psychology was edited by Woodworth and contain reports of what look like ground breaking studies done in the 1930s.
The book is surprisingly modern, in that the topics covered are all of active interest today, in fields related to cognitive psychology. There are lots of experimental results (which always biases me towards really liking a book) and the coverage is extensive.
The history of cognitive psychology, as I understood it until this week, was early researchers asking questions, doing introspection and sometimes running experiments in the late 1800s and early 1900s (e.g., Wundt and Ebbinghaus), behaviorism dominants the field, behaviorism is eviscerated by Chomsky in the 1960s and cognitive psychology as we know it today takes off.
Now I know that lots of interesting and relevant experiments were being done in the 1920s and 1930s.
What is missing from this book? The most obvious omission is equations; lots of data points plotted on graph paper, but no attempt to fit an equation to anything, e.g., an exponential curve to the rate of learning.
A more subtle omission is the world view; digital computers had not been invented yet and Shannon’s information theory was almost 20 years in the future. Researchers tend to be heavily influenced by the tools they use and the zeitgeist. Computers as calculators and information processors could not be used as the basis for models of the human mind; they had not been invented yet.
Relative spacing of operands affects perception of operator precedence
What I found most intriguing about Google Code Search (shutdown Nov 2011) was how quickly searches involving regular expressions returned matches. A few days ago Russ Cox, the implementor of Code Search not only explained how it worked but also released the source and some precompiled binaries. Google’s database of source code did not include the source of R, so I decided to install CodeSearch on my local machine and run some of my previous searches against the latest (v2.14.1) R source.
In 2007 I ran an experiment that showed developers made use of variable names when making binary operator precedence decisions. At about the same time two cognitive psychologists, David Landy and Robert Goldstone, were investigating the impact of spacing on operator precedence decisions (they found that readers showed a tendency to pair together the operands that were visibly closer to each other, e.g., a with b in a+b * c rather than b with c).
As somebody very interested in finding faults in code the psychologists research findings on spacing immediately suggested to me the possibility that ‘incorrectly’ spaced expressions were a sign of failure to write code that had the intended behavior. Feeding some rather complicated regular expressions into Google’s CodeSearch threw up a number of ‘incorrectly’ spaced expressions. However, this finding went no further than an interesting email exchange with Landy and Goldstone.
Time to find out whether there are any ‘incorrectly’ spaced expressions in the R source. cindex (the tool that builds the database used by csearch) took 3 seconds on a not very fast machine to process all of the R source (56M byte) and build the search database (10M byte; the Linux database is a factor of 5.5 smaller than the sources).
The search:
csearch "w(+|-)w +(*|/) +w" |
returned a few interesting matches:
... modules/internet/nanohttp.c: used += tv_save.tv_sec + 1e-6 * tv_save.tv_usec; modules/lapack/dlapack0.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack2.f: S = Z( 3 )*( Z( 2 ) / ( T*( ONE+SQRT( ONE+S / T ) ) ) ) modules/lapack/dlapack4.f: $ ( T*( ONE+SQRT( ONE+S / T ) ) ) ) |
There were around 15 matches of code like 1e-6 * var (because the pattern w is for alphanumeric sequences and that is not a superset of the syntax of floating-point literals).
The subexpression ONE+S / T is just the sort of thing I was looking for. The three instances all involved code that processed tridiagonal matrices in various special cases. Google search combined with my knowledge of numerical analysis was not up to the task of figuring out whether the intended usage was (ONE+S)/T or ONE+(S/T).
Searches based on various other combination of operator pairs failed to match anything that looked suspicious.
There was an order of magnitude performance difference for csearch vs. grep -R -e (real 0m0.167s vs. real 0m2.208s). A very worthwhile improvement when searching much larger code bases with more complicated patterns.
Christmas books for 2009
I thought it would be useful to list the books that gripped me one way or another this year (and may be last year since I don’t usually track such things closely); perhaps they will give you some ideas to add to your Christmas present wish list (please make your own suggestions in the Comments). Most of the books were published a few years ago, I maintain piles of books ordered by when I plan to read them and books migrate between piles until eventually read. Looking at the list I don’t seem to have read many good books this year, perhaps I am spending too much time reading blogs.
These books contain plenty of facts backed up by numbers and an analytic approach and are ordered by physical size.
The New Science of Strong Materials by J. E. Gordon. Ideal for train journeys since it is a small book that can be read in small chunks and is not too taxing. Offers lots of insight into those properties of various materials that are needed to build things (‘new’ here means postwar).
Europe at War 1939-1945 by Norman Davies. A fascinating analysis of the war from a numbers perspective. It is hard to escape the conclusion that in the grand scheme of things us plucky Brits made a rather small contribution, although subsequent Hollywood output has suggested otherwise. Also a contender for a train book.
Japanese English language and culture contact by James Stanlaw. If you are into Japanese culture you will love this, otherwise avoid.
Evolutionary Dynamics by Martin A. Nowak. For the more mathematical folk and plenty of thought power needed. Some very powerful general results from simple processes.
Analytic Combinatorics by Philippe Flajolet and Robert Sedgewick. Probably the toughest mathematical book I have kept at (yet to get close to the end) in a few years. If number sequences fascinate you then give it a try (a pdf is available).
Probability and Computing by Michael Mitzenmacher and Eli Upfal. For the more mathematical folk and plenty of thought power needed. Don’t let the density of Theorems put you off, the approach is broad brush. Plenty of interesting results with applications to solving problems using algorithms containing a randomizing component.
Network Algorithmics by George Varghese. A real hackers book. Not so much a book about algorithms used to solve networking problems but a book about making engineering trade-offs and using every ounce of computing functionality to solve problems having severe resource and real-time constraints.
Virtual Machines by James E. Smith and Ravi Nair. Everything you every wanted to know about virtual machines and more.
Biological Psychology by James W. Kalat. This might be a coffee table book for scientists. Great illustrations, concise explanations, the nuts and bolts of how our bodies runs at the protein/DNA level.
Recent Comments