Archive
Performance variation in 2,386 ‘identical’ processors
Every microprocessor is different, random variations in the manufacturing process result in transistors, and the connections between them, being fabricated with more/less atoms. An atom here and there makes very little difference when components are built from millions, or even thousands, of atoms. The width of the connections between transistors in modern devices might only be a dozen or so atoms, and an atom here and there can have a noticeable impact.
How does an atom here and there affect performance? Don’t all processors, of the same product, clocked at the same frequency deliver the same performance?
Yes they do, an atom here or there does not cause a processor to execute more/less instructions at a given frequency. But an atom here and there changes the thermal characteristics of processors, i.e., causes them to heat up faster/slower. High performance processors will reduce their operating frequency, or voltage, to prevent self-destruction (by overheating).
Processors operating within the same maximum power budget (say 65 Watts) may execute more/less instructions per second because they have slowed themselves down.
Some years ago I spotted a great example of ‘identical’ processor performance variation, and the author of the example, Barry Rountree, kindly sent me the data. In the weeks before Christmas I finally got around to including the data in my evidence-based software engineering book. Unfortunately I could not figure out what was what in the data (relearning an important lesson: make sure to understand the data as soon as it arrives), thankfully Barry came to the rescue and spent some time doing software archeology to figure out the data.
The original plots showed frequency/time data of 2,386 Intel Sandy Bridge XEON processors (in a high performance computer at the Lawrence Livermore National Laboratory) executing the EP benchmark (the data also includes measurements from the MG benchmark, part of the NAS Parallel benchmark) at various maximum power limits (see plot at end of post, which is normalised based on performance at 115 Watts). The plot below shows frequency/time for a maximum power of 65 Watts, along with violin plots showing the spread of processors running at a given frequency and taking a given number of seconds (my code, code+data on Barry’s github repo):
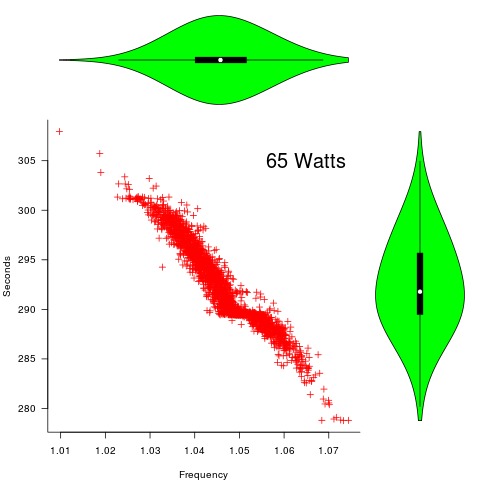
The expected frequency/time behavior is for processors to lie along a straight line running from top left to bottom right, which is roughly what happens here. I imagine (waving my software arms about) the variation in behavior comes from interactions with the other hardware devices each processor is connected to (e.g., memory, which presumably have their own temperature characteristics). Memory performance can have a big impact on benchmark performance. Some of the other maximum power limits, and benchmark, measurements have very different characteristics (see below).
More details and analysis in the paper: An empirical survey of performance and energy efficiency variation on Intel processors.
Intel’s Sandy Bridge is now around seven years old, and the number of atoms used to fabricate transistors and their connectors has shrunk and shrunk. An atom here and there is likely to produce even more variation in the performance of today’s processors.
A previous post discussed the impact of a variety of random variations on program performance.
Update start
A number of people have pointed out that I have not said anything about the impact of differences in heat dissipation (e.g., faster/slower warmer/cooler air-flow past processors).
There is some data from studies where multiple processors have been plugged, one at a time, into the same motherboard (i.e., low budget PhD research). The variation appears to be about the same as that seen here, but the sample sizes are more than two orders of magnitude smaller.
There has been some work looking at the impact of processor location (e.g., top/bottom of cabinet). No location effect was found, but this might be due to location effects not being consistent enough to show up in the stats.
Update end
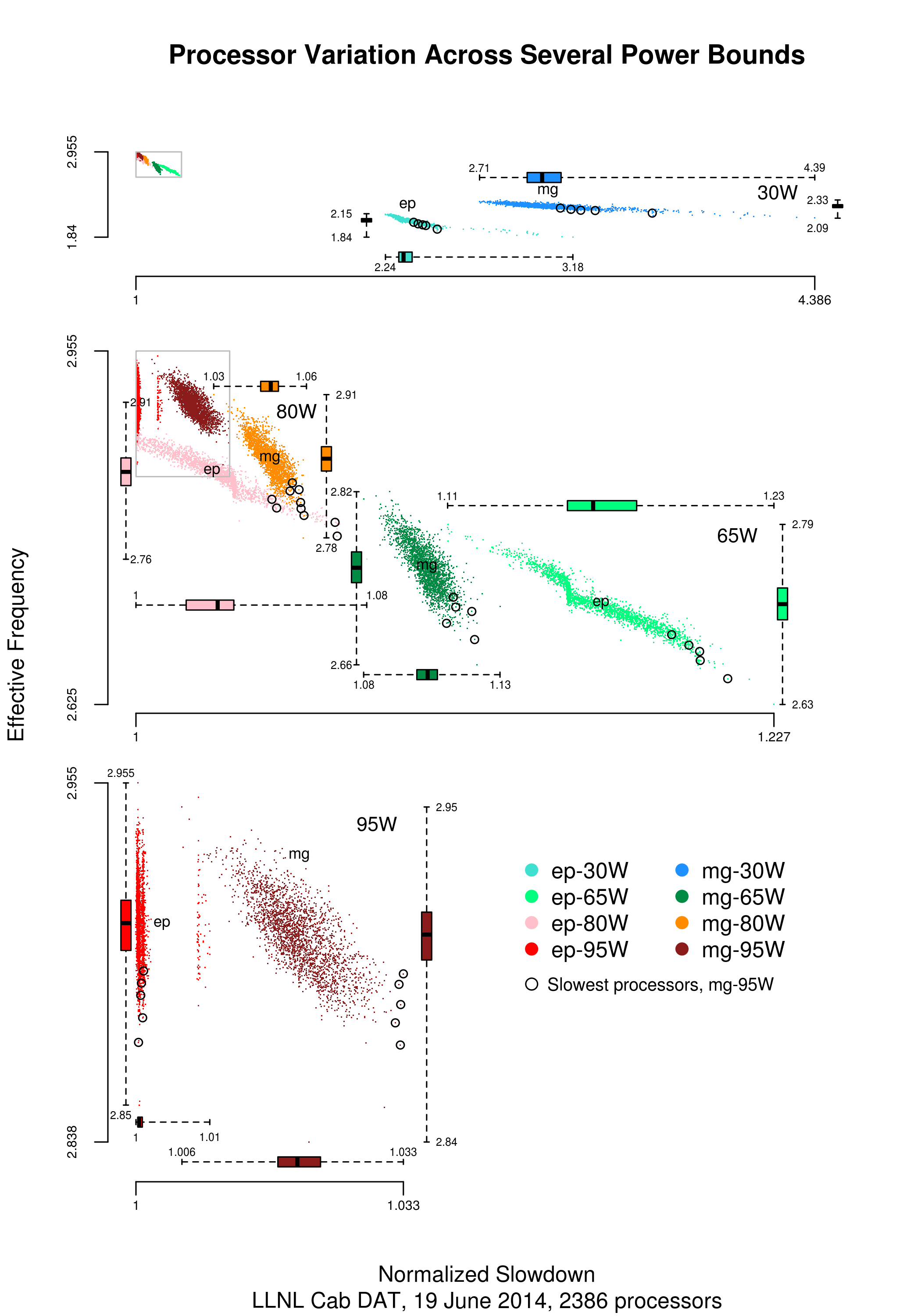
Below is a png version of the original plot I saw:
Designing a processor for increased source portability costs
How might a vendor make it difficult for developers to port open source applications to their proprietary cpu? Keeping the instruction set secret is one technique, another is to design a cpu that breaks often relied upon assumptions that developers have about the characteristics of the architecture on which their code executes.
Of course breaking architectural assumptions does not prevent open source being ported to a platform, but could significantly slow down the migration; giving more time for customers to become locked into the software shipped with the product.
Which assumptions should be broken to have the maximum impact on porting open source? The major open source applications (e.g., Firefox, MySQL, etc) run on 32/64-bit architectures that have an unsigned address space, whose integer representation uses two’s complement arithmetic and arithmetic operations on these integer values wrap on over/underflow.
32/64-bit. There is plenty of experience showing that migrating code from 16-bit to 32-bit environments can involve a lot of effort (e.g., migrating Windows 286/386 code to the Intel 486) and plenty of companies are finding the migration from 32 to 64-bits costly.
Designing a 128-bit processor might not be cost effective, but what about a 40-bit processor, like a number of high end DSP chips? I suspect that there are many power-of-2 assumptions lurking in a lot of code. A 40-bit integer type could prove very expensive for ports of code written with a 32/64-bit mindset (dare I suggest a 20-bit short; DSP vendors have preferred 16-bits because it uses less storage?).
Unsigned address space (i.e., lowest address is zero). Some code assumes that addresses with the top bit set are at the top end of memory and not just below the middle (e.g., some garbage collectors). Processors having a signed address space (i.e., zero is in the middle of storage) are sufficiently rare (e.g., the Inmos Transputer) that source is unlikely to support a HAS_SIGNED_ADDRESS build option.
How much code might need to be rewritten? I have no idea. While the code is likely to be very important there might not be a lot of it.
Two’s complement. Developers are constantly told not to write code that relies on the internal representation of data types. However, they might be forgiven for thinking that nobody uses anything other than two’s complement to represent integer types these days (I suspect Univac does not have that much new code ported to it’s range of one’s complement machines).
How much code will break when ported to a one’s complement processor? The representation of negative numbers in one’s complement and two’s complement is different and the representation of positive numbers the same. In common usage positive values are significantly more common than negative values and many variables (having a signed type) never get to hold a negative value.
While I have no practical experience, or know of anybody who has, I suspect the use of one’s complement might not be that big a problem. If you have experience please comment.
Arithmetic that wraps (i.e., positive values overflow negative and negative values underflow positive). While expressions explicitly written to wrap might be rare, how many calculations contain intermediate values that have wrapped but deliver a correct final result because they are ‘unwrapped’ by a subsequent operation?
Arithmetic operation that saturate are needed in applications such as graphics where, for instance, increasing the brightness should not suddenly cause the darkest setting to occur. Some graphics processors include support for arithmetic operations that saturate.
The impact of saturation arithmetic on portability is difficult to judge. A lot of code contains variables having signed char and short types, but when they appear as the operand in a binary operation these are promoted to int in C/C++/etc which probably has sufficient range not to overflow (most values created during program execution are small). Again I am lacking in practical experience and comments are welcome.
Floating-point. Many programs do not make use of floating-point arithmetic and those that do rarely manipulate such values at the bit level. Using a non-IEEE 754 floating-point representation will probably have little impact on the portability of applications of interest to most users.
Update. Thanks to Cate for pointing out that I had forgotten to discuss why using non-8-bit chars does is not a worthwhile design decision.
Both POSIX and the C/C++ Standards require that the char type be represented in at least 8 bits. Computers supporting less than 8-bits were still being used in the early 80s (e.g., the much beloved ICL 1900 supported 6-bit characters). The C Standard also requires that char be the smallest unit of addressable storage, which means that it must be possible for a pointer to point at an object having a char type.
Designing a processor where the smallest unit of storage is greater than 8-bits but not a power-of-2 is likely to substantially increase all sorts of costs and complicate things enormously (e.g., interfaces to main memory which are designed to work with power of two interfaces). The purpose of this design is to increase other people’s cost, not the proprietary vendor’s cost.
What about that pointer requirement? Perhaps the smallest unit of storage that a pointer could address might be 16 or 40 bits? Such processors exist and compiler writers have used both solutions to the problems they present. One solution is for a pointer to contain the address of the storage location + offset of the byte within that storage (Cray used this approach on a processor whose pointers could only point at 64-bit chunks of storage, with the compiler generating the code to extract the appropriate byte), the other is to declare that the char type occupies 40-bits (several DSP compilers have taken this approach).
Having the compiler declare that char is not 8-bits wide would cause all sorts of grief, so lets not go there. What about the Cray compiler approach?
Some of the address bits on 64-bit processors are not used yet (because few customers need that amount of storage) so compiler writers could get around host-processor pointers not supporting the granularity needed to point at 8-bit objects by storing the extra information in ‘unused’ pointer bits (the compiler generating the appropriate insertion and extraction code). The end result is that the compiler can hide pointer addressability issues :-).
Secret instruction sets about to make a come-back
Now it has happened Apple’s launch of a new processor, the A4, seems such an obvious thing to do. As the manufacturer of propriety products Apple wants to have complete control over the software that customers run on those products. Using a processor whose instruction set and electrical signals are not publicly available goes a very long way to ensuring that somebody else’s BIOS/OS/drivers/etc do not replace Apple’s or that the distributed software is not ‘usefully’ patched (Apple have yet to reveal their intentions on publishing instruction set details, this is an off-the-cuff prediction on my part).
Why are Apple funding the development of the LLVM C/C++ compiler? Because it enables them to write a back-end for the A4 without revealing the instruction set (using gcc for this purpose would require that the source be distributed, revealing the instruction set). So much for my prediction that Apple will stop funding LLVM.
The landscape of compute intensive cpus used to be populated with a wide variety of offerings from many manufacturers. The very high price of riding the crest of Moore’s law is one of the reasons that Intel’s x86 acquired such a huge chunk of this market; one by one processor companies decided not to make the investment needed to keep their products competitive. Now that the applicability of Moore’s law is drawing to an end the treadmill of continued processor performance upgrades is starting to fading away. Apple are not looking at a processor upgrade cycle, that they need to keep up with to be competitive, that stretches very far into the future.
Isn’t keeping an instruction set secret commercial suicide? The way to sell hardware is to make sure that lots of software runs on it and software developers want instruction set details (well ok, a small number do, but I’m sure lots of others get a warm fuzzy feeling knowing that the information is available should they need it). This is very much a last century view. The world is awash with an enormous variety of software, including lot of it very useful open source, and there is a lot more information available about the set of applications many customers want to use most of the time. Other than existing practice there is little reason why a manufacturer of a proprietary product, that is not a processor, needs to release instruction set details.
In the early 1980s I was at the technical launch of the Inmos Transputer and was told that the instruction set would not be published because the company did not want to be tied down to backwards compatibility. Perish the thought that customers would write assembler because the Inmos supplied compilers produced poor quality code or that a third party compiler would good enough to gain a significant market share. In marketing ability Inmos was the polar opposite of Apple. For a while HP were not very forthcoming on the instruction set behind their PA-RISC processor.
Will the A4 instruction set remain secret? On the whole, perhaps it can. The software based approaches to reverse engineering an instruction set require access to a compiler that generates it. For instance, changing a plus to a minus in one expression and looking for the small change in the generated executable; figuring out which status flags are set under which conditions is harder, but given time it can be done. Why would Apple release executable compilers if it wants to control the software that runs on the A4?
If the instruction set were cracked where would a developer go to obtain a compiler targeting the A4?
Given the FSF‘s history with Apple I would not be surprised if there was a fatwa against support for a proprietary instruction set in gcc. I suspect Apple would frown very heavily on such support ever being in the standard llvm distribution. I could see Apple’s lawyers sending letters to anybody making available a compiler that generated A4 code.
In the past manufacturers have tried to keep processor instruction sets secret and found that commercial reality required them to make this information freely available. Perhaps in the long term, like Moore’s law, the publication of detailed instruction set information may just be a passing phase.
Recent Comments