Archive
Human reasoning is generally not logic based
From around 350 BC until the 1960s, the students were taught that people reasoned using logic, and teachers believed this to be true. In the 1960s psychologists started running experiments that asked subjects to solve reasoning problems, the results showed that people often failed to give the answers dictated by logic.
Some recurring patterns were present in the answers given, and small changes in the wording of the question asked were found to produce different answer patterns. Very few researchers were willing to give up the idea that subjects were reasoning using logic, there must be another explanation, e.g., subjects must be interpreting the experimental questions asked in a way that differed from that assumed by the researchers. The social context of reasoning was one of the early drivers of evolutionary psychology; reasoning must provide some survival benefit by solving problems that regularly occur in natural human environments.
After a myriad of detailed theories did little more than predict small subsets of subject responses, mainstream reasoning research finally gave up the belief that logic is the default technique used by people to solve reasoning problems. Theories of reasoning behavior are now based around people estimating probabilities and picking the answer with the highest probability; this approach does a much better job of predicting common patterns in subject answers.
Experimental studies of reasoning often use psychology undergraduates as subjects (the historical norm, with Mechanical Turk workers becoming more common). While researchers may be concerned about how well undergraduate behavior mimics the general population, my concern is the extent to which these results apply to software developers. Is a necessary condition for being a professional software developer that a person, by default, uses logic to solve reasoning problems?
Of course, software developers claim that their reasoning is logic based, but then so do people in the general population (or at least the non-developers I interact with do). The dual-process theory of reasoning contains two reasoning systems, one unconscious/intuitive and the second a conscious/deliberate system; it has been said that the purpose of the second system is to come up with reasons to justify the answers produced by the first system.
Until reasoning experiments are run with professional developer subjects, we won’t know the extent to which existing results in reasoning research apply to this specialist subset of the population.
The Wason selection task is to studies of reasoning, like the fruit fly is to studies of genetics. What pattern of behavior do you show on this task (code)?
The plot below shows a set of four cards, of which you can see only the exposed face but not the hidden back. On each card, there is a number on one side and a letter on the other.
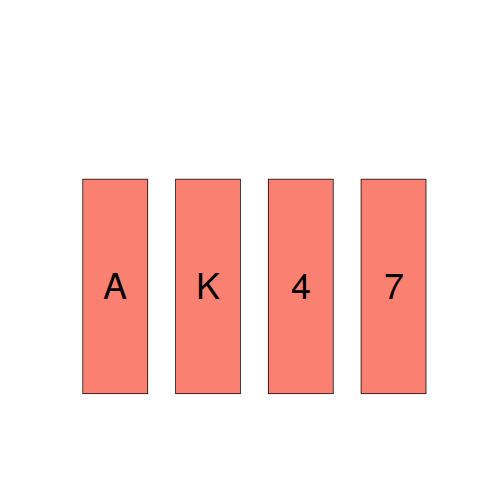
- Given the statement: “If there is a vowel on one side, then there is an even number on the other side.”
Your task is to decide, which, if any, of these four cards must be turned over to decide whether this statement is true. - Specify the cards you would turn over. Don’t turn unnecessary cards.
————————————
Most people correct specify that the card showing a vowel must be turned over to verify that an even number appears on the other side. A common mistake is to specify that the card showing an even number also has to be turned over. However, there is no requirement on the letter appearing on the other side of a card showing an even number. A second necessary condition involves a negative test (something that developers are known to overlook); for the statement to hold, a vowel must not appear on the other side of the card showing an odd number, this is the second card that must be turned over.
Filters to help decide who might be a software developer
How do you find people who are likely to be good software developers?
I use the filter approach: start with whoever is available, filter out those who are not likely candidates and go with those that are left (if any).
The first filter is a question: which language do you like to program in?
This question is positive, in that it assumes the other person is a developer; asking for the name of a language makes it a difficult to dodge question for those who don’t know any language. The language itself is irrelevant, apart from as a lead in to further discussion.
Learning to program is easy and a fun thing to do, at least if you are the kind of person likely to become a good developer. Cheap computing hardware has been available since the 1980s, the extra ingredients are a desire to write software and some degree of the necessary skills.
The next filter is a discussion about the largest software system they have written.
The theme of the discussion is how they solved the problems encountered during the implementation. Do the problems sound like something a developer of the person’s experience ought to find a problem? How much perseverance was shown in solving the problems, were they flexible in trying alternatives, what was their approach to problem solving?
Building systems is all about solving problems. People who cannot solve problems will fail, those with problem solving abilities might succeed.
What about paper qualifications?
Demand for developers continues to outstrip supply, creating an opportunity for turkeys to fly.
When getting a university degree was intellectually challenging, it was a sign of cognitive firepower. The stated aim of the UK government is for 50% of 18-year olds to study for a degree, which means that courses requiring high cognitive firepower are dumbed down (otherwise the failure rate goes through the roof and a University’s ranking suffers). If the only option is a turkey shoot, a degree in a subject requiring lots mathematical thinking (e.g., physics, chemistry, some psychology subjects, …) is obviously a much better filter than Medieval French, Modern History, etc.
There are people whose path through life has kept them away from computers when they were younger and university when they were a bit older. Software carpentry seems to be doing good things for such people; I don’t have any direct experience of working with those who have gone that route, and so cannot say anything about it.
Will this filter approach work for you? Well, it depends on the characteristics required of a good developer in your line of work.
Perhaps you need a regular Joe, who does the job, nine-to-five, and sticks to the tried and trusted approached; a solid person who keeps systems reliably maintained and customers happy.
The independent, frontier, mentality that thrives in ‘new’ fields is becoming a less tolerated in software development. The frontier shrinks as more and more software becomes good-enough and those with money to pay for change, spend it on something else.
Unexpected experimental effects
The only way to find out the factors that effect developers’ source code performance is to carry out experiments where they are the subjects. Developer performance on even simple programming tasks can be effected by a large number of different factors. People are always surprised at the very small number of basic operations I ask developers to perform in the experiments I run. My reply is that only by minimizing the number of factors that might effect performance can I have any degree of certainty that the results for the factors I am interested in are reliable.
Even with what appear to be trivial tasks I am constantly surprised by the factors that need to be controlled. A good example is one of the first experiments I ever ran. I thought it would be a good idea to replicate, using a software development context, a widely studied and reliably replicated human psychological effect; when asked to learn and later recall/recognize a list of words people make mistakes. Psychologists study this problem because it provides a window into the operation structure of the human memory subsystem over short periods of time (of the order of at most tens of seconds). I wanted to find out what sort of mistakes developers would make when asked to remember information about a sequence of simple assignment statements (e.g.,
qbt = 6;).I carefully read the appropriate experimental papers and had created lists of variables that controlled for every significant factor (e.g., number of syllables, frequency of occurrence of the words in current English usage {performance is better for very common words}) and the list of assignment statements was sufficiently long that it would just overload the capacity of short term memory (about 2 seconds worth of sound).
The results contained none of the expected performance effects, so I ran the experiment again looking for different effects; nothing. A chance comment by one of the subjects after taking part in the experiment offered one reason why the expected performance effects had not been seen. By their nature developers are problem solvers and I had set them a problem that asked them to remember information involving a list of assignment statements that appeared to be beyond their short term memory capacity. Problem solvers naturally look for patterns and common cases and the variables in each of my carefully created list of assignment statements could all be distinguished by their first letter. Subjects did not need to remember the complete variable name, they just needed to remember the first letter (something I had not controlled for). Asking around I found that several other subjects had spotted and used the same strategy. My simple experiment was not simple enough!
I was recently reading about an experiment that investigated the factors that motivate developers to comment code. Subjects were given some code and asked to add additional functionality to it. Some subjects were given code containing lots of comments while others were given code containing few comments. The hypothesis was that developers were more likely to create comments in code that already contained lots of comments, and the results seemed to bear this out. However, closer examination of the answers showed that most subjects had cut and pasted chunks (i.e., code and comments) from the code they were given. So code the percentage of code in the problem answered mimicked that in the original code (in some cases subjects had complicated the situation by refactoring the code).