Archive
Memory capacity growth: a major contributor to the success of computers
The growth in memory capacity is the unsung hero of the computer revolution. Intel’s multi-decade annual billion dollar marketing spend has ensured that cpu clock frequency dominates our attention (a lot of people don’t know that memory is available at different frequencies, and this can have a larger impact on performance that cpu frequency).
In many ways memory capacity is more important than clock frequency: a program won’t run unless enough memory is available but people can wait for a slow cpu.
The growth in memory capacity of customer computers changed the structure of the software business.
When memory capacity was limited by a 16-bit address space (i.e., 64k), commercially saleable applications could be created by one or two very capable developers working flat out for a year. There was no point hiring a large team, because the resulting application would be too large to run on a typical customer computer. Very large applications were written, but these were bespoke systems consisting of many small programs that ran one after the other.
Once the memory capacity of a typical customer computer started to regularly increase it became practical, and eventually necessary, to create and sell applications offering ever more functionality. A successful application written by one developer became rarer and rarer.
Microsoft Windows is the poster child application that grew in complexity as computer memory capacity grew. Microsoft’s MS-DOS had lots of potential competitors because it was small (it was created in an era when 64k was a lot of memory). In the 1990s the increasing memory capacity enabled Microsoft to create a moat around their products, by offering an increasingly wide variety of functionality that required a large team of developers to build and then support.
GCC’s rise to dominance was possible for the same reason as Microsoft Windows. In the late 1980s gcc was just another one-man compiler project, others could not make significant contributions because the resulting compiler would not run on a typical developer computer. Once memory capacity took off, it was possible for gcc to grow from the contributions of many, something that other one-man compilers could not do (without hiring lots of developers).
How fast did the memory capacity of computers owned by potential customers grow?
One source of information is the adverts in Byte (the magazine), lots of pdfs are available, and perhaps one day a student with some time will extract the information.
Wikipedia has plenty of articles detailing cpu performance, e.g., Macintosh models by cpu type (a comparison of Macintosh models does include memory capacity). The impact of Intel’s marketing dollars on the perception of computer systems is a PhD thesis waiting to be written.
The SPEC benchmarks have been around since 1988, recording system memory capacity since 1994, and SPEC make their detailed data public 🙂 Hardware vendors are more likely to submit SPEC results for their high-end systems, than their run-of-the-mill systems. However, if we are looking at rate of growth, rather than absolute memory capacity, the results may be representative of typical customer systems.
The plot below shows memory capacity against date of reported benchmarking (which I assume is close to the date a system first became available). The lines are fitted using quantile regression, with 95% of systems being above the lower line (i.e., these systems all have more memory than those below this line), and 50% are above the upper line (code+data):
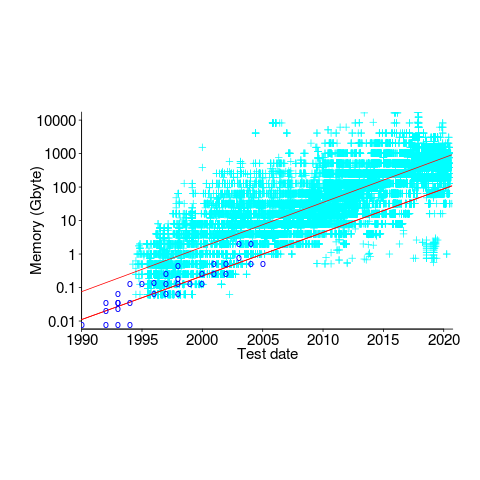
The fitted models show the memory capacity doubling every 845 or 825 days. The blue circles are memory that comes installed with various Macintosh systems, at time of launch (memory doubling time is 730 days).
How did applications’ minimum required memory grow over time? I have a patchy data for a smattering of products, extracted from Wikipedia. Some vendors probably required customers to have a fairly beefy machine, while others went for a wider customer base. Data on the memory requirements of the various versions of products launched in the 1990s is very hard to find. Pointers very welcome.
Recent Comments