Archive
Three books discuss three small data sets
During the early years of a new field, experimental data relating to important topics can be very thin on the ground. Ever since the first computer was built, there has been a lot of data on the characteristics of the hardware. Data on the characteristics of software, and the people who write it, has been (and often continues to be) very thin on the ground.
Books are sometimes written by the researchers who produce the first data associated with an important topic, even if the data set is tiny; being first often generates enough interest for a book length treatment to be considered worthwhile.
As a field progresses lots more data becomes available, and the discussion in subsequent books can be based on findings from more experiments and lots more data
Software engineering is a field where a few ‘first’ data books have been published, followed by silence, or rather lots of arm waving and little new data. The fall of Rome has been followed by a 40-year dark-age, from which we are slowly emerging.
Three of these ‘first’ data books are:
- “Man-Computer Problem Solving” by Harold Sackman, published in 1970, relating to experimental data from 1966. The experiments investigated the impact of two different approaches to developing software, on programmer performance (i.e., batch processing vs. on-line development; code+data). The first paper on this work appeared in an obscure journal in 1967, and was followed in the same issue by a critique pointing out the wide margin of uncertainty in the measurements (the critique agreed that running such experiments was a laudable goal).
Failing to deal with experimental uncertainty is nothing compared to what happened next. A 1968 paper in a widely read journal, the Communications of the ACM, contained the following table (extracted from a higher quality scan of a 1966 report by the same authors, and available online).
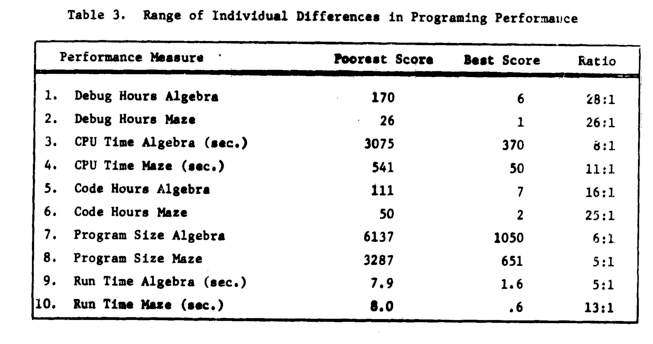
The tale of 1:28 ratio of programmer performance, found in an experiment by Grant/Sackman, took off (the technical detail that a lot of the difference was down to the techniques subjects’ used, and not the people themselves, got lost). The Grant/Sackman ‘finding’ used to be frequently quoted in some circles (or at least it did when I moved in them, I don’t know often it is cited today). In 1999, Lutz Prechelt wrote an expose on the sorry tale.
Sackman’s book is very readable, and contains lots of details and data not present in the papers, including survey data and a discussion of the intrinsic uncertainties associated with the experiment; it also contains the table above.
- “Software Engineering Economics” by Barry W. Boehm, published in 1981. I wrote about the poor analysis of the data contained in this book a few years ago.
The rest of this book contains plenty of interesting material, and even sounds modern (because books moving the topic forward have not been written).
- “Program Evolution: Process of Software Change” edited by M. M. Lehman and L. A. Belady, published in 1985, relating to experimental data from 1977 and before. Lehman and Belady managed to obtain data relating to 19 releases of an IBM software product (yes, 19, not nineteen-thousand); the data was primarily the date and number of modules contained in each release, plus less specific information about number of statements. This data was sliced and diced every which way, and the book contains many papers with the same data appearing in the same plot with different captions (had the book not been a collection of papers it would have been considerably shorter).
With a lot less data than Isaac Newton had available to formulate his three laws, Lehman and Belady came up with five, six, seven… “laws of software evolution” (which themselves evolved with the publication of successive papers).
The availability of Open source repositories means there is now a lot more software system evolution data available. Lehman’s laws have not stood the test of more data, although people still cite them every now and again.
Lehman ‘laws’ of software evolution
The so called Lehman laws of software evolution originated in a 1968 study, and evolved during the 1970s; the book “Program Evolution: processes of software change” by Lehman and Belady was published in 1985.
The original work was based on measurements of OS/360, IBM’s flagship operating system for the computer industries flagship computer. IBM dominated the computer industry from the 1950s, through to the early 1980s; OS/360 was the Microsoft Windows, Android, and iOS of its day (in fact, it had more developer mind share than any of these operating systems).
In its day, the Lehman dataset not only bathed in reflected OS/360 developer mind-share, it was the only public dataset of its kind. But today, this dataset wouldn’t get a second look. Why? Because it contains just 19 measurement points, specifying: release date, number of modules, fraction of modules changed since the last release, number of statements, and number of components (I’m guessing these are high level programs or interfaces). Some of the OS/360 data is plotted in graphs appearing in early papers, and can be extracted; some of the graphs contain 18, rather than 19, points, and some of the values are not consistent between plots (extracted data); in later papers Lehman does point out that no statistical analysis of the data appears in his work (the purpose of the plots appears to be decorative, some papers don’t contain them).
One of Lehman’s early papers says that “… conclusions are based, comes from systems ranging in age from 3 to 10 years and having been made available to users in from ten to over fifty releases.“, but no other details are given. A 1997 paper lists module sizes for 21 releases of a financial transaction system.
Lehman’s ‘laws’ started out as a handful of observations about one very large software development project. Over time ‘laws’ have been added, deleted and modified; the Wikipedia page lists the ‘laws’ from the 1997 paper, Lehman retired from research in 2002.
The Lehman ‘laws’ of software evolution are still widely cited by academic researchers, almost 50-years later. Why is this? The two main reasons are: the ‘laws’ are sufficiently vague that it’s difficult to prove them wrong, and Lehman made a large investment in marketing these ‘laws’ (e.g., publishing lots of papers discussing these ‘laws’, and supervising PhD students who researched software evolution).
The Lehman ‘laws’ are not useful, in the sense that they cannot be used to make predictions; they apply to large systems that grow steadily (i.e., the kind of systems originally studied), and so don’t apply to some systems, that are completely rewritten. These ‘laws’ are really an indication that software engineering research has been in a state of limbo for many decades.
Update: Added numbers from appendix of “Software Engineering Metrics and Models” by Conte, Dunsmore, and Shen.
Recent Comments