Archive
Will incorrect answers be biased towards one arm of an if-statement?
Sometimes it is possible to deduce which arm of a nested if-statement will be executed by looking at the form of the conditional expression in the outer if-statement, as in:
if ((L < M) && (M < H)) if (L < H) ; // Execution always end up here else ; // dead code |
but not in:
if ((L > M) && (M < H)) if (L < H) ; // Could end up here else ; // or here |
I ran an experiment at the 2012 ACCU conference where subjects saw nested if-statements like those above and had to specify which arm of the nested if-statement would be executed.
Sometimes subjects gave an answer specifying one arm when in fact both arms are possible. Now dear reader, do you think these incorrect answers will specify the then arm 50% of the time and the else arm 50% or do you think that that incorrect answers will more often specify one particular arm?
Of course I should have thought about this before I started to analyse the data, but this question is unrelated to the subject of the experiment and has only just cropped up because of the unexpectedly high percentage of this kind of incorrect answer. I had an idea what the answer would be but did not stop and think about relative percentages, rushing off to write a few lines of code to print the actual totals, so now my mind is polluted by knowing the answer (well at least for one group of subjects in one experiment).
Why does this “one arm preference” issue matter? The Bayesians out there will insist that the expected distribution (the prior in Bayesian terminology) of incorrectly chosen arms be factored in to the calculation of the probability of getting the numbers seen in the results. The paper Belgian euro coins: 140 heads in 250 tosses – suspicious? gives a succinct summary of the possibilities.
So I have decided to appeal to my experienced readership, yes YOU!
For those questions where the actual execution cannot be predicted in advance, from knowledge of the relative values of variables appearing in the outer if-statement, when an incorrect answer is given should the analysis assume:
- a 50/50 split of incorrect answers between each arm, or
- subjects are more likely to pick one arm; please specify a percentage breakdown between arms.
No pressure, but the submission deadline is very late tomorrow.
The results from the whole experiment will get written up here in future posts.
Update (three days later): Nobody was willing to stick their head above the parapet 🙁
There were 69 correct answers and 16 incorrect answers to questions whose answer was “both arm”. Ten of those incorrect answers specified the ‘then’ arm and 6 the ‘else’; my gut feeling was that there should be even more ‘then’ answers. If there was no “first arm” there is an equal probability of a subject’s incorrect answer appearing in either arm; in this case the probability of a 10/6 split is 12% (so my gut feeling was just hunger pangs after all).
Undefined behavior can travel back in time
The committee that produced the C Standard tried to keep things simple and sometimes made very short general statements that relied on compiler writers interpreting them in a ‘reasonable’ way. One example of this reliance on ‘reasonable’ behavior is the definition of undefined behavior; “… erroneous program construct or of erroneous data, for which this International Standard imposes no requirements”. The wording in the Standard permits a compiler to process the following program:
int main(int argc, char **argv) { // lots of code that prints out useful information 1 / 0; // divide by zero, undefined behavior } |
to produce an executable that prints out “yah boo sucks”. Such behavior would probably be surprising to the developer who expected the code printing the useful information to be executed before the divide by zero was encountered. The phrase quality of implementation is heard a lot in committee discussions of this kind of topic, but this phrase does not appear in any official document.
A modern compiler is essentially a sophisticated domain specific data miner that happens to produce machine code as output and compiler writers are constantly looking for ways to use the information extracted to minimise the code they generate (minimal number of instructions or minimal amount of runtime). The following code is from the Linux kernel and its authors were surprised to find that the “division by zero” messages did not appear when arg2 was 0, in fact the entire if-statement did not appear in the generated code; based on my earlier example you can probably guess what the compiler has done:
if (arg2 == 0) ereport(ERROR, (errcode(ERRCODE_DIVISION_BY_ZERO), errmsg("division by zero"))); /* No overflow is possible */ PG_RETURN_INT32((int32)arg1 / arg2); |
Yes, it figured out that when arg2 == 0 the divide in the call to PG_RETURN_INT32 results in undefined behavior and took the decision that the actual undefined behavior in this instance would not include making the call to ereport which in turn made the if-statement redundant (smaller+faster code, way to go!)
There is/was a bug in Linux because of this compiler behavior. The finger of blame could be pointed at:
- the developers for not specifying that the function
ereportdoes not return (this would enable the compiler to deduce that there is no undefined behavior because the divide is never execute whenarg2 == 0), - the C Standard committee for not specifying a timeline for undefined behavior, e.g., program behavior does not become undefined until the statement containing the offending construct is encountered during program execution,
- the compiler writers for not being ‘reasonable’.
In the coming years more and more developers are likely to encounter this kind of unexpected behavior in their programs as compilers do more and more data mining and are pushed to improve performance. Other examples of this kind of behavior are given in the paper Undefined Behavior: Who Moved My Code?
What might be done to reduce the economic cost of the fallout from this developer ignorance/standard wording/compiler behavior interaction? Possibilities include:
- developer education: few developers are aware that a statement containing undefined behavior can have an impact on the execution of code that occurs before that statement is executed,
- change the wording in the Standard: for many cases there is no reason why the undefined behavior be allowed to reach back in time to before when the statement executing it is executed; this does not mean that any program output is guaranteed to occur, e.g., the host OS might delete any pending output when a divide by zero exception occurs.
- paying gcc/llvm developers to do front end stuff: nearly all gcc funding is to do code generation work (I don’t know anything about llvm funding) and if the US Department of Homeland security are interested in software security they should fund related front end work in gcc and llvm (e.g., providing developers with information about suspicious usage in the code being compiled; the existing
-Wallis a start).
Generating code that looks like it is human written
I am very interested in understanding the patterns of developer behavior that lead to the human characteristics that can be found in code. To help me get some idea of how well I understand this behavior I have decided to build a tool that generates source code that appears to be written by human programmers. I hope to reach a point where I can offer a challenge to tell the difference between generated code and human written code.
The three main production techniques I plan to use are, in increasing order of relatedness to humans production techniques, are:
- Random generation based on percentage occurrence of language constructs obtained from measurements of existing source. This is the simplest approach and the one furthest away from common developer behavior; even so there are things that can be learned from this information. For instance, the theory that developers are more likely to create a function once code becomes heavily nested code implies that the probability of encountering an if-statement decreases as nesting depth increases; measurements show the probability of encountering an if-statement remaining approximately constant as depth of nesting increases.
- Behavior templates. People have habits in everyday life and also when writing software. While some habits are idiosyncratic and not encountered very often there are some that appear to be generally used. For instance, developers tend to assign a fixed role to every variable they define (e.g., stepper for stepping through a succession of values and most-recent holder holding the latest value encountered in going through a succession of values).
I am expecting/hoping that generation by behavioral templates will result in code having some of the probabilistic properties seen in human code, removing the need for purely random generation driven by low level language probability measurements. For instance, the probability of a local variable appearing in a function is proportional to the percentage of its previous occurrences up to that point in the source of the function (
percentage = occurrences_of_X / occurrences_of_all_local_variables) and I am hoping that this property appears as emergent behavior from generating using the role of variable template. - Story telling. A program is like the plot of a story, it has a cast of characters (e.g., classes, functions, libraries) that perform various actions and interact with each other in order to achieve various goals, there are subplots (intermediate results are calculated, devices are initialized, etc), there are resource limits, etc.
While a lot of stories are application domain specific there are subplots common to many stories; also how a story is told can be heavily influenced by the language used, for instance Prolog programs have a completely different structure than those written in procedural languages such as Java. I want to stay away from being application specific and I don’t plan to tackle languages too far outside the common-or-garden procedural variety.
Researchers have created automatic story generators; the early generators were template based while more recent systems have used an agent based approach. Story based generation of code is my ideal, but I am a long way away from having enough knowledge of developer behavior to be more than template based.
In a previous post I described a system for automatically generating very simply C programs. I plan to build on this system to incrementally improve the ‘humanness’ of the generated code. At some point, hopefully before the end of this year, I will challenge people to tell the difference between automatically generated and human written code.
The language I have studied the most is C and this will be the main target. I don’t want to be overly C specific and am trying to decide on a good second language (i.e., lots of source available for measurement, used by lots of developers and not too different from C). JavaScript is the current front runner, it is a class-less object oriented language which is not ‘wildly’ OO (the patterns of usage in human written OO code continue to evolve at a rapid rate which can make a lot of human C++/Java code look automatically generated).
As well as being a test bed for understanding of human generated code other uses for an automatic generator include compiler stress testing and providing code snippets to an automated fault fixing tool.
Estimating the quality of a compiler implemented in mathematics
How can you tell if a language implementation done using mathematical methods lives up to the claims being made about it, without doing lots of work? Answers to the following questions should give you a good idea of the quality of the implementation, from a language specification perspective, at least for C.
- How long did it take you to write it? I have yet to see any full implementation of a major language done in less than a man year; just understanding and handling the semantics, plus writing the test cases will take this long. I would expect an answer of at least several man years
- Which professional validation suites have you tested the implementation against? Many man years of work have gone into the Perennial and PlumHall C validation suites and correctly processing either of them is a non-trivial task. The gcc test suite is too light-weight to count. The C Model Implementation passed both
- How many faults have you found in the C Standard that have been accepted by WG14 (DRs for C90 and C99)? Everybody I know who has created a full implementation of a C front end based on the text of the C Standard has found faults in the existing wording. Creating a high quality formal definition requires great attention to detail and it is to be expected that some ambiguities/inconsistencies will be found in the Standard. C Model Implementation project discoveries include these and these.
- How many ‘rules’ does the implementation contain? For the C Model Implementation (originally written in Pascal and then translated to C) every if-statement it contained was cross referenced to either a requirement in the C90 standard or to an internal documentation reference; there were 1,327 references to the Environment and Language clauses (200 of which were in the preprocessor and 187 involved syntax). My C99 book lists 2,043 sentences in the equivalent clauses, consistent with a 70% increase in page count over C90. The page count for C1X is around 10% greater than C99. So for a formal definition of C99 or C1X we are looking for at around 2,000 language specific ‘rules’ plus others associated with internal housekeeping functions.
- What percentage of the implementation is executed by test cases? How do you know code/mathematics works if it has not been tested? The front end of the C Model Implementation contains 6,900 basic blocks of which 87 are not executed by any test case (98.7% coverage); most of the unexecuted basic blocks require unusual error conditions to occur, e.g., disc full, and we eventually gave up trying to figure out whether a small number of them were dead code or just needed the right form of input (these days genetic programming could be used to help out and also to improve the quality of coverage to something like say MC/DC, but developing on a PC with a 16M hard disc does limit what can be done {the later arrival of a Sun 4 with 32M of RAM was mind blowing}).
Other suggested questions or numbers applicable to other languages most welcome. Some forms of language definition do not include a written specification, which makes any measurement of implementation conformance problematic.
Estimating variance when measuring source
Yesterday I finally delivered a paper on if/switch usage measurements to the ACCU magazine editor and today I read about a switch statement usage that, if common, would invalidate a chunk of my results. Does anything jump out at you in the following snippet?
switch (x) { case 1: { z++; ... break; } ... |
Yes, those { } delimiting the case-labeled statement sequence. A quick check of my C source benchmarks showed this usage occurring in around 1% of case-labels. Panic over.
What is the statistical significance, i.e., variance, of that 1%? Have I simply measured an unrepresentative sample, what would be a representative sample and what would be the expected variance within a representative sample?
I am interested in commercial software development, and so I have selected half a dozen or so largish code bases as my source benchmark, preferably written in a commercial environment even if currently available as Open source. I would prefer this benchmark to be an order of magnitude larger, and perhaps I will get around to adding more programs soon.
My if/switch measurements were aimed at finding usage characteristics that varied between the two kinds of selection statements. One characteristic measured was the number of equality tests in the associated controlling expression. For instance, in:
if (x == 1 || x == 2) z--; else if (x == 3) z++; |
the first controlling expression contains two equality tests, and the second one equality test.
Plotting the percentage of equality tests that occur in the controlling expressions of if-if/if-else-if sequences and switch statements, we get the following:
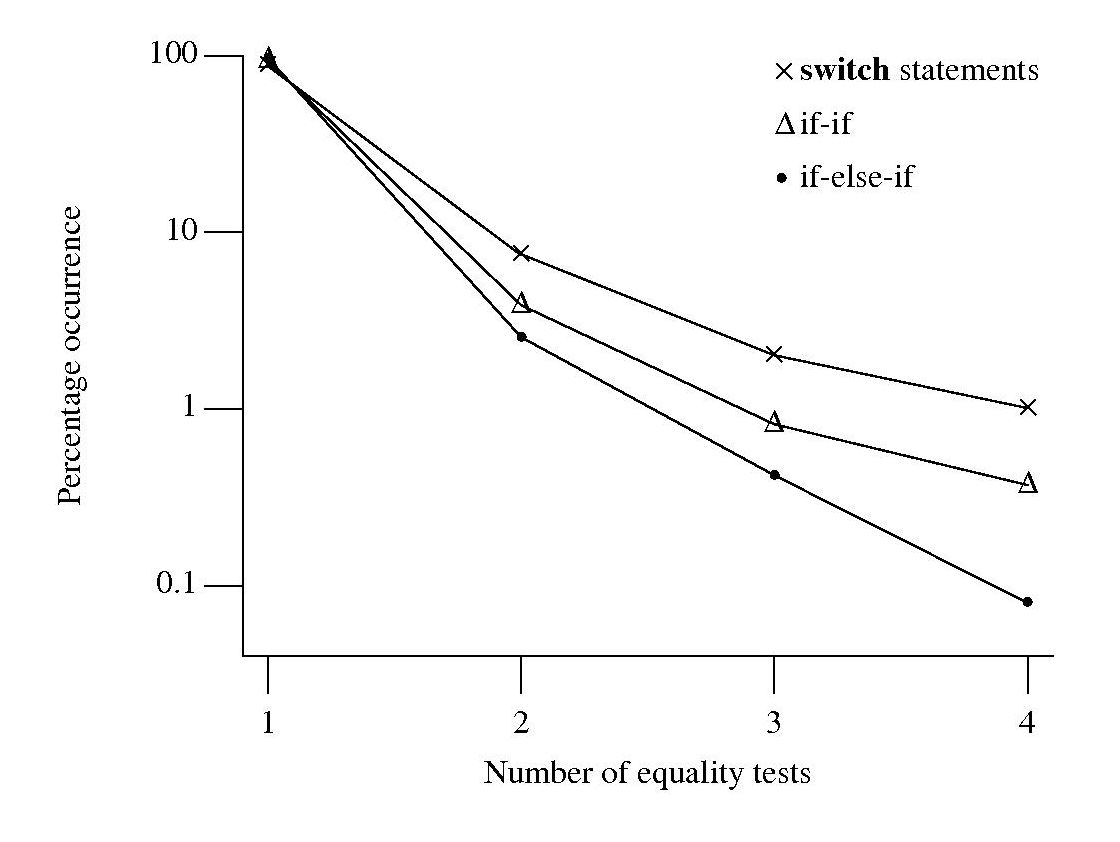
Do these results indicate that if-if/if-else-if sequences and switch statements differ in the number of equality tests contained in their controlling expressions? If I measured a completely different set of source code, would the results be very different?
To answer this question, a probability model is needed. Take as an example, the controlling expressions present in an if-if sequence. If each controlling expression is independent of the others, then the probability of two equality tests, for instance, occurring in any of these expressions is constant and thus given a large sample the distribution of two equality tests in the source has a binomial distribution. The same argument can be applied to other numbers of equality tests and other kinds of sequence.

For each measurement point in the above plot the associated error bars span the square-root of the variance of that point (assuming a binomial distribution, for a normal distribution the length of this span is known as the standard deviation). The error bars overlap, suggesting that the apparent difference in percentage of equality tests in each kind of sequence is not statistically significant.
The existence of some dependency between controlling expression equality tests would invalidate this simply analysis, or at least reduce its reliability. I did notice that in a sequence that containing two equality tests, the controlling expression that contained it tended to appear later in the sequence (the reverse of the example given above). Did I notice this because I tend to write this way? A question for another day.
To if-else-if or if-if, that is the question
I am currently measuring if-statements, occurring in visible source, that might be mapped to an equivalent switch-statement. The most obvious usage to look for is a sequence of if-else-if statements that all involve the same expression being tested against an integer constant, as in
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
Another possible sequence is:
if (x == 1) stmt_1; if (x == 2) stmt_2; if (x == 3) stmt_3; |
provided all but the last conditionally executed arms do not change the value of the common control variable (e.g., x).
I started to wonder about what would cause a developer to chose one of these forms over the other. Perhaps the if-if form would be used when it was obvious that the common conditional variable was not modified in the conditionally executed arm. This would imply that there would be more statements in the arms of if-else-if sequences than if-if sequences. The following plot of percentage occurrence (over all detected if-else-if/if-if forms) of line number difference between pars of associated if-statements (e.g., when the controlling expression occurs on line
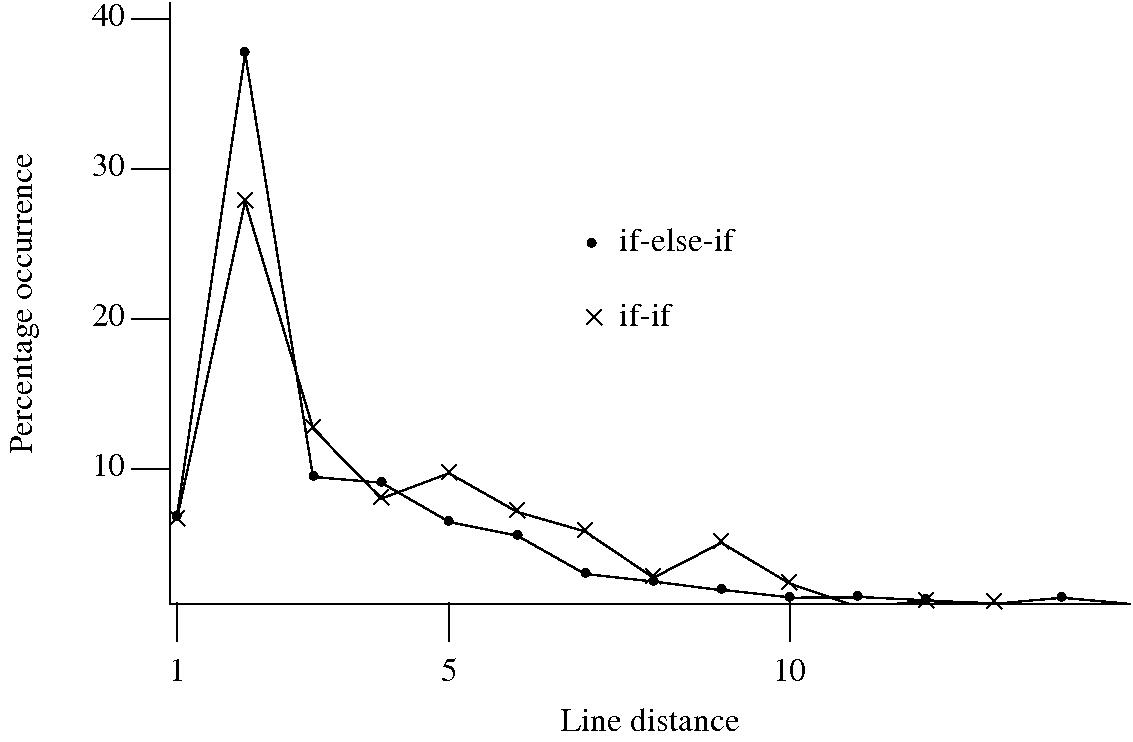
Just over a quarter of the arms contain a single statement (or to be exact the code is contained on a single line); this suggests that when using the if-else-if form most developers put the else and if on the same line. At the next distance along the percentage of if-else-if forms is twice as great as the if-if, probably because of else and if appearing on separate lines (as in the introductory example) in one case and less frequently a comment/blank line in the other. Next along, why the big increase in if-if forms? A comment + blank line, or perhaps no comment or blank line but the use of curly brackets (this is too off the track of where I am supposed to be going to investigate).
This morning I realized why the original plot did not look right, one of the data sets was a way off adding to 100%. An updated version has been uploaded.
It turns out that a single statement (or at least a single line) is more common in the if-else-if form, the opposite of what I had expected. At slightly larger distances there are still differences that can be attributed to else and if appearing on separate lines, curly brackets and a comment/blank line, but the effect is not as large as seen in the original, less accurate, plot.
I have a feeling that I ought to say something about the if-else-if form being preferred to the if-if form. One of the forms will have its behavior changed if the common control variable is modified in one of its arms. But is this an intended or unintended behavior? What is the typical characteristic usage of a common control variable, e.g., do they tend to be accessed but not modified in a given function definition? At the moment I see no obvious cost or benefit strongly favoring one usage over the other, so I will remain silent on the issue.
Implementing the between operation
What code do developers write to check whether a value lies between two bounds (i.e., a between operation)? I would write (where MIN and MAX might be symbolic names or numeric literals):
if ( x >= MIN && x <= MAX ) |
that is I would check the lowest value first. Performing the test in this order just seems the natural thing to do, perhaps because I live in a culture that writes left to write and a written sequence of increasing numbers usually has the lowest number on the left.
I am currently measuring various forms of if-statement conditional expressions that occur in visible source as part of some research on if/switch usage by developers and the between operation falls within the set of expressions of interest. I was not expecting to see any usage of the form:
if ( x <= MAX && x >= MIN ) |
that is with the maximum value appearing first. The first program measured threw up seven instances of this usage, all with the minimum value being negative and in five cases the maximum value being zero. Perhaps left to right ordering still applied, but to the absolute value of the bounds.
Measurements of the second and subsequent programs threw up instances that did not follow any of the patterns I had dreamt up. Of the 326 between operations appearing in the measured source 24 had what I consider to be the unnatural order. Presumably the developers using this form of between consider it to be natural, so what is their line of thinking? Are they thinking in terms of the semantics behind the numbers (in about a third of cases symbolic constants appear in the source rather than literals) and this semantics has an implied left to right order? Perhaps the authors come from a culture where the maximum value often appears on the left.
Suggestions welcome.
Recent Comments