Archive
Ability to remember code improves with experience
What mental abilities separate an expert from a beginner?
In the 1940s de Groot studied expertise in Chess. Players were shown a chess board containing various pieces and then asked to recall the locations of the pieces. When the location of the chess pieces was consistent with a likely game, experts significantly outperformed beginners in correct recall of piece location, but when the pieces were placed at random there was little difference in recall performance between experts and beginners. Also players having the rank of Master were able to reconstruct the positions almost perfectly after viewing the board for just 5 seconds; a recall performance that dropped off sharply with chess ranking.
The interpretation of these results (which have been duplicated in other areas) is that experts have learned how to process and organize information (in their field) as chunks, allowing them to meaningfully structure and interpret board positions; beginners don’t have this ability to organize information and are forced to remember individual pieces.
In 1981 McKeithen, Reitman, Rueter and Hirtle repeated this experiment, but this time using 31 lines of code and programmers of various skill levels. Subjects were given two minutes to study 31 lines of code, followed by three minutes to write (on a blank sheet of paper) all the code they could recall; this process was repeated five times (for the same code). The plot below shows the number of lines correctly recalled by experts (2,000+ hours programming experience), intermediates (just finished programming course) and beginners (just started programming course), left performance using ‘normal’ code and right is performance viewing code created by randomizing lines from ‘normal’ code; only the mean values in each category are available (code+data):
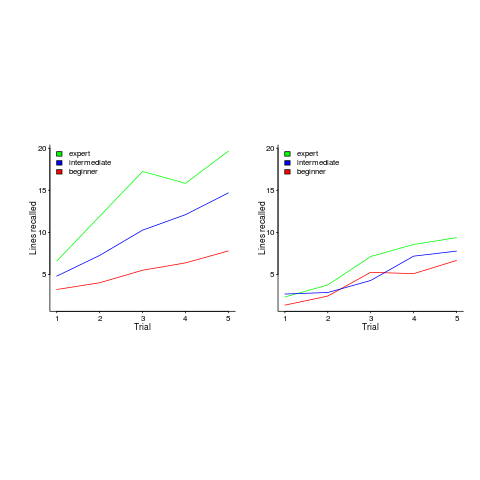
Experts start off remembering more than beginners and their performance improves faster with practice.
Compared to the Power law of practice (where experts should not get a lot better, but beginners should improve a lot), this technique is a much less time consuming way of telling if somebody is an expert or beginner; it also has the advantage of not requiring any application domain knowledge.
If you have 30 minutes to spare, why not test your ‘expertise’ on this code (the .c file, not the .R file that plotted the figure above). It’s 40 odd lines of C from the Linux kernel. I picked C because people who know C++, Java, PHP, etc should have no trouble using existing skills to remember it. What to do:
- You need five blank sheets of paper, a pen, a timer and a way of viewing/not viewing the code,
- view the code for 2 minutes,
- spend 3 minutes writing down what you remember on a clean sheet of paper,
- repeat until done 5 times.
Count how many lines you correctly wrote down for each iteration (let’s not get too fussed about exact indentation when comparing) and send these counts to me (derek at the primary domain used for this blog), plus some basic information on your experience (say years coding in language X, years in Y). It’s anonymous, so don’t include any identifying information.
I will wait a few weeks and then write up the data o this blog, as well as sharing the data.
Update: The first bug in the experiment has been reported. It takes longer than 3 minutes to write out all the code. Options are to stick with the 3 minutes or to spend more time writing. I will leave the choice up to you. In a test situation, maximum time is likely to be fixed, but if you have the time and want to find out how much you remember, go for it.
Using identifier prefixes results in more developer errors
Human speech communication has to be processed in real time using a cpu with a very low clock rate (i.e., the human brain whose neurons fire at rates between 10-100 Hz). Biological evolution has mitigated the clock rate problem by producing a brain with parallel processing capabilities and cultural evolution has chipped in by organizing the information content of languages to take account of the brains strengths and weaknesses. Words provide a good example of the way information content can be structured to be handled by a very slow processor/memory system, e.g., 85% of English words start with a strong syllable (for more details search for initial in this detailed analysis of human word processing).
Given that the start of a word plays an important role as an information retrieval key we would expect the code reading performance of software developers to be affected by whether the identifiers they see all start with the same letter sequence or all started with different letter sequences. For instance, developers would be expected to make fewer errors or work quicker when reading the visually contiguous sequence consoleStr, startStr, memoryStr and lineStr, compared to say strConsole, strStart, strMemory and strLine.
An experiment I ran at the 2011 ACCU conference provided the first empirical evidence of the letter prefix effect that I am aware of. Subjects were asked to remember a list of four assignment statements, each having the form id=constant;, perform an unrelated task for a short period of time and then recall information about the previously seen constants (e.g., their value and which variable they were assigned to).
During recall subjects saw a list of five identifiers and one of the questions asked was which identifier was not in the previously seen list? When the list of identifiers started with different letters (e.g., cat, mat, hat, pat and bat) the error rate was 2.6% and when the identifiers all started with the same letter (e.g., pin, pat, pod, peg, and pen) the error rate was 5.9% (the standard deviation was 4.5% and 6.8% respectively, but ANOVA p-value was 0.038). Having identifiers share the same initial letter appears to double the error rate.
This looks like great news; empirical evidence of software developer behavior following the predictions of a model of human human speech/reading processing. A similar experiment was run in 2006, this asked subjects to remember a list of three assignment statements and they had to select the ‘not seen’ identifier from a list of four possibilities. An analysis of the results did not find any statistically significant difference in performance for the same/different first letter manipulation.
The 2011/2006 experiments throw up lots of questions, including: does the sharing a prefix only make a difference to performance when there are four or more identifiers, how does the error rate change as the number of identifiers increases, how does the error rate change as the number of letters in the identifier change, would the effect be seen for a list of three identifiers if there was a longer period between seeing the information and having to recall it, would the effect be greater if the shared prefix contained more than one letter?
Don’t expect answers to appear quickly. Experimenting using people as subjects is a slow, labour intensive process and software developers don’t always answer the question that you think they are answering. If anybody is interested in replicating the 2011 experiment the tools needed to generate the question sheets are available for download.
For many years I have strongly recommended that developers don’t prefix a set of identifiers sharing some attribute with a common letter sequence (its great to finally have some experimental backup, however small). If it is considered important that an attribute be visible in an identifiers spelling put it at the end of the identifier.
See you all at the ACCU conference tomorrow and don’t forget to bring a pen/pencil. I have only printed 40 experiment booklets, first come first served.
The complexity of three assignment statements
Once I got into researching my book on C I was surprised at how few experiments had been run using professional software developers. I knew a number of people on the Association of C and C++ Users committee, in particular the then chair Francis Glassborow, and suggested that they ought to let me run an experiment at the 2003 ACCU conference. They agreed and I have been running an experiment every year since.
Before the 2003 conference I had never run an experiment that had people as subjects. I knew that if I wanted to obtain a meaningful result the number of factors that could vary had to be limited to as few as possible. I picked a topic which has probably been the subject of more experiments that any other topics, short term memory. The experimental design asked subjects to remember a list of three assignment statements (e.g., X = 5;), perform an unrelated task that was likely to occupy them for 10 seconds or so, and then recognize the variables they had previously seen within a list and recall the numeric value assigned to each variable.
I knew all about the factors that influenced memory performance for lists of words: word frequency, word-length, phonological similarity, how chunking was often used to help store/recall information and more. My variable names were carefully chosen to balance all of these effects and the information content of the three assignments required slightly more short term memory storage than subjects were likely to have.
The results showed none of the effects that I was expecting. Had I found evidence that a professional software developer’s brain really did operate differently than other peoples’ or was something wrong with my experiment? I tried again two years later (I ran a non-memory experiment the following year while I mulled over my failure) and this time a chance conversation with one of the subjects after the experiment uncovered one factor I had not controlled for.
Software developers are problem solvers (well at least the good ones are) and I had presented them with a problem; how to remember information that appeared to require more storage than available in their short term memories and accurately recall it shortly afterwards. The obvious solution was to reduce the amount of information that needed to be stored by simply remembering the first letter of every variable (which one of the effects I was controlling for had insured was unique) not the complete variable name.
I ran another experiment the following year and still did not obtain the expected results. What was I missing now? I don’t know and in 2008 I ran a non-memory based experiment. I still have no idea what techniques my subjects are using to remember information about three assignment statements that are preventing me getting the results I expect.
Perhaps those researchers out there that claim to understand the processes involved in comprehending a complete function definition can help me out by explaining the mental processes involved in remembering information about three assignment statements.
Recent Comments