Archive
C++ template usage
Generics are a programming construct that allow an algorithm to be coded without specifying the types of some variables, which are supplied later when a specific instance (for some type(s)) is instantiated. Generics sound like a great idea; who hasn’t had to write the same function twice, with the only difference being the types of the parameters.
All of today’s major programming languages support some form of generic construct, and developers have had the opportunity to use them for many years. So, how often generics are used in practice?
In C++, templates are the language feature supporting generics.
The paper: How C++ Templates Are Used for Generic Programming: An Empirical Study on 50 Open Source Systems contains lots of interesting data 🙂 The following analysis applies to the five largest projects analysed: Chromium, Haiku, Blender, LibreOffice and Monero.
As its name suggests, the Standard Template Library (STL) is a collection of templates implementing commonly used algorithms+other stuff (some algorithms were commonly used before the STL was created, and perhaps some are now commonly used because they are in the STL).
It is to be expected that most uses of templates will involve those defined in the STL, because these implement commonly used functionality, are documented and generally known about (code can only be reused when its existence is known about, and it has been written with reuse in mind).
The template instantiation measurements show a 17:1 ratio for STL vs. developer-defined templates (i.e., 149,591 vs. 8,887).
What are the usage characteristics of developer defined templates?
Around 25% of developer defined function templates are only instantiated once, while 15% of class templates are instantiated once.
Most templates are defined by a small number of developers. This is not surprising given that most of the code on a project is written by a small number of developers.
The plot below shows the percentage instantiations (of all developer defined function templates) of each developer defined function template, in rank order (code+data):
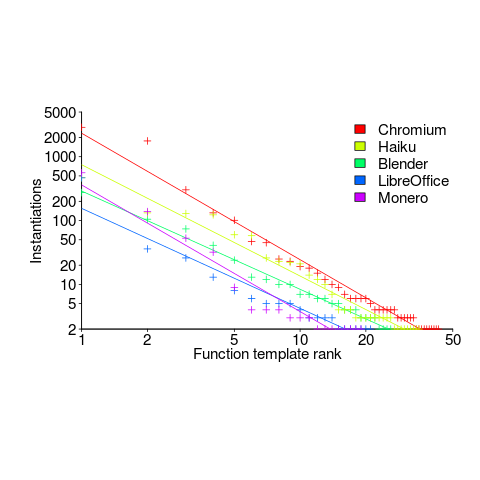
Lines are each a fitted power law, whose exponents vary between -1.5 and -2. Is it just me, or are these exponents surprising close?
The following is for developer defined class templates. Lines are fitted power law, whose exponents vary between -1.3 and -2.6. Not so close here.
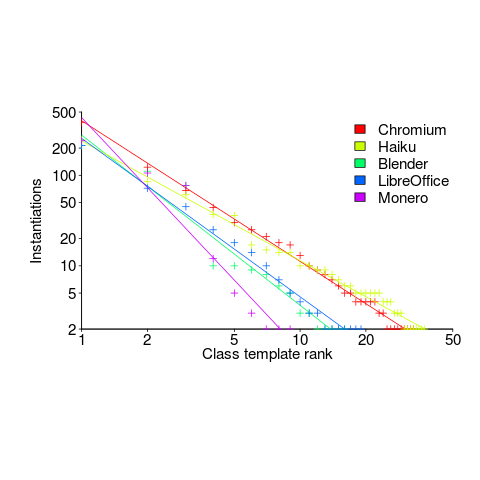
What processes are driving use of developer defined templates?
Every project has its own specific few templates that get used everywhere, by all developers. I imagine these are tailored to the project, and are widely advertised to developers who work on the project.
Perhaps some developers don’t define templates, because that’s not what they do. Is this because they work on stuff where templates don’t offer much benefit, or is it because these developers are stuck in their ways (if so, is it really worth trying to change them?)
Double exponential performance hit in C# compiler
Yesterday I was reading a blog post on the performance impact of using duplicated nested types in a C# generic class, such as the following:
class Class<A, B, C, D, E, F> { class Inner : Class<Inner, Inner, Inner, Inner, Inner, Inner> { Inner.Inner inner; } } |
Ah, the joys of exploiting a language specification to create perverse code 🙂
The author, Matt Warren, had benchmarked the C# compiler for increasing numbers of duplicate types; good man. However, the exponential fitted to the data, in the blog post, is obviously not a good fit. I suspected a double exponential might be a better fit and gave it a go (code+data).
Compile-time data points and fitted double-exponential below:
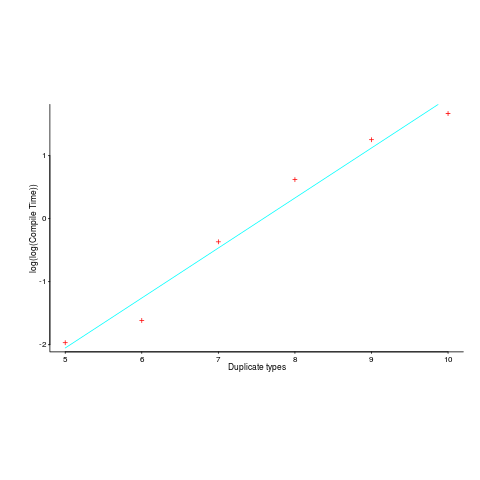
Yes, for compile time the better fit is:  and for binary size:
and for binary size:  , where
, where  ,
,  are some constants and
are some constants and  the number of duplicates.
the number of duplicates.
I had no idea what might cause this pathological compiler performance problem (apart from the pathological code) and did some rummaging around. No luck; I could not find any analysis of generic type implementation that might be used to shine some light on this behavior.
Ideas anybody?
Recent Comments