Archive
Stochastic rounding reemerges
Just like integer types, floating-point types are capable of representing a finite number of numeric values. An important difference between integer and floating types is that the result of arithmetic and relational operations using integer types is exactly representable in an integer type (provided they don’t overflow), while the result of arithmetic operations using floating types may not be exactly representable in the corresponding floating type.
When the result of a floating-point operation cannot be exactly represented, it is rounded to a value that can be represented. Rounding modes include: round to nearest (the default for IEEE-754), round towards zero (i.e., truncated), round up (i.e., towards  ), round down (i.e., towards
), round down (i.e., towards  ), and round to even. The following is an example of round to nearest:
), and round to even. The following is an example of round to nearest:
123456.7 = 1.234567 × 10^5
101.7654 = 0.001017654 × 10^5
Adding
= 1.235584654 × 10^5
Round to nearest
= 1.235585 × 10^5 |
There is another round mode, one implemented in the 1950s, which faded away but could now be making a comeback: Stochastic rounding. As the name suggests, every round up/down decision is randomly chosen; a Google patent makes some claims about where the entropy needed for randomness can be obtained, and Nvidia also make some patent claims).
From the developer perspective, stochastic rounding has a very surprising behavior, which is not present in the other IEEE rounding modes; stochastic rounding is not monotonic. For instance: z < x+y does not imply that 0<(x+y)-z, because x+y may be close enough to z to have a 50% chance of being rounded to one of z or the next representable value greater than z, and in the comparison against zero the rounded value of (x+y) has an uncorrelated probability of being equal to z (rather than the next representable greater value).
For some problems, stochastic rounding avoids undesirable behaviors that can occur when round to nearest is used. For instance, round to nearest can produce correlated rounding errors that cause systematic error growth (by definition, stochastic rounding is uncorrelated); a behavior that has long been known to occur when numerically solving differential equations. The benefits of stochastic rounding are obtained for calculations involving long chains of calculations; the rounding error of the result of  operations is guaranteed to be proportional to
operations is guaranteed to be proportional to  , i.e., just like a 1-D random walk, which is not guaranteed for round to nearest.
, i.e., just like a 1-D random walk, which is not guaranteed for round to nearest.
While stochastic rounding has been supported by some software packages for a while, commercial hardware support is still rare, with Graphcore's Intelligence Processing Unit being one. There are some research chips supporting stochastic rounding, e.g., Intel's Loihi.
What applications, other than solving differential equations, involve many long chain calculations?
Training of machine learning models can consume many cpu hours/days; the calculation chains just go on and on.
Machine learning is considered to be a big enough market for hardware vendors to support half-precision floating-point. The performance advantages of half-precision floating-point are large enough to attract developers to reworking code to make use of them.
Is the accuracy advantage of stochastic rounding a big enough selling point that hardware vendors will provide the support needed to attract a critical mass of developers willing to rework their code to take advantage of improved accuracy?
It's possible that the intrinsically fuzzy nature of many machine learning applications swamps the accuracy advantage that stochastic rounding can have over round to nearest, out-weighing the costs of supporting it.
The ecosystem of machine learning based applications is still evolving rapidly, and we will have to wait and see whether stochastic rounding becomes widely used.
Tools that help handle floating-point dragons
There be dragons is a common refrain in any discussion involving code containing floating-point. The dragons are not likely to disappear anytime soon, but there has been a lot of progress since my 2011 post and practical tools for handling them are starting to become available to developers who are not numerical analysts.
All the techniques contain an element of brute force, very many possibilities are examined (cloud computing is starting to have a big impact on how problems are attacked). All the cloud computing on the planet would not make a noticeable dent in any problem unless some clever stuff was done to drastically prune the search space.
My current favorite tool is Herbie, if only because of the blog posts describing some of the techniques used (it’s currently limited to code without loops; if you need loop support check out Rosa).
It’s all very well having the performance of your floating-point code optimized, but who is to say nasty problems are not lurking in unexplored ranges of the underlying formula. Without an Oracle capable of generating the correct answer (whatever that might be; Precimonious has to be provided with training inputs), the analysis can only flag what is considered to be suspicious behavior. Craft attempts to detect cancellation errors, S3FP searches for input values that produce results containing large relative error and Rangelab simply provides bounds on the output values calculated from whatever input it is fed.
Being interested in getting very accurate results is a niche market. Surprisingly inaccurate results are good enough for many people and perhaps we should be using a language designed for this market.
Perhaps the problem of efficiently and accurately printing floating-point numbers might finally have just been solved.
Tool for tuning the use of floating-point types
A common problem when writing code that performs floating-point arithmetic is figuring out which of the available three (usually) possible floating-point types to use (e.g., float, double or long double). Some language ‘solve’ this problem by only having one possibility (e.g., R) and some implementations of languages that offer three types use the same representation for all of them (e.g., 32 bits).
The type float often represents the least precision/range of values but occupies the smallest amount of storage and operations on it have traditionally been the fastest, type long double often represents the greatest precision/range of values but occupies the most storage and operations on it are generally the slowest. Applying the Goldilocks principle the type double is very often selected.
Anyone who has worked with floating-point values will be familiar with some of the ways they can bite very hard. Once a function that uses floating-point types is written the general advice is to leave it alone.
Precimonious is an interesting new tool that searches for possible performance/accuracy trade-offs; it randomly selects a floating-point declaration, changes the type used, executes the resulting program and compares the output against that produced by the original program. Users of the tool specify the maximum error (difference in output values) they are willing to accept and Precimonious searches for a combination of changes to the floating-point types contained within a program that result in a faster program that does not exceed this maximum error.
The performance improvements cited in the paper (which includes the doyen of floating-point in its long list of authors) cluster around zero and worthwhile double figure percentage (max 41.7%); sometimes no improvements were found until the maximum error was reduced from  to
to  .
.
Perhaps a combination of Precimonious and a tool that attempts to improve accuracy is the next step 🙂
There is resistance to using search based methods to fix faults. Perhaps tools like Precimonious will help developers get used to the idea of search assisted software development.
I wonder how long it will be before we see commentary in bug reports such as the following:
- that combination of values was not in the Precimonious test set,
- Precimonious cannot find a sufficiently optimized program within the desired error tolerance for that rarely seen combination of values. Won’t fix.
Superoptimizers are back in vogue
There has always been the need for a few developers with in-depth knowledge of a particular cpu architecture to sit down and think very hard about how best to implement a snippet of code performing some operation in assembly language, e.g., library implementors wanting the tightest code for a critical inner loop or compiler writers who need to map from intermediate code to machine code.
In 1987 Massalin published his now famous paper that introduced the term Superoptimizer; a program that enumerates all possible combinations of instruction sequences until the shortest/fastest one producing the desired output from the given input is found (various heuristics were used to prune the search space e.g., only considering 15 or so opcodes, and the longest sequence it ever generated contained 12 instructions).
While the idea was widely talked about, it never caught on in practice (a special purpose branch eliminator was produced for GCC; Hacker’s Delight also includes a stand-alone system). Perhaps the guild of mindbogglingly-obtuse-but-fast-instruction-sequences black-balled it (apprentices have to spend several years doing nothing but writing assembly code for their chosen architecture, thinking about how to make it go faster and/or be shorter and only talk to other apprentices/members and communicate with non-converts exclusively about their latest neat sequence), or perhaps it was just a case of not invented here (writing machine code used to be something that even run-of-the-mill developers got to do every now and again), or perhaps it was not considered cost-effective to build a superoptimizer for a given project (I don’t know of anyone offering a generic tool that could be tailored for specific cases) or perhaps developers were happy to just ride the wave of continually faster processors.
It was not until 2008 with Bansal’s thesis that superoptimizer research started to take off (as in paper publication rate increased from once every five years to more than one a year). Bansal found a new market, binary translation i.e., translating the binary of a program built to run on one kind of cpu to run on a different kind of cpu, for instance the Mac 68K emulator.
Bansal and other researchers’ work was oriented towards relatively short instruction sequences. To be really useful, some way of handling longer sequences was needed.
A few days ago Stochastic Superoptimization arrived on the scene (or rather a paper describing it became available for download). Schkufza, Sharma and Aiken use Markov chain Monte Carlo methods to sample the possible instruction sequences rather than generating all of them. The paper gives a 116 instruction example from which the author’s tool removed 16 lines to produce code that went 1.6 times faster (only 30 ‘core’ instructions were given in paper); what is also very interesting is that the tool operates on compiler generated output (gcc/llvm), suggesting the usage build program, profile it and then stochastic superoptimize the hot spots.
Markov chains and Monte Carlo methods are trendy topics that researchers like to write about, so we will certainly see more papers in this area.
These days few developers have had hands-on experience with machine code, so the depth of expertise that was once easy to find is now rare, processors have many more weird and wonderful instructions often interacting with older instructions in obscure ways, and the cpu architecture landscape continues to change regularly. The time may have arrived for superoptimizers to be widely used by industry.
Of course, superoptimizers can work at any level of abstraction, including expression trees built directly from some complicated floating-point calculation that needs to be optimized for accuracy or speed.
Initial impressions of RangeLab
I was rummaging around in the source of R looking for trouble, as one does, when I came across what I believed to be a less than optimally accurate floating-point algorithm (function R_pos_di in src/main/arithemtic.c). Analyzing the accuracy of floating-point code is notoriously difficult and those having the required skills tend to concentrate their efforts on what are considered to be important questions. I recently discovered RangeLab, a tool that seemed to be offering painless floating-point code accuracy analysis; here was an opportunity to try it out.
Installation went as smoothly as newly released personal tools usually do (i.e., some minor manual editing of Makefiles and a couple of tweaks to the source to comment out function calls causing link errors {mpfr_random and mpfr_random2}).
RangeLab works by analyzing the flow of values through a program to produce the set of output values and the error bounds on those values. Input values can be specified as a range, e.g., f = [1.0, 10.0] says f can contain any value between 1.0 and 10.0.
My first RangeLab program mimicked the behavior of the existing code in R_pos_di:
n=-10; f=[1.0, 10.0]; res = 1.0; if n < 0, n = -n; f = 1 / f; end while n ~= 0, if (n / 2)*2 ~= n, res = res * f; end n = n / 2; if n ~= 0, f = f*f; end end |
and told me that the possible range of values of res was:
res ans = float64: [1.000000000000001E-10,1.000000000000000E0] error: [-2.109423746787798E-15,2.109423746787799E-15] |
Changing the code to perform the divide last, rather than first, when the exponent is negative:
n=-10; f=[1.0, 10.0]; res = 1.0; is_neg = 0; if n < 0, n = -n; is_neg = 1 end while n ~= 0, if (n / 2)*2 ~= n, res = res * f end n = n / 2; if n ~= 0, f = f*f end if is_neg == 1, res = 1 / res end end |
and the error in res is now:
res ans = float64: [1.000000000000000E-10,1.000000000000000E0] error: [-1.110223024625156E-16,1.110223024625157E-16] |
Yea! My hunch was correct, moving the divide from first to last reduces the error in the result. I have reported this code as a bug in R and wait to see what the R team think.
Was the analysis really that painless? The Rangelab language is somewhat quirky for no obvious reason (e.g., why use ~= when everybody uses != these days and if conditionals must be followed by a character why not use the colon like Python does?) It would be real useful to be able to cut and paste C/C++/etc and only have to make minor changes.
I get the impression that all the effort went into getting the analysis correct and user interface stuff was a very distant second. This is the right approach to take on a research project. For some software to make the leap from interesting research idea to useful tool it is important to pay some attention to the user interface.
The current release does not deserve to be called 1.0 and unless you have an urgent need I would suggest waiting until the usability has been improved (e.g., error messages give some hint about what is wrong and a rough indication of which line the problem occurs on).
RangeLab has shown that there is simpler method of performing useful floating-point error analysis. With some usability improvements RangeLab would be an essential tool for any developer writing code involving floating-point types.
Update: The R team, in the form of Martin Maechler, resolved my report in just over 14 hours! The function R_pos_di is not called, the pow function from the C library (which takes two double arguments rather than a double and an int) has been found to be more accurate. Martin says this usage is not less accurate even for n=3, which I find surprising; I agree it should be more accurate for large values of n.
pow is one of the more complicated maths functions, involving finding a log, a multiply and then returning the exponent of this result. There are lots of boundary values that need to be checked and the code goes on for a while. I will wait for the usability of RangeLab to improve before attempting to compare its accuracy against the simpler algorithm for integer powers. Looking at the SunOracle library sources, if both arguments have integral values the ‘integer power’ algorithm is used (with the divide performed last).
Optimizing floating-point expressions for accuracy
Floating-point arithmetic is one topic that most compiler writers tend to avoid as much as possible. The majority of programs don’t use floating-point (i.e., low customer demand), much of the analysis depends on the range of values being operated on (i.e., information not usually available to the compiler) and a lot of developers don’t understand numerical methods (i.e., keep the compiler out of the blame firing line by generating code that looks like what appears in the source).
There is a scientific and engineering community whose software contains lots of floating-point arithmetic, the so called number-crunchers. While this community is relatively small, many of the problems it works on attract lots of funding and some of this money filters down to compiler development. However, the fancy optimizations that appear in these Fortran compilers (until the second edition of the C standard in 1999 Fortran did a much better job of handling the minutia of floating-point arithmetic) are mostly about figuring out how to distribute the execution of loops over multiple functional units (i.e., concurrent execution).
The elephant in the floating-point evaluation room is result accuracy. Compiler writers know they have to be careful not to throw away accuracy (e.g., optimizing out what appear to be redundant operations in the Kahan summation algorithm), but until recently nobody had any idea how to go about improving the accuracy of what had been written. In retrospect one accuracy improvement algorithm is obvious, try lots of possible combinations of the ways in which an expression can be written and pick the most accurate.
There are lots of ways in which the operands in an expression can be paired together to be operated on; some of the ways of pairing the operands in a+b+c+d include (a+b)+(c+d), a+(b+(c+d)) and (d+a)+(b+c) (unless the source explicitly includes parenthesis compilers for C, C++, Fortran and many other languages (not Java which is strictly left to right) are permitted to choose the pairing and order of evaluation). For n operands (assuming the operators have the same precedence and are commutative) the number is combinations is  where
where  is the n’th Catalan number. For 5 operands there are 1680 combinations of which 120 are unique and for 10 operands
is the n’th Catalan number. For 5 operands there are 1680 combinations of which 120 are unique and for 10 operands  of which
of which  are unique.
are unique.
A recent study by Langlois, Martel and Thévenoux analysed the accuracy achieved by all unique permutations of ten operands on four different data sets. People within the same umbrella project are now working on integrating this kind of analysis into a compiler. This work is another example of the growing trend in compiler research of using the processing power provided by multiple cores to use algorithms that were previously unrealistic.
Over the last six years or so there has been lot of very interesting floating-point work going on in France, with gcc and llvm making use of the MPFR library (multiple-precision floating-point) for quite a while. Something very new and interesting is RangeLab which, given the lower/upper bounds of each input variable to a program (a simple C-like language) computes the range of the outputs as well as ranges for the roundoff errors (the tool assumes IEEE floating-point arithmetic). I now know that over the range [800, 1000] the expression x*(x+1) is a lot more accurate than x*x+x.
Update: See comment from @Eric and my response below.
Automatically improving code
Compared to 20 or 30 years ago we know a lot more about the properties of algorithms and better ways of doing things often exist (e.g., more accurate, faster, more reliable, etc). The problem with this knowledge is that it takes the form of lots and lots of small specific details, not the kind of thing that developers are likely to be interested in, or good at, remembering. Rather than involve developers in the decision-making process, perhaps the compiler could figure out when to substitute something better for what had actually been written.
While developers are likely to be very happy to see what they have written behaving as accurately and reliably as they had expected (ignorance is bliss), there is always the possibility that the ‘less better’ behavior of what they had actually written had really been intended. The following examples illustrate two relatively low level ‘improvement’ transformations:
- this case is probably a long-standing fault in many binary search and merge sort functions; the relevant block of developer written code goes something like the following:
while (low <= high) { int mid = (low + high) / 2; int midVal = data[mid]; if (midVal < key) low = mid + 1 else if (midVal > key) high = mid - 1; else return mid; }
The fault is in the expression
(low + high) / 2which overflows to a negative value, and returns a negative value, if the number of items being sorted is large enough. Alternatives that don’t overflow, and that a compiler might transform the code to, include:low + ((high - low) / 2)and(low + high) >>> 1. - the second involves summing a sequence of floating-point numbers. The typical implementation is a simple loop such as the following:
sum=0.0; for i=1 to array_len sum += array_of_double[i];
which for large arrays can result in
sumlosing a great deal of accuracy. The Kahan summation algorithm tries to take account of accuracy lost in one iteration of the loop by compensating on the next iteration. If floating-point numbers were represented to infinite precision the following loop could be simplified to the one above:sum=0.0; c=0.0; for i = 1 to array_len { y = array_of_double[i] - c; // try to adjust for previous lost accuracy t = sum + y; c = (t - sum) - y; // try and gets some information on lost accuracy sum = t; }
In this case the additional accuracy is bought at the price of a decrease in performance.
Compiler maintainers are just like other workers in that they want to carry on working at what they are doing. This means they need to keep finding ways of improving their product, or at least improving it from the point of view of those willing to pay for their services.
Many low level transformations such as the above two examples would be not be that hard to implement, and some developers would regard them as useful. In some cases the behavior of the code as written would be required, and its transformed behavior would be surprising to the author, while in other cases the transformed behavior is what the developer would prefer if they were aware of it. Doesn’t it make sense to perform the transformations in those cases where the as-written behavior is least likely to be wanted?
Compilers already do things that are surprising to developers (often because the developer does not fully understand the language, many of which continue to grow in complexity). Creating the potential for more surprises is not that big a deal in the overall scheme of things.
Searching for inaccurate literals in R
In creating the numbers tool I wanted to be able to do two things, 1) obtain information about what source did by matching the numeric literals it contained against a database of ‘interesting’ values (now with over 14,000 entries) and 2) flag possible incorrect numeric literals (e.g., 3.1459265 when 3.14159265 had been intended in core/Helix.cpp of the MIFit source {now fixed}).
I have recently been enhancing ‘incorrect numeric literal’ support and using the latest release of R as a test bed (whose floating-point literals are almost identical to the last release I looked at, R-2.11.1, log file here).
The first fault I found (0.20403... instead of 0.020403...) looked very serious until I realised it was involved in calculating an initial value feed into an iterative algorithm (at worst causing an extra iteration or so). It looks like the developer overlooked the “e-1” that appears in the original (click on ‘Page 48’).
The second possible problem turned out to be an ambiguity in the file main/color.c which contains the comment “CIE-XYZ to sRGB” above three expressions that perform a conversion from CIE-XYZ to BT.709 RGB. Did the developer get the comment or the numeric literals wrong? People are known to confuse the two forms of RGB (for an explanation see Annex B) .
Apart from a few minor errors such as 0.950301 instead of 0.9503041 (in …/grDevices/R/postscript.R) nothing else of interest turned up so I shifted attention to the add-on packages available on the Comprehensive R Archive Network.
The 3,000+ packages occupy almost 2 Gig in compressed form (fortunately numbers can operate directly on compressed archives and the files did not need to be unpacked) and I decided to limit the analysis to just the R source files, which cut the number of floating-point literals down to around 2 million (after ignoring the contents of comments, 10M compressed log file here).
The various floating-point literals having a value close to 2.30258509299404568402 (the most common match; no idea why the value ln(10) or 1/log(e) should be so popular) highlight the various issues that crop up when using approximate matching to look for faults. The following are some of these matches (first number is total occurrences, second sequence is the literal appearing in the source with dot denoting the same digit as in the number matched against):
92 ........ 2.30258509299404568402 ln(10) or 1/log(e) 5 ...............5 2.30258509299404568402 ln(10) or 1/log(e) 1 .....80528052805 2.30258509299404568402 ln(10) or 1/log(e) 3 .....6 2.30258509299404568402 ln(10) or 1/log(e) 2 .....67 2.30258509299404568402 ln(10) or 1/log(e) 1 .....38 2.30258509299404568402 ln(10) or 1/log(e) 2 .....8 2.30258509299404568402 ln(10) or 1/log(e) 1 .....42 2.30258509299404568402 ln(10) or 1/log(e) 2 ......7 2.30258509299404568402 ln(10) or 1/log(e) 2 ......2 2.30258509299404568402 ln(10) or 1/log(e) 1 ....... 2.30258509299404568402 ln(10) or 1/log(e) 2 .....6553 2.30258509299404568402 ln(10) or 1/log(e) 1 .......4566 2.30258509299404568402 ln(10) or 1/log(e)
Most of those 92 seven digit matches occur in a subdirectory called data implying that they do not occur within code expressions, while .....80528052805 contains enough extra trailing non-matching digits to suggest a different value really was intended. Are there enough unmatched trailing digits in .....6553 to consider it a different value? More experience needs to be gained before attempting to make this call automatically.
At the moment a person has to look at the code containing these ‘close’ values to decide whether the author made a mistake or really did mean to use the value given (unfortunately numbers does not yet have a fancy gui to simplify this task). Sometimes the literals appear in data and other times in an expression that requires domain knowledge to figure out whether it is correct or not. My cursory sampling of the very large data set did not find any serious problems.
Some of the unmatched literals contain so few significant digits they would match many entries in a database of ‘interesting’ values. For instance the numbers database used to contain 745.0, the mean radius of the minor planet Sedna (according to the latest NASA data), but it was removed because of the large number of false positive matches it generated.
Many of the unmatched literals appear to do not appear to have any special interest outside of code that contains them, for instance 0.2.
I am hoping that readers of this blog will download numbers and run their code through it. They might find some faults in their code and add new values to their local ‘interesting’ numbers database to target their own application domain(not forgetting to email me a copy to include in the next release). Suggestions for improving the detection of inaccurate literals always welcome (check to the TODO file first).
An interesting observation from comparing the mathematical equations in the book Computation of Special Functions with the Fortran source provided by its authors is that when a ‘known’ constant (e.g., pi, pi/2) appears in isolation (e.g., as an argument or a value in an assignment) its literal representation often contains as many digits as supported in 64-bits, while when the same constant appears within an expression evaluating a polynomial it often contains the same number of digits as the other literals appearing in that expression (which is usually less than supported in 64-bits).
Quality comparison of floating-point maths libraries
What is the best way to compare the quality of floating-point math libraries (e.g., sin, cos and log)? The traditional approach for evaluating the quality of an algorithm implementing a mathematical function is based on mathematics; methods have been developed to calculate the maximum error between the calculated and the actual value. The answer produced by this approach does not say anything about how frequently this maximum error will occur, only that it occurs at least once.
The log (natural logarithm) is probably the most frequently used mathematical function and I decided to compare a few implementations; R statistical package version 2.11.1 and glibc (libm version 2.11.2) both running under Suse 11.3 on an AMD Athlon 64 X2, and Cygwin version 1.7.1 under Windows XP SP 2 on another AMD Athlon 64 X2.
The algorithm often used to implement mathematical functions involves evaluating a polynomial expression (e.g., Chebyshev polynomials) within a small range of values (various methods are used to map the argument into this range and then scale the calculated result). I decided to initially treat the implementations under test as black boxes and did not know the ranges they used; a range of 0.1 to 1.0 seemed like a good idea and I generated all single precision floating-point values between these two bounds (all 28,521,267 of them, with each adjacent pair still having  double precision values between them).
double precision values between them).
#include <math.h> #include <stdio.h> int main(int argc, char *argv[]) { float val = 0.1, max_val = 1.0; while (val < max_val) { printf("%12.10f\n", val); val=nextafterf(val, 1.1); } } |
This list of 28 million values was fed as input to three programs:
- bc, which was used to generate the list of assumed to be correct logarithm of these 28 million values. R supports 64-bit IEEE compliant floating-point values, as do the C compilers/libraries used, and the number of decimal digits supported in this representation is 15. To provide greater accuracy to compare against the values generated by bc contained 17 digits, an extra two decimal digits over the IEEE values.
scale=17 while ((val=read() > 0)) l(val)
- A C program.
#include <math.h> #include <stdio.h> int main(int argc, char *argv[]) { double val; while (!feof(stdin)) { scanf("%lf", &val); printf("%17.15f\n", log(val)); } }
- A R program.
base_range=file("stdin", open="r") base_val=as.numeric(readLines(base_range, n=1)) while (length(base_val) != 0) { cat(format(log(base_val), nsmall=15), file=stdout()) cat("\n", file=stdout()) base_val=as.numeric(readLines(base_range, n=1)) }
The output of the C and R programs was then compared against the output from bc; which unfortunately creates a dependency on the accuracy of the C & R binary to decimal output routines (the subsequent comparison process gets around the decimal-to-binary input problem by reading the log values as strings and comparing the last few digits of each respective value). Accurate floating-point I/O needs something like hexadecimal floating constants.
Plotting the number of computed values of log that differ by a given amount from the value computed by bc, we get (values whose error is below -50 will be rounded down and those above 50 rounded up, ignoring the issue of round to even):
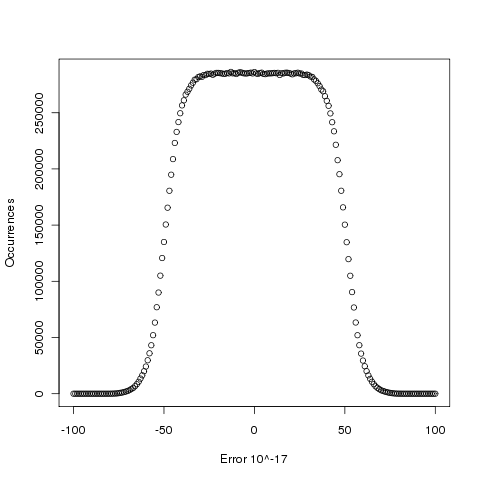
The results (raw data for R, Linux C and Cygwin C) show that around 5.6% of values are off by one in the last (15th) digit (Cygwin was slightly worse at 5.7%). The results for R/Linux C were almost identical and a quick check of the R source tree showed that R calls the C library function to evaluate log (it is a bit worrying that R is dependent on the host maths library, they should think about replacing this dependency by something like MPFR tout suite; even though the 64-bit glibc library is of very high quality it still has an environmental dependency).
Being off by one in the last decimal place is unlikely to keep many people awake at night. But if we want a measure of quality, is percentage of inaccurate values a useful measure of math library quality? Provided it is coupled with the amount of inaccuracy, I think this is a useful measure.
Number of digits in floating-point literals
Some of the interesting floating-point literals detected by the numbers program not only look uninteresting but plain wrong. For instance, almost every program I analyze appears to contain a literal denoting the ratio of the diameter of the Earth to at least one minor planet. One problem is that most of the numbers contained in the interesting number database are only likely to occur in very specific circumstances and as the size of this database grows the percentage of inappropriate matches grows.
I could (and at some point probably will have to) assign an interestingness level to numbers, but this goes against one of the original aims of identifying the operations performed by unknown source.
An alternative idea is to create a connection between the fuzziness of the matching process and the probability of the literal being encountered in code. For instance, a more exact match might be required for 0.5 because it contains few mantissa digits and sits within a range of values that are commonly encountered, while a much fuzzier match might be used for 1.879623e+3 because it contains more digits and occupies a less commonly encountered range of values.
Floating-point literals often contain leading or trailing zeros, e.g., 0.001, 100.0, 1e+2
or 0.50. Does the presence of these zeros change the probability of a particular mantissa being encountered? For instance the literals 100.0 and 1e+2 have the same numeric value but different numbers of mantissa digits.
Another issue is developer intent. Why did a developer write 0.50, did they simply want two digits to appear after the decimal point because the surrounding literals in the source contain two digits and it makes the visual appearance look better or does this usage denote a quantity whose accuracy is known to two decimal digits?
The following figure is derived from 1 million non-zero floating-point literals contained in ten large, computationally intensive programs.
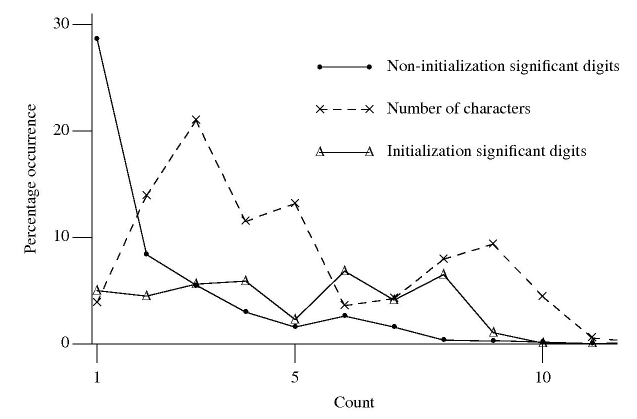
The dashed line denotes the percentage of mantissas containing a given number of characters, including leading/trailing zeros and any decimal point.
The two solid lines denote the digit count of the mantissas with any leading/trailing zeros removed, along with any decimal point, e.g., both 100.0 and 1e+2 would be considered to contain one digit.
It seemed to me that floating-point literals appearing within an initializer attached to a variable definition often contain more digits than literals that appear elsewhere. The solid, triangle tagged, solid line that spends most of its time around 5% are floating-point literals appearing within an initializer (to be exact they are literals separated from another literal by a comma {with some simplistic handling of Fortran line continuation}). The bullet tagged line are all other literals.
I was partially right about the characteristics of floating-point literals in initializers. It turns out the probability of encountering a mantissa containing a given number of digits is approximately constant within an initializer (a more sophisticated analysis might show an upward trend with increasing numbers of digits).
The mantissa digit count outside of initializers has the kind of probability distribution I was looking for. Hopefully this distribution will contribute to a useful measure of interestingness.
Recent Comments