Archive
Readability: a scientific approach
Readability, as applied to software development today, is a meaningless marketing term. Readability is promoted as a desirable attribute, and is commonly claimed for favored programming languages, particular styles of programming, or ways of laying out source code.
Whenever somebody I’m talking to, or listening to in a talk, makes a readability claim, I ask what they mean by readability, and how they measured it. The speaker invariably fumbles around for something to say, with some dodging and weaving before admitting that they have not measured readability. There have been a few studies that asked students to rate the readability of source code (no guidance was given about what readability might be).
If somebody wanted to investigate readability from a scientific perspective, how might they go about it?
The best way to make immediate progress is to build on what is already known. There has been over a century of research on eye movement during reading, and two model of eye movement now dominate, i.e., the E-Z Reader model and SWIFT model. Using eye-tracking to study developers is slowly starting to be adopted by researchers.
Our eyes don’t smoothly scan the world in front of us, rather they jump from point to point (these jumps are known as a saccade), remaining fixed long enough to acquire information and calculate where to jump next. The image below is an example from an eye tracking study, where subjects were asking to read a sentence (see figure 770.11). Each red dot appears below the center of each saccade, and the numbers show the fixation time (in milliseconds) for that point (code):

Models of reading are judged by the accuracy of their predictions of saccade landing points (within a given line of text), and fixation time between saccades. Simulators implementing the E-Z Reader and SWIFT models have found that these models have comparable performance, and the robustness of these models are compared by looking at the predictions they make about saccade behavior when reading what might be called unconventional material, e.g., mirrored or scarmbeld text.
What is the connection between the saccades made by readers and their understanding of what they are reading?
Studies have found that fixation duration increases with text difficulty (it is also affected by decreases with word frequency and word predictability).
It has been said that attention is the window through which we perceive the world, and our attention directs what we look at.
A recent study of the SWIFT model found that its predictions of saccade behavior, when reading mirrored or inverted text, agreed well with subject behavior.
I wonder what behavior SWIFT would predict for developers reading a line of code where the identifiers were written in camelCase or using underscores (sometimes known as snake_case)?
If the SWIFT predictions agreed with developer saccade behavior, a raft of further ‘readability’ tests spring to mind. If the SWIFT predictions did not agree with developer behavior, how might the model be updated to support the reading of lines of code?
Until recently, the few researchers using eye tracking to investigate software engineering behavior seemed to be having fun playing with their new toys. Things are starting to settle down, with some researchers starting to pay attention to existing models of reading.
What do I predict will be discovered?
Lots of studies have found that given enough practice, people can become proficient at handling some apparently incomprehensible text layouts. I predict that given enough practice, developers can become equally proficient at most of the code layout schemes that have been proposed.
The important question concerning text layout, is: which one enables an acceptable performance from a wide variety of developers who have had little exposure to it? I suspect the answer will be the one that is closest to the layout they have had the most experience,i.e., prose text.
Eye-tracking of developers reading code is now in start-up mode
Readability has always been the meaningless go to attribute for designers of new languages and code restructuring techniques that needed a worthy sounding benefit to tout.
Market researchers, being more interested in empirical data than arm-waving, have been long time users of eye-tracking technology; gaze direction providing a direct link to where cognitive attention is being invested.
Over the last few years, a small number of researchers have started measuring where software developers look when they read code. Analysing and interpreting data on eye movement while reading code is still in start-up mode. One group has started collecting data that others can use, the obligatory R packages (saccade, gazepath and itsadug) and Python library now exist, and the eye-movement in programming conference has its third meeting in November.
Apart from one tantalizing image (see below, code+data here, original research paper+data) my book should arrive too soon to say anything useful about code readability based on eye-tracking data.

It has taken several decades for researchers to create reasonably reliable models of attention and eye-movement for reading text. Code reading adds vertical eye-movement to the horizontal movements that occur when reading text; the models are probably going to be a lot more complicated. I discussed a few of the issues in my first book (the E-Z Reader model is still one of the top performers).
Accurately tracking eye motion during software development is technically difficult. Until recently obtaining the necessary accuracy required keeping the subject’s head fixed (achieved by having subjects clamp their teeth on a bite bar); somewhat impractical for developers wanting to view a large screen. Accurately tracking what developers are looking at requires tracking both head and eye motion. The necessary hardware is coming down in price, but still contains one too many zeroes for me to buy one to play with (I was given an Intel RealSense at a hackathon, now I just need the software…).
Next time somebody claims that so-and-so is more readable, ask them what eye-tracking research has to say on the subject.
Readability: we know nothing
Readability is one of those terms that developers use and expect other developers to understand while at the same time being unable to define what it is or how it might be measured. I think all developers would agree that their own code is very readable; if only different developers stopped writing code in different ways the issue would go away 🙂
Having written a book containing lots of material on cognitive psychology and how it might apply to programming, developers who have advanced beyond “Write code like me and it will be readable” sometimes ask for my perceived expert view on the subject. Unfortunately my expertise has only advanced to the stage of: 1) having a good idea of what research questions need to be addressed, 2) being able to point at experimental results showing that most claimed good readability tips are at best worthless or may even increase cognitive load during reading.
To a good approximation we know nothing about code readability. What questions need to answered to change this situation?
The first and most important readability question is: what is the purpose of looking at the code? Is the code being read to gain understanding (likely to involve ‘slow’ and deliberate behavior) or is the reader searching for some construct (likely to involve skimming; yes, slow and deliberate is more accurate but people make cost/benefit decisions when deciding which strategies to use. The factors involved in reader strategy selection is another important question)?
Next we need to ask what characteristics of developer performance are expected to change with different code organization/layouts. Are we interested in minimizing error, minimizing the time taken to achieve the readers purpose or something else?
What source code attributes play a significant role in readability? Possibilities include the order in which various constructs appear (e.g., should variable definitions appear at the start of a function or close to where they are first used), variable names and the position of tokens relative to each other when viewed by the reader.
Questions involving the relative position of tokens probably generates the greatest volume of discussion among developers. To what extent does visual organization of source code affect reader performance? Fluent reading requires a significant amount of practice, perhaps readable code is whatever developers have spent lots of time reading.
If there is some characteristic of the human visual system that generates a worthwhile benefit to splitting long lines so that a binary operator appears at the {end of the last}/{start of the next} line, will it apply the same way to all developers? We could end up developers having to configure their editor so it displays code in a form that matches the characteristics of their visual system.
How might these ‘visual’ questions be answered? I think that eye tracking will play a large role (“Eyetracking Web Usability” by Jakob Nielsen and Kara Pernice is a good read). At the moment there are technical/usability issues that make this kind of research very difficult. Eye trackers capable of continuously supporting enough resolution to know which character on the screen a developer is looking at (e.g., EyeLink 1000) require that the head be held in a fixed position, while those allowing completely free head movement (e.g., S2 Eye Tracker) don’t yet continuously support the required resolution.
Of course any theory derived from eye tracking experiments will still have to be validated by measuring developer performance on various code snippets.
Measuring developer coding expertise
A common measure of developer experience is the number of years worked. The only good that can be said about this measure is that it is easy to calculate. Studies of experts in various fields have found that acquiring expertise requires a great deal of deliberate practice (10,000 hours is often quoted at the amount of practice put in by world class experts).
I think that coding expertise is acquired by reading and writing code, but I have little idea of the relative contributions made by reading and writing and whether reading the same code twice count twice or is there a law of diminishing returns on rereading code?
So how much code have developers read and written during their professional lives? Some projects have collected information on the number of ‘delivered’ lines of code written by developers over some time period. How many lines does a developer actually write for every line delivered (some functions may be rewritten several times while others may be deleted without every being making it into a final delivery)? Nobody knows. As for lines of code read, nobody has previously expressed an interest in collecting this kind of information.
Some experiments, involving professional developers, I have run take as their starting point that developer performance improves with practice. Needing some idea of the amount of practice my subjects have had reading and writing code I asked them to tell me how much code they think they have read and written, as well as the number of years they have worked professionally in software development.
The answers given by my subjects were not very convincing:
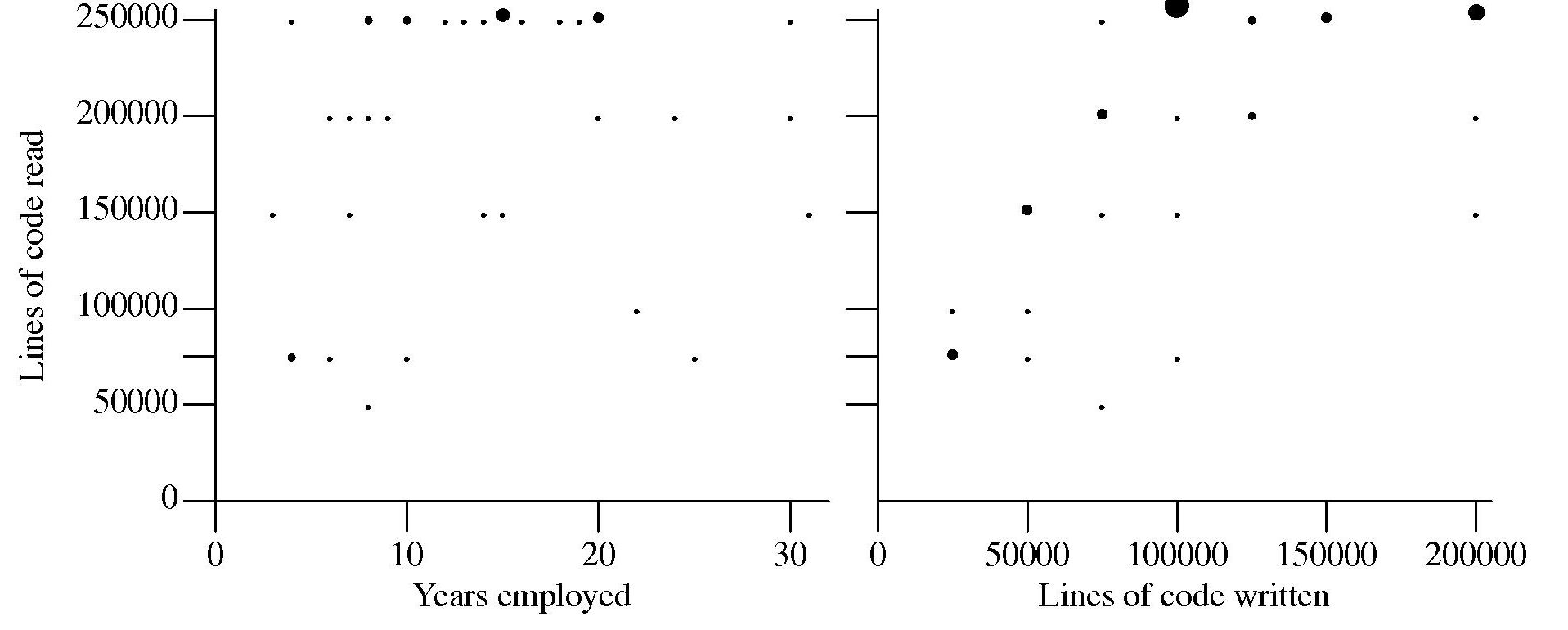
Estimates of the ratio code read/written varied by more than five to one (the above graph suffers from a saturation problem for lines of code read, I had not provided a tick box that was greater than 250,000). I cannot complain, my subjects volunteered part of their lunch time to take part in an experiment and were asked to answer these questions while being given instructions on what they were being asked to do during the experiment.
I have asked this read/written question a number of times and received answers that exhibit similar amounts of uncertainty and unlikeliness. Thinking about it I’m not sure that giving subjects more time to answer this question would improve the accuracy of the answers. Very few developers monitor their own performance. The only reliable way of answering this question is by monitoring developer’s eye movements as they interact with code for some significant duration of time (preferably weeks).
Unobtrusive eye trackers may not be sufficiently accurate to provide a line-of-code level of resolution and the more accurate head mounted trackers are a bit intrusive. But given their price more discussion on this topic is currently of little value 🙁
Recent Comments