Archive
Premium mediocrity is software engineering’s demographic
Software engineering is one of the skills needed to write software, but outside of student coursework is rarely an end in itself. Software is written to do something and the person writing the code needs to know about the something.
If enough people are involved in something, a job title gets created by inserting the appropriate application domain name before ‘software engineer’, e.g., the something software engineer; systems software engineering was one of the first recorded uses of ‘software engineering’, ’embedded software engineer’ is a common usage and more recently ‘research software engineer’ has been trending.
Customers want the software systems they use to fulfill their needs. Implementing a software system involves figuring out what the needs are, how best to implement them using the available resources and producing usable software; all within a given amount of time and money.
How much software engineering knowledge and skill does a something software engineer need? The obvious answer is: enough to get the something done. Ok, how much is needed to get the something done?
There are so many hours in a day: what percentage of available time is best spent learning about software engineering, what percentage leaning about the something and what percentage doing rather than learning?
The only data I have for answering this question is my own experience of talking to people, from a wide range of business and application areas, whose job includes writing software. My background is compilers (from C to Cobol) and static analysis, my knowledge of end-user application domains is derived from talking to the developers who were using the compilers or static analysis tools I was working on at the time.
I have always been struck by the minimalist knowledge of most developers, when it comes to the programming language they were using. It took a while, but eventually I accepted the obvious: most developers don’t need to know much about the language they are using to get their job done.
By a process that resembles incentivized trial and error, people learn how to write code that does what they want; the compiler does not complain and the output looks ok. For some languages, I used to be able to work out which books a relatively new developer had used to guide their learning, by matching a book’s example code snippets with the code they had written.
This minimalist knowledge approach to programming languages is cost effective because most code is simple and has a short lifetime; the cost of learning lots of language details does not provide enough benefit to be worthwhile.
I am a minimalist language Python developer. Why would I spend time learning more about the semantics of Python than I need to?
What are the benefits of being a language expert? Compiler writers get paid to learn the ins and outs of a language and I know a few people who became language experts without being compiler writers (they got hooked on knowing the language). I have found it useful for keeping my code simple (I am not tempted to write complicate code, or use obscure constructs, in the mistaken belief that they are better than the simple stuff), it is also useful for figuring out other people’s complicated or obscure usage (created intentionally or accidentally).
These benefits are not enough to convince me to learn more about Python, the language. I am content to wait until I need to learn more.
I have occasionally taught advanced programming courses, aimed at developers with a few years experience working in industry. These courses had to include the word ‘advanced’ in their title, otherwise developers with a few years experience would never have signed-up; ‘advanced’ is a necessary marketing signal (others who have run such courses report the same behavior). The course contents were essentially a review of basic material, with lots of examples; most of those attending did not know enough to follow real advanced material. The courses were really about uncovering and correcting bad habits that attendees had picked up over time (often, a technique was discovered to fix a problem and then subsequently adopted for more general use).
What about general software engineering skills? A minimalist knowledge approach to software engineering is cost effective because most code does not exist long enough to make it worthwhile investing in reducing future maintenance costs. Yes, it is more expensive for those that survive to become commonly used, but think of all the savings from not investing in those that did not survive. Software engineering decisions should not be driven by surviorship bias.
The first requirement of any commercial software system is to attract paying customers. In a rapidly changing market, being first with a saleable product can be the difference between life and death. Minimizing software engineering effort saves time and money (in the short term). If the product is a success, there will be money to pay for what needs to be done, if the product fails nobody cares. I have seen a lot of software systems that are a commercial success and a complete software engineering mess; successful, well engineered software is less common (or perhaps they just don’t need me to help them out).
Software engineering mediocrity is not only viable, for most people it’s the outcome of making a cost/benefit decision to invest their learning time in the application domain, not software engineering (or computer language).
Of course, nobody wants to be seen as being mediocre (for some people, mediocre overstates their skill level); their behavior is premium mediocre.
There are a few application areas where software engineering skills are needed, e.g., safety critical software and warehouse scale computing. A few high profile cases are hiding the reality that whatever works is cost effective for most software solutions.
Habits are the peripheral vision of the mind
Achieving a basic proficiency in a new skill requires an investment of conscious cognitive effort, i.e., thinking a lot. Students are constantly in the process of achieving basic proficiency in new skills and conclude that thinking is required for all intellectual activities (an incorrect assumption also held by many teachers).
To get past the conscious thinking stage lots of time has to be spent performing the skill. Repetition provides the opportunity for performance via conscious thought to migrate to subconscious performance (driving being a common example).
Real-time performance requires fluency, that is, being able to handle technical details without having to think about them. Thinking (i.e., conscious thought) is slow and requires lots of effort. It is best held in reserve for the important stuff.
To paraphrase Alfred Whitehead: “Software development advances by extending the number of important operations which we can perform without thinking about them.”
Somebody who has spent 100 hours or so (an hour or two a week for a year) learning to code has the same level of fluency as I have in communicating in a foreign language using a phrase book, or Google translate.
After a 1,000 hours of programming a person should be a very fluent coder.
It is said that becoming an expert requires 10,000 hours of practice. The kind of practice involved is deliberate practice, not unconscious use of what is already known. Becoming an expert requires learning lots of new things, not constantly applying what is already known. Old habits have to be broken and new ones acquired.
Programming is not Zen, although it contains elements that are. Why would a developer want to create a program without conscious thought (that is what scripts are for)?
I used to run ‘advanced’ programming courses for professional developers with 2+ years in industry. In many ways the material was a rerun of what they had learned at the start of their programming career. The difference was that this time around they could ignore the mechanics of writing code, now an ingrained habit, and concentrate on the higher level stuff. The course had to have advanced in its title because experienced developers would never sign up for an introductory course. Most of my one-on-one tutoring effort went on talking people out of bad habits they had picked up over time.
Perhaps live coding can be done with a Zen mind, probably why I don’t regard it as real programming (which I think requires some conscious thought).
Talking about details and high level material in the same breath is what beginners do because they have not yet learned to tell the two apart and be able to ignore one of them.
Like life, programs are mostly built from sequences of commonly occurring patterns. Our minds have evolved to subconsciously detect and take advantage of patterns. Programmers don’t know what the common source code patterns are any more than a native speaker can specify the syntax rules of the language they speak.
A local CS reading group
Paper Cup, a reading group for computer science papers recently started, based about 30 minutes from me I decided to go along to the first meeting to see what it was like.
The paper under discussion was: Dynamo: Amazon’s Highly Available Key-value Store. I don’t know much about databases and and have never written code that uses a key-store, but since the event was hosted by guys at ebay/PayPal I figured there would be somebody in the room who knew what they were talking about.
The idea behind a paper reading group is that everybody agrees to read a paper before the meeting, then turns up at the meeting and discusses it.
The list of authors takes up three lines and their affiliation is simply listed as Amazon.com. As a subject matter outsider who probably reads several hundred papers a year my overall impression was that this paper was relatively information free and was more or less a puff-piece for Amazon. On the other hand it currently has 1,562 citations, a lot more than would be expected for a puff-piece paper published in 2007. I was obviously missing something.
Around 10 people showed up, with a handful sounding very knowledgeable and one person working on a new ‘Dynamo like’ implementation. Several replies to my question of what was so good about this paper, that appeared relatively content free to me, gave the reason that they were inspired by it. Wow, very few scientific papers ever inspire anybody.
The group worked its way through the paper and I tried to nod intelligently at the right time. This is one of those papers that requires lots of reading between the lines, an activity that requires lots of background knowledge and hands-on experience (as an outsider I was only reading the surface text).
I asked if one of the reasons this paper was considered to be important was because it described a commercial implementation rather than a research project. Any design team is much more likely to use techniques outlined in a paper describing a working commercial system than techniques operating in some toy academic environment (papers on Cassandra were appearing at about the same time). I’m not sure the relatively young attendees understood the importance of this point.
The take-away interesting snippet of information: Dynamo gives preference to performance over consistency, if a customer’s shopping basket key-value store becomes inconsistent then information on items added to the basket take precedence over items deleted from the basket (a sensible choice for a retailer such as Amazon).
If you live near west London and are interested in discussing CS paper do join the Paper Cup meetup group, the more the merrier.
Most developers don’t really know any computer language
What does it mean to know a language? I can count to ten in half a dozen human languages, say please and thank you, tell people I’m English and a few other phrases that will probably help me get by; I don’t think anybody would claim that I knew any of these languages.
It is my experience that most developers’ knowledge of the programming languages they use is essentially template based; they know how to write a basic instances of the various language constructs such as loops, if-statements, assignments, etc and how to define identifiers to have a small handful of properties, and they know a bit about how to glue these together.
There are many developers who can skilfully weave together useful programs from the hodgepodge of coding knowledge they happen to know (proving that little programming knowledge is needed to write useful programs).
The purpose of this post is not to complain about developers’ lack of knowledge of the programming languages they use; I appreciate that time spent learning about the application domain often gives a better return on investment compared to learning more about a language. The purpose is to suggest that the programming language community (e.g., teachers and tool producers) acknowledge how languages are primarily used and go with the flow rather than maintaining the fiction that developers know anything much about the languages they use and that they should acquire this knowledge to expert level; students should be taught the commonly encountered templates, not the general language rules, developers should be encouraged to use just the common templates (this will also have the side effect of reducing the effort needed to follow other peoples code since the patterns of usage will be familiar to many).
I suspect that many readers will disagree with the statement in this post’s title, and I need to provide more evidence before proposing (in another post) how we might adapt to the reality to be found in development teams.
The only evidence I can offer is my own experience; not a very satisfactory situation; a possible measurement approach discussed below. So what is this experience based evidence (I only claim to ‘know’ the handful of language I have written compiler front ends for, with other languages my usage follows the template form just like everybody else)?
- discussions with developers: individuals and development groups invariably have their own terminology for programming language constructs (my use of terminology appearing in the language definition usually draws blank stares and I have to make a stab at guessing what the local terms mean and using them if I want to be listened to); asking about identifier scoping or type compatibility rules (assuming that either of the terms ‘scope’ or ‘type compatibility’ is understood) usually results in a vague description of specific instances (invariably the commonly encountered situations),
- books that claim to teach a language often provide superficial coverage of the language semantics and concentrate on usage examples (because that is what is useful to their readers). Those books claiming to give insight into the depths of a language often contains many mistakes; perhaps the most well known example is Herbert Schildt’s “The Annotated ANSI C Standard”, Clive Feather’s review of the 1995 edition and Peter Seebach’s review of later versions,
- the word ‘Advanced’ has to appear in programming courses for professional developers with 3–10 years of experience because potential customers think they have reached an advanced level. In practice, such courses teach the basics and get away with it because most of the attendees don’t know them. My own experiences of teaching such courses is that outside of the walking people through the slides, the real teaching is about trying to undo some of the bad habits and misconceptions individuals have picked up over the years.
Recent graduate think they are an expert in the language used on their course because they probably have not met anybody who knows a lot more; some professional developers think they are language experts because the have lots of years of experience, in practice they tend to have spent those years essentially using what they originally learned and are now very adept with that small subset.
How might we measure the program language knowledge of the general developer population?
Software development question/answer sites such as Stack Overflow contain a wealth of information. I think I could write a function that did a reasonably good job of deducing the programming language, if any, being used in the question. Given the language definition (in some cases this might not exist, e.g., Perl and PHP) and the answers to the question of how do I figure out the language expertise of the person who wrote the answer?
First, we need to filter out those questions that are application related, with code being incidental. Latent Semantic Indexing could be used to locate the strongest connections between parts of the language specification and the non-source code answer text. If strong connections are found, the question would be assumed to be programming language related.
Developers only need surface knowledge to sprinkle any answer with phrases related to the language referred to; more in depth analysis is needed.
One idea is to process any code in the question/answer with a compiler capable of generating references to those parts of the language definition used during its semantic processing (ideally ‘part’ would be the sentence level, but I would settle for paragraph level or perhaps couple of paragraph level). A non-trivial overlap between the ‘parts’ references returned by the two searches would be a good indicator of programming language question. The big problem with this idea is complete lack of compilers supporting this language reference functionality (somebody please prove me wrong).
I am currently stumped for a practical technique for a non-superficial way of measuring developer language expertise. The 2013 Mining Software Repositories challenge is based on a dump of the questions/answers from Stack Overflow, I’m looking forward to seeing what useful information researchers extract from it.
Measuring developer coding expertise
A common measure of developer experience is the number of years worked. The only good that can be said about this measure is that it is easy to calculate. Studies of experts in various fields have found that acquiring expertise requires a great deal of deliberate practice (10,000 hours is often quoted at the amount of practice put in by world class experts).
I think that coding expertise is acquired by reading and writing code, but I have little idea of the relative contributions made by reading and writing and whether reading the same code twice count twice or is there a law of diminishing returns on rereading code?
So how much code have developers read and written during their professional lives? Some projects have collected information on the number of ‘delivered’ lines of code written by developers over some time period. How many lines does a developer actually write for every line delivered (some functions may be rewritten several times while others may be deleted without every being making it into a final delivery)? Nobody knows. As for lines of code read, nobody has previously expressed an interest in collecting this kind of information.
Some experiments, involving professional developers, I have run take as their starting point that developer performance improves with practice. Needing some idea of the amount of practice my subjects have had reading and writing code I asked them to tell me how much code they think they have read and written, as well as the number of years they have worked professionally in software development.
The answers given by my subjects were not very convincing:
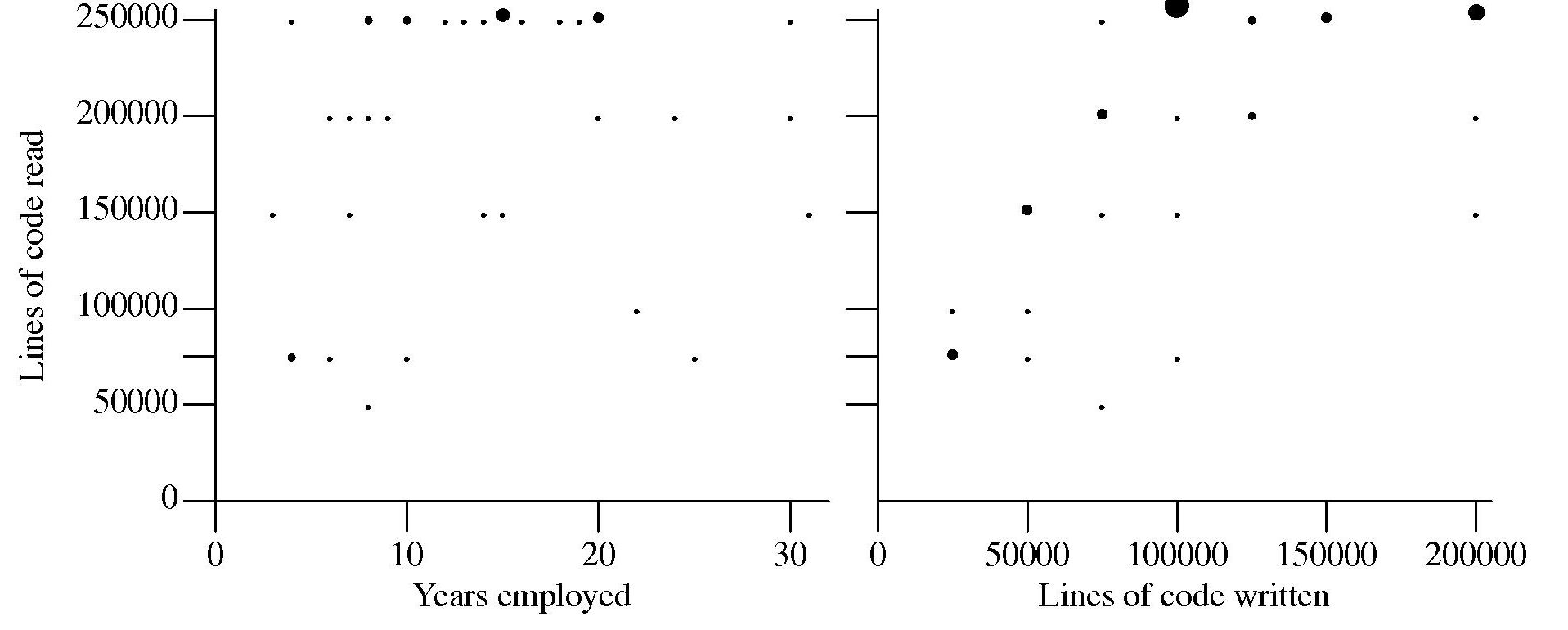
Estimates of the ratio code read/written varied by more than five to one (the above graph suffers from a saturation problem for lines of code read, I had not provided a tick box that was greater than 250,000). I cannot complain, my subjects volunteered part of their lunch time to take part in an experiment and were asked to answer these questions while being given instructions on what they were being asked to do during the experiment.
I have asked this read/written question a number of times and received answers that exhibit similar amounts of uncertainty and unlikeliness. Thinking about it I’m not sure that giving subjects more time to answer this question would improve the accuracy of the answers. Very few developers monitor their own performance. The only reliable way of answering this question is by monitoring developer’s eye movements as they interact with code for some significant duration of time (preferably weeks).
Unobtrusive eye trackers may not be sufficiently accurate to provide a line-of-code level of resolution and the more accurate head mounted trackers are a bit intrusive. But given their price more discussion on this topic is currently of little value 🙁
Criteria for knowing a language
What does it mean for somebody to claim to know a computer language? In the commercial world it means the person is claiming to be capable of fluently (i.e., only using knowledge contained in their head and without having to unduly ponder) reading, and writing code in some generally accepted style applicable to that language. The academic world generally sets a much lower standard of competence (perhaps because most of its inhabitants leave before any significant expertise is acquired). If I had a penny for every recent graduate who claimed to know a language and was incapable of writing a program that read in a list of integers and printed their sum (I know companies that set tougher problems, but they do not seem to have higher failure rates), I would be a rich man.
One experiment asked 21 postgraduate and academic staff which of the following individuals they would regard as knowing Java:
The results were:
_ NO YES
A 21 0
B 18 3
C 16 5
D 8 13
E 0 21
These answers reflect the environment from which the subjects were drawn. When I wrote compilers for a living, I did not consider that anybody knew a language unless they had written a compiler for it, a point of view echoed by other compiler writers I knew.
I’m not sure that commercial developers would be happy with answer (E), in fact they could probably expand (E) into five separate questions that tested the degree to which a person was able to combine various elements of the language to create a meaningful whole. In the commercial world, stage (E) is where people are expected to start.
The criteria used to decide whether somebody knows a language depends on which group of people you talk to; academics, professional developers and compiler writers each have their own in-group standards. In a sense the question is irrelevant, a small amount of language knowledge applied well can be used to do a reasonable job of creating a program for most applications.
Recent Comments