Archive
An experiment involving matching regular expressions
Recommendations for/against particular programming constructs have one thing in common: there is no evidence backing up any of the recommendations. Running experiments to measure the impact of particular language features on developer performance is not something that researchers do (there have been a handful of experiments looking at the impact of strong typing on developer performance; the effect measured was tiny).
In February I discovered two groups researching regular expressions. In the first post on duplicate regexs, I promised to say something about the second group. This post discusses an experiment comparing developer comprehension of various regular expressions; the paper is: Exploring Regular Expression Comprehension.
The experiment involved 180 workers on Mechanical Turk (to be accepted, workers had to correctly answer four or five questions about regular expressions). Workers/subjects performed two different tasks, matching and composition.
- In the matching task workers saw a regex and a list of five strings, and had to specify whether the regex matched (or not) each string (there was also an unsure response).
- In the composition task workers saw a regular expression, and had to create a string matched by this regex. Each worker saw 10 different regexs, which were randomly drawn from a set of 60 regexs (which had been created to be representative of various regex characteristics). I have not analysed this data yet.
What were the results?
For the matching task: given each of the pairs of regexs below, which one (of each pair) would you say workers were most likely to get correct?
R1 R2 1. tri[a-f]3 tri[abcdef]3 2. no[w-z]5 no[wxyz]5 3. no[w-z]5 no(w|x|y|z)5 4. [ˆ0-9] [\D] |
The percentages correct for (1) were essentially the same, at 94.0 and 93.2 respectively. The percentages for (2) were 93.3 and 87.2, which is odd given that the regex is essentially the same as (1). Is this amount of variability in subject response to be expected? Is the difference caused by letters being much less common in text, so people have had less practice using them (sounds a bit far-fetched, but its all I could think of). The percentages for (3) are virtually identical, at 93.3 and 93.7.
The percentages for (4) were 58 and 73.3, which surprised me. But then I have been using regexs since before \D support was generally available. The MTurk generation have it easy not having to use the ‘hard stuff’ 😉
See Table III in the paper for more results.
This matching data might be analysed using Item Response theory, which can take into account differences in question difficulty and worker/subject ability. The plot below looks complicated, but only because there are so many lines. Each numbered colored line is a different regex, worker ability is on the x-axis (greater ability on the right), and the y-axis is the probability of giving a correct answer (code+data; thanks to Peipei Wang for fixing the bugs in my code):
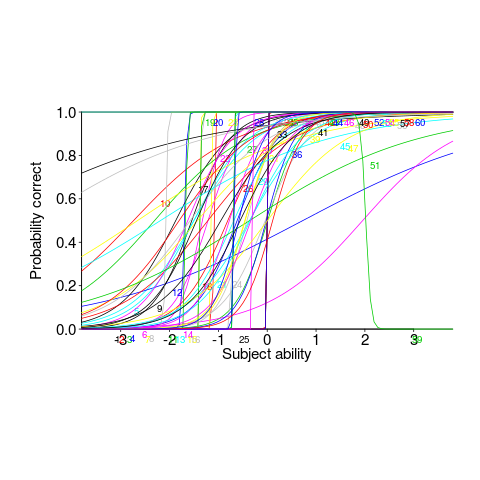
Yes, for question 51 the probability of a correct answer decreases with worker ability. Heads are being scratched about this.
There might be some patterns buried in amongst all those lines, e.g., particular kinds of patterns require a given level of ability to handle, or correct response to some patterns varying over the whole range of abilities. These are research questions, and this is a blog article: answers in the comments 🙂
This is the first experiment of its kind, so it is bound to throw up more questions than answers. Are more incorrect responses given for longer regexs, particularly if they cannot be completely held in short-term memory? It is convenient for the author to use a short-hand for a range of characters (e.g., a-f), and I was expecting a difference in performance when all the letters were enumerated (e.g., abcdef); I had theories for either one being less error-prone (I obviously need to get out more).
How useful are automatically generated compiler tests?
Over the last decade, testing compilers using automatically generated source code has been a popular research topic (for those working in the compiler field; Csmith kicked off this interest). Compilers are large complicated programs, and they will always contain mistakes that lead to faults being experienced. Previous posts of mine have raised two issues on the use of automatically generated tests: a financial issue (i.e., fixing reported faults costs money {most of the work on gcc and llvm is done by people working for large companies}, and is intended to benefit users not researchers seeking bragging rights for their latest paper), and applicability issue (i.e., human written code has particular characteristics and unless automatically generated code has very similar characteristics the mistakes it finds are unlikely to commonly occur in practice).
My claim that mistakes in compilers found by automatically generated code are unlikely to be the kind of mistakes that often lead to a fault in the compilation of human written code is based on the observations (I don’t have any experimental evidence): the characteristics of automatically generated source is very different from human written code (I know this from measurements of lots of code), and this difference results in parts of the compiler that are infrequently executed by human written code being more frequently executed (increasing the likelihood of a mistake being uncovered; an observation based on my years working on compilers).
An interesting new paper, Compiler Fuzzing: How Much Does It Matter?, investigated the extent to which fault experiences produced by automatically generated source are representative of fault experiences produced by human written code. The first author of the paper, Michaël Marcozzi, gave a talk about this work at the Papers We Love workshop last Sunday (videos available).
The question was attacked head on. The researchers instrumented the code in the LLVM compiler that was modified to fix 45 reported faults (27 from four fuzzing tools, 10 from human written code, and 8 from a formal verifier); the following is an example of instrumented code:
warn ("Fixing patch reached"); if (Not.isPowerOf2()) { if (!(C-> getValue().isPowerOf2() // Check needed to fix fault && Not != C->getValue())) { warn("Fault possibly triggered"); } else { /* CODE TRANSFORMATION */ } } // Original, unfixed code |
The instrumented compiler was used to build 309 Debian packages (around 10 million lines of C/C++). The output from the builds were (possibly miscompiled) built versions of the packages, and log files (from which information could be extracted on the number of times the fixing patches were reached, and the number of cases where the check needed to fix the fault was triggered).
Each built package was then checked using its respective test suite; a package built from miscompiled code may successfully pass its test suite.
A bitwise compare was run on the program executables generated by the unfixed and fixed compilers.
The following (taken from Marcozzi’s slides) shows the percentage of packages where the fixing patch was reached during the build, the percentages of packages where code added to fix a fault was triggered, the percentage where a different binary was generated, and the percentages of packages where a failure was detected when running each package’s tests (0.01% is one failure):
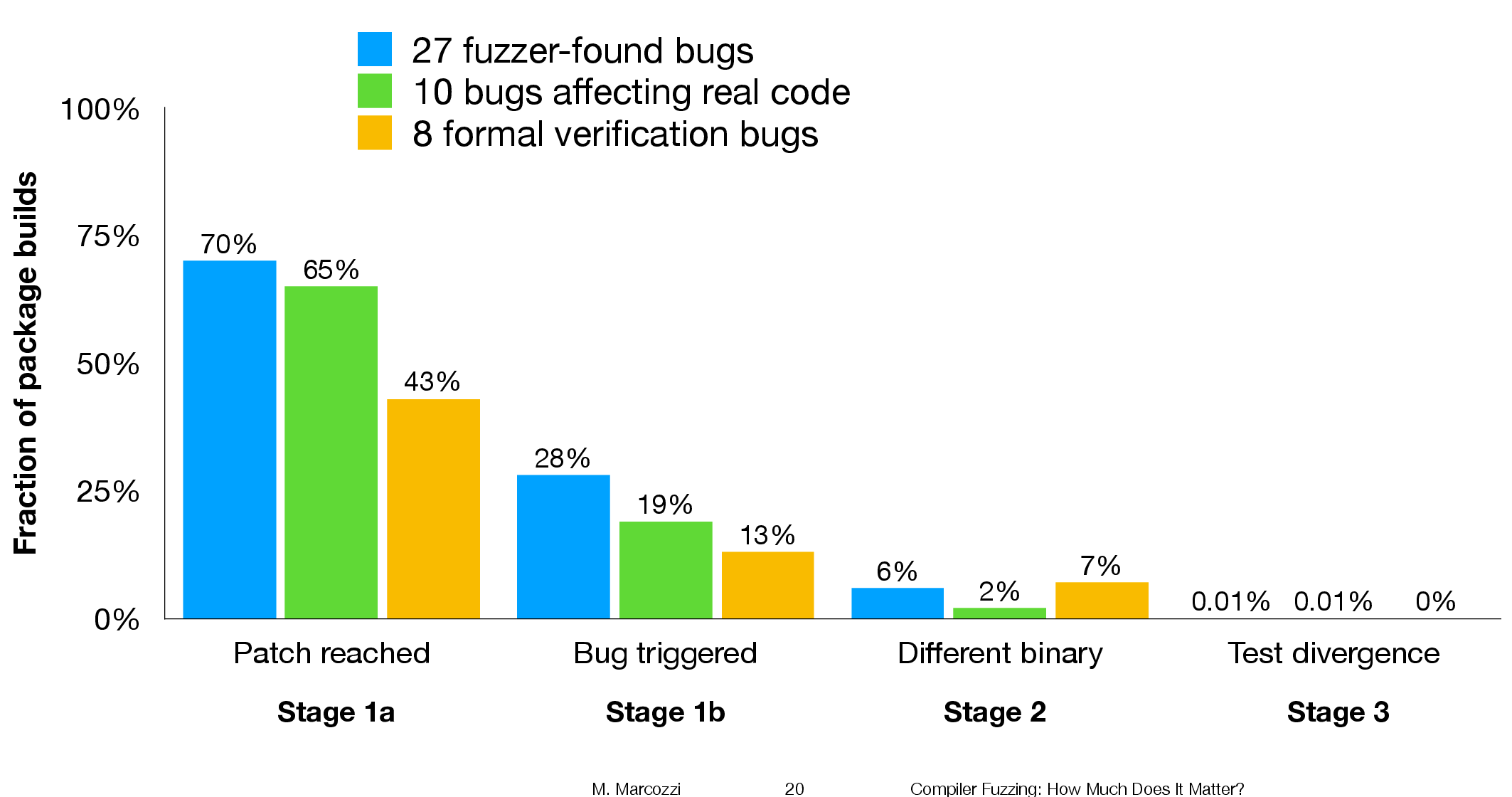
The takeaway from the above figure is that many packages are affected by the coding mistakes that have been fixed, but that most package test suites are not affected by the miscompilations.
To find out whether there is a difference, in terms of impact on Debian packages, between faults reported in human and automatically generated code, we need to compare the number of occurrences of “Fault possibly triggered”. The table below shows the break-down by the detector of the coding mistake (i.e., Human and each of the automated tools used), and the number of fixed faults they contributed to the analysis.
Human, Csmith and EMI each contributed 10-faults to the analysis. The fixes for the 10-fault reports in human generated code were triggered 593 times when building the 309 Debian packages, while each of the 10 Csmith and EMI fixes were triggered 1,043 and 948 times respectively; a lot more than the Human triggers :-O. There are also a lot more bitwise compare differences for the non-Human fault-fixes.
Detector Faults Reached Triggered Bitwise-diff Tests failed Human 10 1,990 593 56 1 Csmith 10 2,482 1,043 318 0 EMI 10 2,424 948 151 1 Orange 5 293 35 8 0 yarpgen 2 608 257 0 0 Alive 8 1,059 327 172 0 |
Is the difference due to a few packages being very different from the rest?
The table below breaks things down by each of the 10-reported faults from the three Detectors.
Ok, two Human fault-fix locations are never reached when compiling the Debian packages (which is a bit odd), but when the locations are reached they are just not triggering the fault conditions as often as the automatic cases.
Detector Reached Triggered
Human
300 278
301 0
305 0
0 0
0 0
133 44
286 231
229 0
259 40
77 0
Csmith
306 2
301 118
297 291
284 1
143 6
291 286
125 125
245 3
285 16
205 205
EMI
130 0
307 221
302 195
281 32
175 5
122 0
300 295
297 215
306 191
287 10 |
It looks like I am not only wrong, but that fault experiences from automatically generated source are more (not less) likely to occur in human written code (than fault experiences produced by human written code).
This is odd. At best, I would expect fault experiences from human and automatically generated code to have the same characteristics.
Ideas and suggestions welcome.
Update: the morning after
I have untangled my thoughts on how to statistically compare the three sets of data.
The bootstrap is based on the idea of exchangeability; which items being measured might we consider to be exchangeable, i.e., being able to treat the measurement of one as being the equivalent to measuring the other.
In this experiment, the coding mistakes are not exchangeable, i.e., different mistakes can have different outcomes.
But we might claim that the detection of mistakes is exchangeable; that is, a coding mistake is just as likely to be detected by source code produced by an automatic tool as source written by a Human.
The bootstrap needs to be applied without replacement, i.e., each coding mistake is treated as being unique. The results show that for the sum of the Triggered counts (code+data):
- treating Human and Csmith as being equally likely to detect the same coding mistake, there is a 18% change of the Human results being lower than 593.
- treating Human and EMI as being equally likely to detect the same coding mistake, there is a 12% change of the Human results being lower than 593.
So the likelihood of the lower value, 593, of Human Triggered events is expected to occur quite often (i.e., 12% and 18%). Automatically generated code is not more likely to detect coding mistakes than human written code (at least based on this small sample set).
Three books discuss three small data sets
During the early years of a new field, experimental data relating to important topics can be very thin on the ground. Ever since the first computer was built, there has been a lot of data on the characteristics of the hardware. Data on the characteristics of software, and the people who write it, has been (and often continues to be) very thin on the ground.
Books are sometimes written by the researchers who produce the first data associated with an important topic, even if the data set is tiny; being first often generates enough interest for a book length treatment to be considered worthwhile.
As a field progresses lots more data becomes available, and the discussion in subsequent books can be based on findings from more experiments and lots more data
Software engineering is a field where a few ‘first’ data books have been published, followed by silence, or rather lots of arm waving and little new data. The fall of Rome has been followed by a 40-year dark-age, from which we are slowly emerging.
Three of these ‘first’ data books are:
- “Man-Computer Problem Solving” by Harold Sackman, published in 1970, relating to experimental data from 1966. The experiments investigated the impact of two different approaches to developing software, on programmer performance (i.e., batch processing vs. on-line development; code+data). The first paper on this work appeared in an obscure journal in 1967, and was followed in the same issue by a critique pointing out the wide margin of uncertainty in the measurements (the critique agreed that running such experiments was a laudable goal).
Failing to deal with experimental uncertainty is nothing compared to what happened next. A 1968 paper in a widely read journal, the Communications of the ACM, contained the following table (extracted from a higher quality scan of a 1966 report by the same authors, and available online).
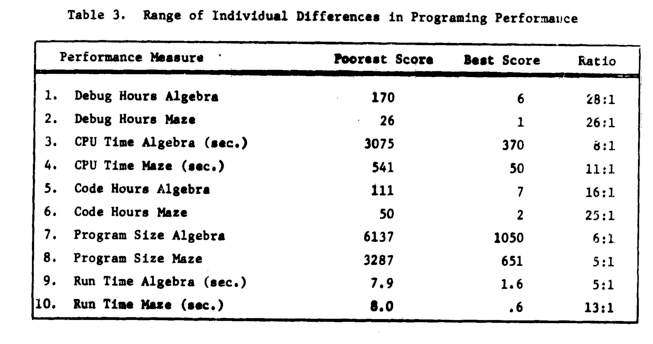
The tale of 1:28 ratio of programmer performance, found in an experiment by Grant/Sackman, took off (the technical detail that a lot of the difference was down to the techniques subjects’ used, and not the people themselves, got lost). The Grant/Sackman ‘finding’ used to be frequently quoted in some circles (or at least it did when I moved in them, I don’t know often it is cited today). In 1999, Lutz Prechelt wrote an expose on the sorry tale.
Sackman’s book is very readable, and contains lots of details and data not present in the papers, including survey data and a discussion of the intrinsic uncertainties associated with the experiment; it also contains the table above.
- “Software Engineering Economics” by Barry W. Boehm, published in 1981. I wrote about the poor analysis of the data contained in this book a few years ago.
The rest of this book contains plenty of interesting material, and even sounds modern (because books moving the topic forward have not been written).
- “Program Evolution: Process of Software Change” edited by M. M. Lehman and L. A. Belady, published in 1985, relating to experimental data from 1977 and before. Lehman and Belady managed to obtain data relating to 19 releases of an IBM software product (yes, 19, not nineteen-thousand); the data was primarily the date and number of modules contained in each release, plus less specific information about number of statements. This data was sliced and diced every which way, and the book contains many papers with the same data appearing in the same plot with different captions (had the book not been a collection of papers it would have been considerably shorter).
With a lot less data than Isaac Newton had available to formulate his three laws, Lehman and Belady came up with five, six, seven… “laws of software evolution” (which themselves evolved with the publication of successive papers).
The availability of Open source repositories means there is now a lot more software system evolution data available. Lehman’s laws have not stood the test of more data, although people still cite them every now and again.
How much is a 1-hour investment today worth a year from now?
Today, I am thinking of investing 1-hour of effort adding more comments to my code; how much time must this investment save me X-months from now, for today’s 1-hour investment to be worthwhile?
Obviously, I must save at least 1-hour. But, the purpose of making an investment is to receive a greater amount at a later time; ‘paying’ 1-hour to get back 1-hour is a poor investment (unless I have nothing else to do today, and I’m likely to be busy in the coming months).
The usual economic’s based answer is based on compound interest, the technique your bank uses to calculate how much you owe them (or perhaps they owe you), i.e., the expected future value grows exponentially at some interest rate.
Psychologists were surprised to find that people don’t estimate future value the way economists do. Hyperbolic discounting provides a good match to the data from experiments that asked subjects to value future payoffs. The form of the equation used by economists is:  , while hyperbolic discounting has the form
, while hyperbolic discounting has the form  , where:
, where:  is a constant, and
is a constant, and  the period of time.
the period of time.
The simple economic approach does not explicitly include the risk that one of the parties involved may cease to exist. Including risk is non-trivial, banks handle the risk that you might disappear by asking for collateral, or adding something to the interest rate charged.
The fact that humans, and some other animals, have been found to use hyperbolic discounting suggests that evolution has found this approach, to discounting time, increases the likelihood of genes being passed on to the next generation. A bird in the hand is worth two in the bush.
How do software developers discount investment in software engineering projects?
The paper Temporal Discounting in Technical Debt: How do Software Practitioners Discount the Future? describes a study that specifies a decision that has to be made and two options, as follows:
“You are managing an N-years project. You are ahead of schedule in the current iteration. You have to decide between two options on how to spend our upcoming week. Fill in the blank to indicate the least amount of time that would make you prefer Option 2 over Option 1.
- Option 1: Implement a feature that is in the project backlog, scheduled for the next iteration. (five person days of effort).
- Option 2: Integrate a new library (five person days effort) that adds no new functionality but has a 60% chance of saving you person days of effort over the duration of the project (with a 40% chance that the library will not result in those savings).
”
Subjects are then asked six questions, each having the following form (for various time frames):
“For a project time frame of 1 year, what is the smallest number of days that would make you prefer Option 2? ___”
The experiment is run twice, using professional developers from two companies, C1 and C2 (23 and 10 subjects, respectively), and the data is available for download 🙂
The following plot shows normalised values given by some of the subjects from company C1, for the various time periods used (y-axis shows  ). On a log scale, values estimated using the economists exponential approach would form a straight line (e.g., close to the first five points of subject M, bottom right), and values estimated using the hyperbolic approach would have the concave form seen for subject C (top middle) (code+data).
). On a log scale, values estimated using the economists exponential approach would form a straight line (e.g., close to the first five points of subject M, bottom right), and values estimated using the hyperbolic approach would have the concave form seen for subject C (top middle) (code+data).
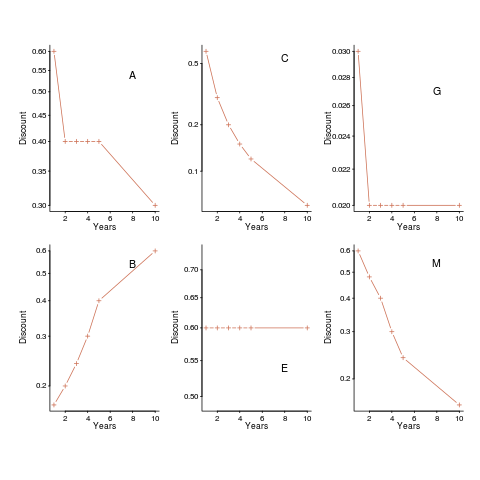
Subject B is asking for less, not more, over a longer time period (several other subjects have the same pattern of response). Why did Subject E (and most of subject G’s responses) not vary with time? Perhaps they were tired and were not willing to think hard about the problem, or perhaps they did not think the answer made much difference. The subjects from company C2 showed a greater amount of variety. Company C1 had some involvement with financial applications, while company C2 was involved in simulations. Did this domain knowledge spill over into company C1’s developers being more likely to give roughly consistent answers?
The experiment was run online, rather than an experimenter being in the room with subjects. It is possible that subjects would have invested more effort if a more formal setting, with an experimenter who had made the effort to be present. Also, if an experimenter had been present, it would have been possible to ask question to clarify any issues.
Both exponential and hyperbolic equations can be fitted to the data, but given the diversity of answers, it is difficult to put any weight in either regression model. Some subjects clearly gave responses fitting a hyperbolic equation, while others gave responses fitted approximately well by either approach, and other subjects used. It was possible to fit the combined data from all of company C1 subjects to a single hyperbolic equation model (the most significant between subject variation was the value of the intercept); no such luck with the data from company C2.
I’m very please to see there has been a replication of this study, but the current version of the paper is a jumble of ideas, and is thin on experimental procedure. I’m sure it will improve.
What do we learn from this study? Perhaps that developers need to learn something about calculating expected future payoffs.
Modular vs. monolithic programs: a big performance difference
For a long time now I have been telling people that no experiment has found a situation where the treatment (e.g., use of a technique or tool) produces a performance difference that is larger than the performance difference between the subjects.
The usual results are that differences between people is the source of the largest performance difference, successive runs are the next largest (i.e., people get better with practice), and the smallest performance difference occurs between using/not using the technique or tool.
This is rather disheartening news.
While rummaging through a pile of books I had not looked at in many years, I (re)discovered the paper “An empirical study of the effects of modularity on program modifiability” by Korson and Vaishnavi, in “Empirical Studies of Programmers” (the first one in the series). It’s based on Korson’s 1988 PhD thesis, with the same title.
There were four experiments, involving seven people from industry and nine students, each involving modifying a 900(ish)-line program in some way. There were two versions of each program, they differed in that one was written in a modular form, while the other was monolithic. Subjects were permuted between various combinations of program version/problem, but all problems were solved in the same order.
The performance data (time to complete the task) was published in the paper, so I fitted various regressions models to it (code+data). There is enough information in the data to separate out the effects of modular/monolithic, kind of problem and subject differences. Because all subjects solved problems in the same order, it is not possible to extract the impact of learning on performance.
The modular/monolithic performance difference was around twice as large as the difference between subjects (removing two very poorly performing subjects reduces the difference to 1.5). I’m going to have to change my slides.
Would the performance difference have been so large if all the subjects had been experienced developers? There is not a lot of well written modular code out there, and so experienced developers get lots of practice with spaghetti code. But, even if the performance difference is of the same order as the difference between developers, that is still a very worthwhile difference.
Now there are lots of ways to write a program in modular form, and we don’t know what kind of job Korson did in creating, or locating, his modular programs.
There are also lots of ways of writing a monolithic program, some of them might be easy to modify, others a tangled mess. Were these programs intentionally written as spaghetti code, or was some effort put into making them easy to modify?
The good news from the Korson study is that there appears to be a technique that delivers larger performance improvements than the difference between people (replication needed). We can quibble over how modular a modular program needs to be, and how spaghetti-like a monolithic program has to be.
Impact of group size and practice on manual performance
How performance varies with group size is an interesting question that is still an unresearched area of software engineering. The impact of learning is also an interesting question and there has been some software engineering research in this area.
I recently read a very interesting study involving both group size and learning, and Jaakko Peltokorpi kindly sent me a copy of the data.
That is the good news; the not so good news is that the experiment was not about software engineering, but the manual assembly of a contraption of the experimenters devising. Still, this experiment is an example of the impact of group size and learning (through repeating the task) on time to complete a task.
Subjects worked in groups of one to four people and repeated the task four times. Time taken to assemble a bespoke, floor standing rack with some odd-looking connections between components was measured (the image in the paper shows something that might function as a floor standing book-case, if shelves were added, apart from some component connections getting in the way).
The following equation is a very good fit to the data (code+data). There is theory explaining why ") applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
applies, but the division by group-size was found by suck-it-and-see (in another post I found that time spent planning increased with teams size).
There is a strong repetition/group-size interaction. As the group size increases, repetition has less of an impact on improving performance.
![time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_981.5_b0d171bba046801a68ce5dc8ae1d6115.png "time = 0.16+ 0.53/{group size} - log(repetitions)*[0.1 + {0.22}/{group size}]")
The following plot shows one way of looking at the data (larger groups take less time, but the difference declines with practice), lines are from the fitted regression model:
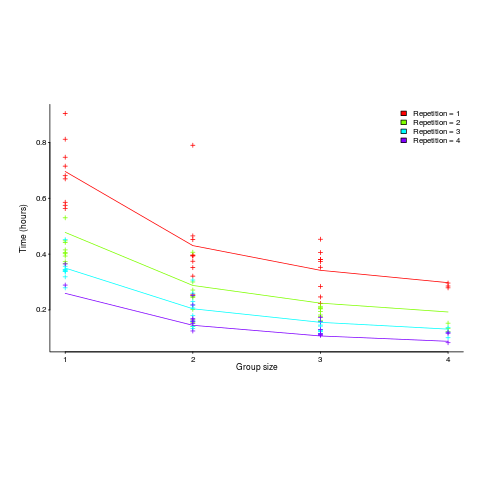
and here is another (a group of two is not twice as fast as a group of one; with practice smaller groups are converging on the performance of larger groups):
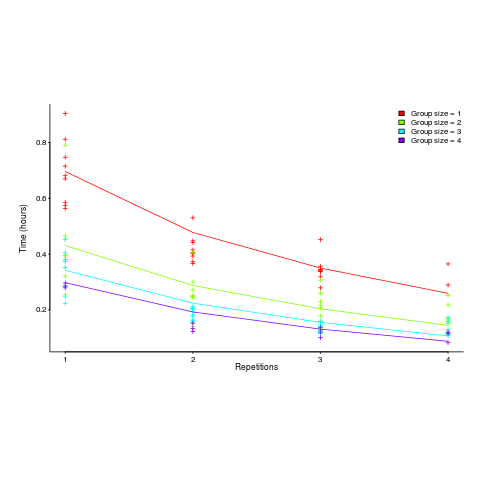
Would the same kind of equation fit the results from solving a software engineering task? Hopefully somebody will run an experiment to find out 🙂
Students vs. professionals in software engineering experiments
Experiments are an essential component of any engineering discipline. When the experiments involve people, as subjects in the experiment, it is crucial that the subjects are representative of the population of interest.
Academic researchers have easy access to students, but find it difficult to recruit professional developers, as subjects.
If the intent is to generalize the results of an experiment to the population of students, then using student as subjects sounds reasonable.
If the intent is to generalize the results of an experiment to the population of professional software developers, then using student as subjects is questionable.
What it is about students that makes them likely to be very poor subjects, to use in experiments designed to learn about the behavior and performance of professional software developers?
The difference between students and professionals is practice and experience. Professionals have spent many thousands of hours writing code, attending meetings discussing the development of software; they have many more experiences of the activities that occur during software development.
The hours of practice reading and writing code gives professional developers a fluency that enables them to concentrate on the problem being solved, not on technical coding details. Yes, there are students who have this level of fluency, but most have not spent the many hours of practice needed to achieve it.
Experience gives professional developers insight into what is unlikely to work and what may work. Without experience students have no way of evaluating the first idea that pops into their head, or a situation presented to them in an experiment.
People working in industry are well aware of the difference between students and professional developers. Every year a fresh batch of graduates start work in industry. The difference between a new graduate and one with a few years experience is apparent for all to see. And no, Masters and PhD students are often not much better and in some cases worse (their prolonged sojourn in academia means that have had more opportunity to pick up impractical habits).
It’s no wonder that people in industry laugh when they hear about the results from experiments based on student subjects.
Just because somebody has “software development” in their job title does not automatically make they an appropriate subject for an experiment targeting professional developers. There are plenty of managers with people skills and minimal technical skills (sub-student level in some cases)
In the software related experiments I have run, subjects were asked how many lines of code they had read/written. The low values started at 25,000 lines. The intent was for the results of the experiments to be generalized to the population of people who regularly wrote code.
Psychology journals are filled with experimental papers that used students as subjects. The intent is to generalize the results to the general population. It has been argued that students are not representative of the general population in that they have spent more time reading, writing and reasoning than most people. These subjects have been labeled as WEIRD.
I spend a lot of time reading software engineering papers. If a paper involves human subjects, the first thing I do is find out whether the subjects were students (usual) or professional developers (not common). Authors sometimes put effort into dressing up their student subjects as having professional experience (perhaps some of them have spent a year or two in industry, but talking to the authors often reveals that the professional experience was tutoring other students), others say almost nothing about the identity of the subjects. Papers describing experiments using professional developers, trumpet this fact in the abstract and throughout the paper.
I usually delete any paper using student subjects, some of the better ones are kept in a subdirectory called students.
Software engineering researchers are currently going through another bout of hand wringing over the use of student subjects. One paper makes the point that a student based experiment is a good way of validating an experiment that will later involve professional developers. This is a good point, but ignored the problem that researchers rarely move on to using professional subjects; many researchers only ever intend to run student-based experiments. Also, they publish the results from the student based experiment, which are at best misleading (but academics get credit for publishing papers, not for the content of the papers).
Researchers are complaining that reviews are rejecting their papers on student based experiments. I’m pleased to hear that reviewers are rejecting these papers.
Experimental Psychology by Robert S. Woodworth
I have just discovered “Experimental Psychology” by Robert S. Woodworth; first published in 1938, I have a reprinted in Great Britain copy from 1951. The Internet Archive has a copy of the 1954 revised edition; it’s a very useful pdf, but it does not have the atmospheric musty smell of an old book.
The Archives of Psychology was edited by Woodworth and contain reports of what look like ground breaking studies done in the 1930s.
The book is surprisingly modern, in that the topics covered are all of active interest today, in fields related to cognitive psychology. There are lots of experimental results (which always biases me towards really liking a book) and the coverage is extensive.
The history of cognitive psychology, as I understood it until this week, was early researchers asking questions, doing introspection and sometimes running experiments in the late 1800s and early 1900s (e.g., Wundt and Ebbinghaus), behaviorism dominants the field, behaviorism is eviscerated by Chomsky in the 1960s and cognitive psychology as we know it today takes off.
Now I know that lots of interesting and relevant experiments were being done in the 1920s and 1930s.
What is missing from this book? The most obvious omission is equations; lots of data points plotted on graph paper, but no attempt to fit an equation to anything, e.g., an exponential curve to the rate of learning.
A more subtle omission is the world view; digital computers had not been invented yet and Shannon’s information theory was almost 20 years in the future. Researchers tend to be heavily influenced by the tools they use and the zeitgeist. Computers as calculators and information processors could not be used as the basis for models of the human mind; they had not been invented yet.
Replication: not always worth the effort
Replication is the means by which mistakes get corrected in science. A researcher does an experiment and gets a particular result, but unknown to them one or more unmeasured factors (or just chance) had a significant impact. Another researcher does the same experiment and fails to get the same results, and eventually many experiments later people have figured out what is going on and what the actual answer is.
In practice replication has become a low status activity, journals want to publish papers containing new results, not papers backing up or refuting the results of previously published papers. The dearth of replication has led to questions being raised about large swathes of published results. Most journals only published papers that contain positive results, i.e., something was shown to some level of statistical significance; only publishing positive results produces publication bias (there have been calls for journals that publishes negative results).
Sometimes, repeating an experiment does not seem worth the effort. One such example is: An Explicit Strategy to Scaffold Novice Program Tracing. It looks like the authors ran a proper experiment and did everything they are supposed to do; but, I think the reason that got a positive result was luck.
The experiment involved 24 subjects and these were randomly assigned to one of two groups. Looking at the results (figures 4 and 5), it appears that two of the subjects had much lower ability that the other subjects (the authors did discuss the performance of these two subjects). Both of these subjects were assigned to the control group (there is a 25% chance of this happening, but nobody knew what the situation was until the experiment was run), pulling down the average of the control, making the other (strategy) group appear to show an improvement (i.e., the teaching strategy improved student performance).
Had one, or both, low performers been assigned to the other (strategy) group, no experimental effect would have shown up in the results, significantly reducing the probability that the paper would have been accepted for publication.
Why did the authors submit the paper for publication? Well, academic performance is based on papers published (quality of journal they appear in, number of citations, etc), a positive result is reason enough to submit for publication. The researchers did what they have been incentivized to do.
I hope the authors of the paper continue with their experiments. Life is full of chance effects and the only way to get a solid result is to keep on trying.
Experimental method for measuring benefits of identifier naming
I was recently came across a very interesting experiment in Eran Avidan’s Master’s thesis. Regular readers will know of my interest in identifiers; while everybody agrees that identifier names have a significant impact on the effort needed to understand code, reliably measuring this impact has proven to be very difficult.
The experimental method looked like it would have some impact on subject performance, but I was not expecting a huge impact. Avidan’s advisor was Dror Feitelson, who kindly provided the experimental data, answered my questions and provided useful background information (Dror is also very interested in empirical work and provides a pdf of his book+data on workload modeling).
Avidan’s asked subjects to figure out what a particular method did, timing how long it took for them to work this out. In the control condition a subject saw the original method and in the experimental condition the method name was replaced by local and parameter names were replaced by single letter identifiers; in all cases the method name was replaced by xxx andxxx. The hypothesis was that subjects would take longer for methods modified to use ‘random’ identifier names.
A wonderfully simple idea that does not involve a lot of experimental overhead and ought to be runnable under a wide variety of conditions, plus the difference in performance is very noticeable.
The think aloud protocol was used, i.e., subjects were asked to speak their thoughts as they processed the code. Having to do this will slow people down, but has the advantage of helping to ensure that a subject really does understand the code. An overall slower response time is not important because we are interested in differences in performance.
Each of the nine subjects sequentially processed six methods, with the methods randomly assigned as controls or experimental treatments (of which there were two, locals first and parameters first).
The procedure, when a subject saw a modified method was as follows: the subject was asked to explain the method’s purpose, once an answer was given (or 10 mins had elapsed) either the local or parameter names were revealed and the subject had to again explain the method’s purpose, and when an answer was given the names of both locals and parameters was revealed and a final answer recorded. The time taken for the subject to give a correct answer was recorded.
The summary output of a model fitted using a mixed-effects model is at the end of this post (code+data; original experimental materials). There are only enough measurements to have subject as a random effect on the treatment; no order of presentation data is available to look for learning effects.
Subjects took longer for modified methods. When parameters were revealed first, subjects were 268 seconds slower (on average), and when locals were revealed first 342 seconds slower (the standard deviation of the between subject differences was 187 and 253 seconds, respectively; less than the treatment effect, surprising, perhaps a consequence of information being progressively revealed helping the slower performers).
Why is subject performance less slow when parameter names are revealed first? My thoughts: parameter names (if well-chosen) provide clues about what incoming values represent, useful information for figuring out what a method does. Locals are somewhat self-referential in that they hold local information, often derived from parameters as initial values.
What other factors could impact subject performance?
The number of occurrences of each name in the body of the method provides an opportunity to deduce information; so I think time to figure out what the method does should less when there are many uses of locals/parameters, compared to when there are few.
The ability of subjects to recognize what the code does is also important, i.e., subject code reading experience.
There are lots of interesting possibilities that can be investigated using this low cost technique.
Linear mixed model fit by REML ['lmerMod']
Formula: response ~ func + treatment + (treatment | subject)
Data: idxx
REML criterion at convergence: 537.8
Scaled residuals:
Min 1Q Median 3Q Max
-1.34985 -0.56113 -0.05058 0.60747 2.15960
Random effects:
Groups Name Variance Std.Dev. Corr
subject (Intercept) 38748 196.8
treatmentlocals first 64163 253.3 -0.96
treatmentparameters first 34810 186.6 -1.00 0.95
Residual 43187 207.8
Number of obs: 46, groups: subject, 9
Fixed effects:
Estimate Std. Error t value
(Intercept) 799.0 110.2 7.248
funcindexOfAny -254.9 126.7 -2.011
funcrepeat -560.1 135.6 -4.132
funcreplaceChars -397.6 126.6 -3.140
funcreverse -466.7 123.5 -3.779
funcsubstringBetween -145.8 125.8 -1.159
treatmentlocals first 342.5 124.8 2.745
treatmentparameters first 267.8 106.0 2.525
Correlation of Fixed Effects:
(Intr) fncnOA fncrpt fncrpC fncrvr fncsbB trtmntlf
fncndxOfAny -0.524
funcrepeat -0.490 0.613
fncrplcChrs -0.526 0.657 0.620
funcreverse -0.510 0.651 0.638 0.656
fncsbstrngB -0.523 0.655 0.607 0.655 0.648
trtmntlclsf -0.505 -0.167 -0.182 -0.160 -0.212 -0.128
trtmntprmtf -0.495 -0.184 -0.162 -0.184 -0.228 -0.213 0.673 |
Recent Comments