Archive
Evidence-based software engineering: book released
My book, Evidence-based software engineering, is now available; the pdf can be downloaded here, here and here, plus all the code+data. Report any issues here. I’m investigating the possibility of a printed version. Mobile friendly pdf (layout shaky in places).
The original goals of the book, from 10-years ago, have been met, i.e., discuss what is currently known about software engineering based on an analysis of all the publicly available software engineering data, and having the pdf+data+code freely available for download. The definition of “all the public data” started out as being “all”, but as larger and higher quality data was discovered the corresponding were ignored.
The intended audience has always been software developers and their managers. Some experience of building software systems is assumed.
How much data is there? The data directory contains 1,142 csv files and 985 R files, the book cites 895 papers that have data available of which 556 are cited in figure captions; there are 628 figures. I am currently quoting the figure of 600+ for the ‘amount of data’.

Things that might be learned from the analysis has been discussed in previous posts on the chapters: Human cognition, Cognitive capitalism, Ecosystems, Projects and Reliability.
The analysis of the available data is like a join-the-dots puzzle, except that the 600+ dots are not numbered, some of them are actually specs of dust, and many dots are likely to be missing. The future of software engineering research is joining the dots to build an understanding of the processes involved in building and maintaining software systems; work is also needed to replicate some of the dots to confirm that they are not specs of dust, and to discover missing dots.
Some missing dots are very important. For instance, there is almost no data on software use, but there can be lots of data on fault experiences. Without software usage data it is not possible to estimate whether the software is very reliable (i.e., few faults experienced per amount of use), or very unreliable (i.e., many faults experienced per amount of use).
The book treats the creation of software systems as an economically motivated cognitive activity occurring within one or more ecosystems. Algorithms are now commodities and are not discussed. The labour of the cognitariate is the means of production of software systems, and this is the focus of the discussion.
Existing books treat the creation of software as a craft activity, with developers applying the skills and know-how acquired through personal practical experience. The craft approach has survived because building software systems has been a sellers market, customers have paid what it takes because the potential benefits have been so much greater than the costs.
Is software development shifting from being a sellers market to a buyers market? In a competitive market for development work and staff, paying people to learn from mistakes that have already been made by many others is an unaffordable luxury; an engineering approach, derived from evidence, is a lot more cost-effective than craft development.
As always, if you know of any interesting software engineering data, please let me know.
Waiting for the funerals: culture in software engineering research
A while ago I changed my opinion about why software engineering academics very rarely got/get involved in empirical/experimental based research.
I used to think it was because commercial data was so hard to get hold of.
In practice commercial data does not seem to be that hard to get hold of. At least for academics in business schools, and I have not experienced problems gaining access to commercial data (but it is very hard finding a company willing to allow me to make an anonymised version of its data public). There are many evidence-based papers published using confidential data (i.e., data that cannot be made public).
I now think the reasons for non-evidence-based research are culture and preference for non-people based research.
In the academic world the software side of computing often has a strong association is mathematics departments (I know that in some universities it is in engineering). I have had several researchers tell me that it would raise eyebrows, if they started doing more people oriented research, because this kind of research is viewed as being the purview of other departments.
Software had its algorithm era, which is now long gone; but unfortunately, many academics still live in a world where the mindset of TEOCP holds sway.
Baffled looks are common, when I talk to software engineering academics. They are baffled by the idea that it is possible to run experiments in software engineering, and they are baffled by the idea of evidence-based theories. I am still struggling to understand the mindset that produces the arguments they make against the possibility of experiments and evidence being useful.
In the past I know that some researchers have had problems getting experiment-based papers published. Hopefully this problem is now in the past, given that empirical/experimental papers are becoming more common.
Max Planck, one of the founders of quantum mechanics, found that physicists trained in what we now call classical physics, were not willing to teach or adopt a quantum mechanics world view; Planck observed: “Science advances one funeral at a time”.
Major players in evidence-based software engineering
Who are the major players in evidence-based software engineering?
How might ‘majorness’ of players be calculated? For me, the amount of interesting software engineering data they have made publicly available is the crucial factor. Any data published in a book, paper or report is enough to be considered interesting. How interesting is data published on a web page? This is a tough question, let’s dodge the question to start with, and consider the decades before the start of 2000.
In the academic world performance is based on number of papers published, the impact factor of where they were published and number of citations of those papers. This skews the results in favor of those with lots of students (who tack their advisor’s name on the end of papers published) and those who are good at marketing.
Historians of computing have primarily focused on the evolution of hardware and are slowly moving to discuss software (perhaps because microcomputers have wiped out nearly every hardware vendor). So we will have to wait perhaps a decade or two for tentative/definitive historian answer.
The 1950s
Computers and Automation is a criminally underused resource (a couple of PhDs worth of primary data here). A lot of the data is hardware related, but software gets a lot more than a passing mention.
The US military published lots of hardware data, but software does not get mentioned much.
The 1960s
Computers and Automation are still publishing.
The US military still publishing data; again mostly hardware related.
Datamation, a weekly news magazine, published a lot of substantial material on the software and hardware ecosystems as they evolved.
Kenneth Knight’s analysis of computer performance is an example of the kind of data analysis that many people undertook for hardware, which was rarely done for software.
The 1970s
The US military are still leading the way; we are in the time of Rome. Air Force officers studying for a Master’s degree publish more software engineering data than all academics combined over this and the next two decades.
“Data processing technology and economics” by Montgomery Phister is 720 A4 pages packed with graphs and tables of numbers. Despite citing earlier sources, this has become the primary source for a lot of subsequent researchers; this is understandable in a pre-internet age. Now we have Bitsavers and the Internet Archive, and the cited primary source can be downloaded.
NASA is surprisingly low volume.
The 1980s
Rome falls (i.e., the work gets outsourced to a university) and the false prophets (i.e., academics doing non-evidence based work) multiply and prosper. There are hushed references to trouble makers performing unclean acts experiments in the wilderness.
A few people working in the wilderness, meaning that the quantity of data being produced drops by at least an order of magnitude.
The 1990s
Enough time has passed for people to be able to refer to the wisdom of the ancients.
There are still people in the wilderness howling at the moon, and performing unclean acts experiments.
The 2000s
Repositories of Open source and bug reports grow and prosper. Evidence-based software engineering research starts to become mainstream.
There are now groups of people doing software engineering research.
What about individuals as major players? A vaguely scientific way of rating individual impact, on evidence-based software engineering, is to count the number of papers researchers have published, that are cited by a book claiming to discuss all the important/interesting publicly available software engineering data (code+data).
The 1,521 2,035 papers cited, by this book, had 3,716 5,095 authors, of which 3,095 4,210 were different. The authors who appeared most often are listed below (count on the right, and yes, at number 3 2 is a theoretician; I have cited myself nine 17 times, but two of those are to websites hosting data; Updated numbers to published version).
Magne Jorgensen 20 17
Massimiliano Di Penta 13 10
Anne Chao 10 11
Dag I. K. Sjoberg 10
Joseph Henrich 10
Ahmed E. Hassan 9 8
Christian Kästner 9
Sven Apel 9
Tom Mens 9
Audris Mockus 8
Christian Bird 8
Stanislas Dehaene 8
Andreas Zeller 7
Dror G. Feitelson 7 6
Gabriele Bavota 7
Giuliano Antoniol 7
Krzysztof Czarnecki 7 6
Rocco Oliveto 7
Thomas Zimmermann 7
Benoit Baudry 6
Bram Adams 6
Daniel M. German 6
Gerd Gigerenzer 6
Gregorio Robles 6
Lutz Prechelt 6
Victor R. Basili 6
Martin Monperrus 6
Alexander Serebrenik 5 6
The number of authors/papers follows the usual pattern of many people writing one paper.
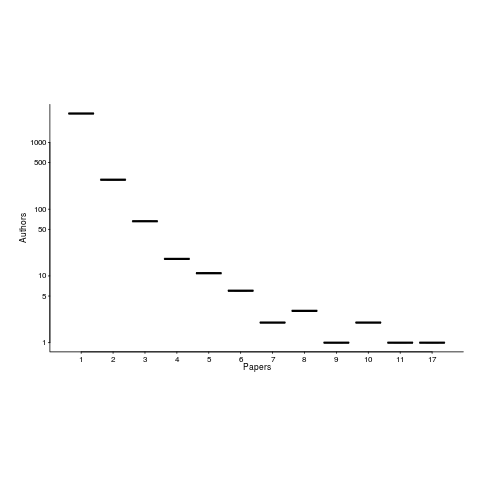
Who might I have missed? The business school researchers don’t get a mention because their data is often covered by a confidentiality agreement. The machine learning crowd are just embarrassing.
Suggestions for major players welcome.
Vanity project or real research?
I gave a talk at the CREST Open Workshop yesterday. Many of those attending and speaking were involved in empirical work of one kind or another. My experience is that researchers involved in empirical work, in software engineering, feel the need to justify using this approach to research, because it is different from what many others in the field do. I want to reverse this perception; those not doing empirical work are the ones that should feel the need to justify their approach to research.
Evidence obtained from experiments and measurements are the basis of the scientific method.
I started by contrasting a typical software engineering researcher’s view of their work (both images from Wikipedia under a Creative Commons Attribution-ShareAlike License):
.jpg)
with a common industry view of academic researchers:

The reputation of those doing evidence based research is being completely overshadowed by those who use ego and bluster to promote their claims. We needed an effective label for work that is promoted using ego and bluster, and I proposed vanity projects (the work done by the ego and bluster crowd does not deserve to be referred to as research). Yes, there are plenty of snake-oil salesmen in industry, but that is another issue.
Vanity projects being passed off as research should be named and shamed.
Next time you are in the audience listening to claims made by the speaker about the results of his/her research, that are not backed up by experiments or measurements, ask them why decided to pursue a vanity project rather than proper research.
Recent Comments