Archive
Fishing for software data
During 2021 I sent around 100 emails whose first line started something like: “I have been reading your interesting blog post…”, followed by some background information, and then a request for software engineering data. Sometimes the request for data was specific (e.g., the data associated with the blog post), and sometimes it was a general request for any data they might have.
So far, these 100 email requests have produced one two datasets. Around 80% failed to elicit a reply, compared to a 32% no reply for authors of published papers. Perhaps they don’t have any data, and don’t think a reply is worth the trouble. Perhaps they have some data, but it would be a hassle to get into a shippable state (I like this idea because it means that at least some people have data). Or perhaps they don’t understand why anybody would be interested in data and must be an odd-ball, and not somebody they want to engage with (I may well be odd, but I don’t bite :-).
Some of those who reply, that they don’t have any data, tell me that they don’t understand why I might be interested in data. Over my entire professional career, in many other contexts, I have often encountered surprise that data driven problem-solving increases the likelihood of reaching a workable solution. The seat of the pants approach to problem-solving is endemic within software engineering.
Others ask what kind of data I am interested in. My reply is that I am interested in human software engineering data, pointing out that lots of Open source is readily available, but that data relating to the human factors underpinning software development is much harder to find. I point them at my evidence-based book for examples of human centric software data.
In business, my experience is that people sometimes get in touch years after hearing me speak, or reading something I wrote, to talk about possible work. I am optimistic that the same will happen through my requests for data, i.e., somebody I emailed will encounter some data and think of me 🙂
What is different about 2021 is that I have been more willing to fail, and not just asking for data when I encounter somebody who obviously has data. That is to say, my expectation threshold for asking is lower than previous years, i.e., I am more willing to spend a few minutes crafting a targeted email on what appear to be tenuous cases (based on past experience).
In 2022 I plan to be even more active, in particular, by giving talks and attending lots of meetups (London based). If your company is looking for somebody to give an in-person lunchtime talk, feel free to contact me about possible topics (I’m always after feedback on my analysis of existing data, and will take a 10-second appeal for more data).
Software data is not commonly available because most people don’t collect data, and when data is collected, no thought is given to hanging onto it. At the moment, I don’t think it is possible to incentivize people to collect data (i.e., no saleable benefit to offset the cost of collecting it), but once collected the cost of hanging onto data is peanuts. So as well as asking for data, I also plan to sell the idea of hanging onto any data that is collected.
Fishing tips for software data welcome.
Extreme value theory in software engineering
As its name suggests, extreme value theory deals with extreme deviations from the average, e.g., how often will rainfall be heavy enough to cause a river to overflow its banks.
The initial list of statistical topics I thought ought to be covered in my evidence-based software engineering book included extreme value theory. At the time, and even today, there were/are no books covering “Statistics for software engineering”, so I had no prior work to guide my selection of topics. I was keen to cover all the important topics, had heard of it in several (non-software) contexts and jumped to the conclusion that it must be applicable to software engineering.
Years pass: the draft accumulate a wide variety of analysis techniques applied to software engineering data, but, no use of extreme value theory.
Something else does not happen: I don’t find any ‘Using extreme value theory to analyse data’ books. Yes, there are some really heavy-duty maths books available, but nothing of a practical persuasion.
The book’s Extreme value section becomes a subsection, then a subsubsection, and ended up inside a comment (I cannot bring myself to delete it).
It appears that extreme value theory is more talked about than used. I can understand why. Extreme events are newsworthy; rivers that don’t overflow their banks are not news.
Just over a month ago a discussion cropped up on the UK’s C++ standards’ panel mailing list: was email traffic down because of COVID-19? The panel’s convenor, Roger Orr, posted some data on monthly volumes. Oh, data 🙂
Monthly data is a bit too granular for detailed analysis over relatively short periods. After some poking around Roger was able to send me the date&time of every post to the WG21‘s Core and Lib reflectors, since February 2016 (there have been various changes of hosts and configurations over the years, and date of posts since 2016 was straightforward to obtain).
During our email exchanges, Roger had mentioned that every now and again a huge discussion thread comes out of nowhere. Woah, sounds like WG21 could do with some extreme value theory. How often are huge discussion threads likely to occur, and how huge is a once in 10-years thread that they might have to deal with?
There are two techniques for analysing the distribution of extreme values present in a sample (both based around the generalized extreme value distribution):
- Generalized Extreme Value (GEV) uses block maxima, e.g., maximum number of daily emails sent in each month,
- Generalized Pareto (GP) uses peak over threshold: pick a threshold and extract day values for when more than this threshold number of emails was sent.
The plots below show the maximum number of monthly emails that are expected to occur (y-axis) within a given number of months (x-axis), for WG21’s Core and Lib email lists. The circles are actual occurrences, and dashed lines 95% confidence intervals; GEV was used for these fits (code+data):
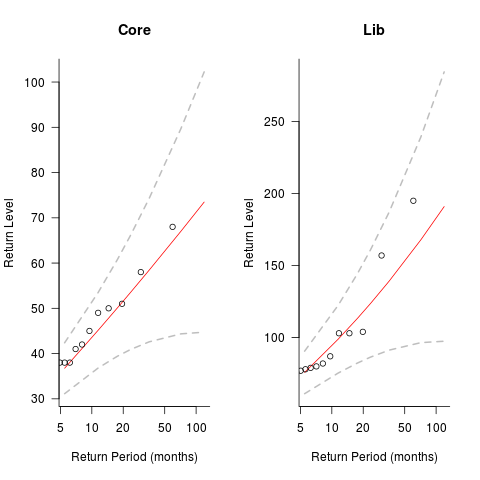
The 10-year return value for Core is around a daily maximum of 70 +-30, and closer to 200 +-100 for Lib.
The model used is very simplistic, and fails to take into account the growth in members joining these lists and traffic lost when a new mailing list is created for a new committee subgroup.
If any readers have suggests for uses of extreme value theory in software engineering, please let me know.
Postlude. This discussion has reordered events. My original interest in the mailing list data was the desire to find some evidence for the hypothesis that the volume of email increased as the date of the next WG21 meeting approached. For both Core and Lib, the volume actually decreases slightly as the date of the next meeting approaches; see code for details. Also, the volume of email at the weekend is around 60% lower than during weekdays.
No replies to 135 research data requests: paper titles+author emails
I regularly email researchers referring to a paper of theirs I have read, and asking for a copy of the data to use as an example in my evidence-based software engineering book; of course their work is cited as the source.
Around a third of emails don’t receive any reply (a small number ask why they should spend time sorting out the data for me, and I wrote a post to answer this question). If there is no reply after roughly 6-months, I follow up with a reminder, saying that I am still interested in their data (maybe 15% respond). If the data looks really interesting, I might email again after 6-12 months (I have outstanding requests going back to 2013).
I put some effort into checking that a current email address is being used. Sometimes the work was done by somebody who has moved into industry, and if I cannot find what looks like a current address I might email their supervisor.
I have had replies to later email, apologizing, saying that the first email was caught by their spam filter (the number of links in the email template was reduced to make it look less like spam). Sometimes the original email never percolated to the top of their todo list.
There are were originally around 135 unreplied email requests (the data was automatically extracted from my email archive and is not perfect); the list of papers is below (the title is sometimes truncated because of the extraction process).
Given that I have collected around 620 software engineering datasets (there are several ways of counting a dataset), another 135 would make a noticeable difference. I suspect that much of the data is now lost, but even 10 more datasets would be nice to have.
After the following list of titles is a list of the 254 author last known email addresses. If you know any of these people, please ask them to get in touch.
If you are an author of one of these papers: ideally send me the data, otherwise email to tell me the status of the data (I’m summarising responses, so others can get some idea of what to expect).
50 CVEs in 50 Days: Fuzzing Adobe Reader A Change-Aware Per-File Analysis to Compile Configurable Systems A Design Structure Matrix Approach for Measuring Co-Change-Modularity A Foundation for the Accurate Prediction of the Soft Error AGENT-BASED SIMULATION OF THE SOFTWARE DEVELOPMENT PROCESS: A CASE STUDY A Large Scale Evaluation of Automated Unit Test Generation Using A large-scale study of the time required to compromise A Large-Scale Study On Repetitiveness, Containment, and Analysing Humanly Generated Random Number Sequences: A Pattern-Based Analysis of Software Aging in a Web Server Analyzing and predicting effort associated with finding & fixing Analyzing CAD competence with univariate and multivariate Analyzing Differences in Risk Perceptions between Developers Analyzing the Decision Criteria of Software Developers Based on An analysis of the effect of environmental and systems complexity on An Empirical Analysis of Software-as-a-Service Development An Empirical Comparison of Forgetting Models An empirical study of the textual similarity between An error model for pointing based on Fitts' law An Evolutionary Study of Linux Memory Management for Fun and Profit An examination of some software development effort and An Experimental Survey of Energy Management Across the Stack Anomaly Trends for Missions to Mars: Mars Global Surveyor A Quantitative Evaluation of the RAPL Power Control System Are Information Security Professionals Expected Value Maximisers?: A replicated and refined empirical study of the use of friends in A Study of Repetitiveness of Code Changes in Software Evolution A Study on the Interactive Effects among Software Project Duration, Risk Bias in Proportion Judgments: The Cyclical Power Model Capitalization of software development costs Configuration-aware regression testing: an empirical study of sampling Cost-Benefit Analysis of Technical Software Documentation Decomposing the problem-size effect: A comparison of response Determinants of vendor profitability in two contractual regimes: Diagnosing organizational risks in software projects: Early estimation of users’ perception of Software Quality MEASURING USER’S PERCEPTION AND OPINION OF SOFTWARE QUALITY Empirical Analysis of Factors Affecting Confirmation Estimating Agile Software Project Effort: An Empirical Study Estimating computer depreciation using online auction data Estimation fulfillment in software development projects Ethical considerations in internet code reuse: A Evaluating. Heuristics for Planning Effective and Explaining Multisourcing Decisions in Application Outsourcing Exploring defect correlations in a major. Fortran numerical library Extended Comprehensive Study of Association Measures for Eye gaze reveals a fast, parallel extraction of the syntax of Factorial design analysis applied to the performance of Frequent Value Locality and Its Applications Historical and Impact Analysis of API Breaking Changes: How do i know whether to trust a research result? How do OSS projects change in number and size? How much is “about” ? Fuzzy interpretation of approximate Humans have evolved specialized skills of Identifying and Classifying Ambiguity for Regulatory Requirements Identifying Technical Competences of IT Professionals. The Case of Impact of Programming and Application-Specific Knowledge Individual-Level Loss Aversion in Riskless and Risky Choices Industry Shakeouts and Technological Change Inherent Diversity in Replicated Architectures Initial Coin Offerings and Agile Practices Interpreting Gradable Adjectives in Context: Domain Is Branch Coverage a Good Measure of Testing Effectiveness? JavaScript Developer Survey Results Knowledge Acquisition Activity in Software Development Language matters Learning from Evolution History to Predict Future Requirement Changes Learning from Experience in Software Development: Learning from Prior Experience: An Empirical Study of Links Between the Personalities, Views and Attitudes of Software Engineers Making root cause analysis feasible for large code bases: Making-Sense of the Impact and Importance of Outliers in Project Management Aspects of Software Clone Detection and Analysis Managing knowledge sharing in distributed innovation from the Many-Core Compiler Fuzzing Measuring Agility Mining for Computing Jobs Mining the Archive of Formal Proofs. Modeling Readability to Improve Unit Tests Modeling the Occurrence of Defects and Change Modelling and Evaluating Software Project Risks with Quantitative Moore’s Law and the Semiconductor Industry: A Vintage Model Motivations for self-assembling into project teams Networks, social influence and the choice among competing innovations: Nonliteral understanding of number words Nonstationarity and the measurement of psychophysical response in Occupations in Information Technology On information systems project abandonment On the Positive Effect of Reactive Programming on Software ON THE USE OF REPLACEMENT MESSAGES IN API DEPRECATION: On Vendor Preferences for Contract Types in Offshore Software Projects: Peer Review on Open Source Software Projects: Parameter-based refactoring and the relationship with fan-in/fan-out Participation in Open Knowledge Communities and Job-Hopping: Pipeline management for the acquisition of industrial projects Predicting the Reliability of Mass-Market Software in the Marketplace Prototyping A Process Monitoring Experiment Quality vs risk: An investigation of their relationship in Quantitative empirical trends in technical performance Reported project management effort, project size, and contract type. Reproducible Research in the Mathematical Sciences Semantic Versioning versus Breaking Changes Software Aging Analysis of the Linux Operating System Software reliability as a function of user execution patterns Software Start-up failure An exploratory study on the Spatial estimation: a non-Bayesian alternative System Life Expectancy and the Maintenance Effort: Exploring Testing as an Investment The enigma of evaluation: benefits, costs and risks of IT in THE IMPACT OF PLANNING AND OTHER ORGANIZATIONAL FACTORS The impact of size and volatility on IT project performance The Influence of Size and Coverage on Test Suite The Marginal Value of Increased Testing: An Empirical Analysis The nature of the times to flight software failure during space missions Theoretical and Practical Aspects of Programming Contest Ratings The Performance of the N-Fold Requirement Inspection Method The Reaction of Open-Source Projects to New Language Features: The Role of Contracts on Quality and Returns to Quality in Offshore The Stagnating Job Market for Young Scientists Turnover of Information Technology Professionals: Unconventional applications of compiler analysis Unifying DVFS and offlining in mobile multicores Use of Structural Equation Modeling to Empirically Study the Turnover Use Two-Level Rejuvenation to Combat Software Aging and Using Function Points in Agile Projects Using Learning Curves to Mine Student Models Virtual Integration for Improved System Design Which reduces IT turnover intention the most: Workplace characteristics Why Did Your Project Fail? Within-Die Variation-Aware Dynamic-Voltage-Frequency |
Author emails (automatically extracted and manually checked to remove people who have replied on other issues; I hope I have caught them all).
Aaron.Carroll@nicta.com.au abaker@ucar.edu abd_elzamly@yahoo.com actjn@siu.edu agopal@rhsmith.umd.edu akbar.namin@ttu.edu aken@nsuok.edu akmassey@umbc.edu alessandro.murgia@uantwerpen.be alexander.budzier@sbs.ox.ac.uk alinebrito@dcc.ufmg.br Allen.P.Nikora@jpl.nasa.gov Altaf.Ahmad@asu.edu Ana.Aizcorbe@bea.gov angel.garcia@uc3m.es anhnt@iastate.edu a.pinna@diee.unica.it arho.suominen@vtt.fi arie.vandeursen@tudelft.nl asang@ntu.edu.sg awfboh@ntu.edu.sg bent.flyvbjerg@sbs.ox.ac.uk bf@ul.ie bjg@empiricalreality.com bojan.spasic@avl.com bramesh@gsu.edu brent.martin@canterbury.ac.nz briand@simula.no brian.fitzgerald@lero.ie bronevetsky1@llnl.gov burairah@utem.edu.my calikli@chalmers.se canton@mnec.gr cc05@vokac.org celio.santana@gmail.com cguo13@hawk.iit.edu charngda@ccr.buffalo.edu charngdalu@yahoo.com chenyy@comp.nus.edu.sg chris.sauer@sbs.ox.ac.uk christian.korunka@univie.ac.at christopher.lidbury10@imperial.ac.uk clitecky@business.siu.edu cmagee@mit.edu corey.phelps@mcgill.ca cotroneo@unina.it cthompson@cs.berkeley.edu daniela.munteanu@univ-provence.fr daniel.milroy@colorado.edu dan@silverthreadinc.com david@merobe.com david.nembhard@oregonstate.edu der.herr@hofr.at dgrtwo@princeton.edu dhkim@astate.edu director@scit.edu discy@nus.edu.sg djl68@pitt.edu dlautner@hawk.iit.edu dport@hawaii.edu dprtchan@nus.edu.sg dredman@avsi.aero drobinson@stackoverflow.com dskusumo.itt@gmail.com dwheeler@ida.org eherrman@eva.mpg.de Enrique.Dans@ie.edu ermira.daka@sheffield.ac.uk etovar@fi.upm.es fjshull@sei.cmu.edu foreverheart9@gmail.com founders@triplebyte.com fschweitzer@ethz.ch ghs2@psu.edu gleison.brito@dcc.ufmg.br glpkm@hotmail.com gordon.fraser@uni-passau.de greg@bronevetsky.com gul.calikli@gu.se guschroko@student.gu.se hankhoffmann@cs.uchicago.edu hannes.holm@foi.se hata@is.naist.jp hbarth@wesleyan.edu hello@ponyfoo.com hiroshi.igaki@oit.ac.jp hirtle@pitt.edu hoan@iastate.edu hora@dcc.ufmg.br hrideshg@iastate.edu huang@umd.edu huazhe@cs.uchicago.edu hwu28@hawk.iit.edu ichischneider@gmail.com I.Deary@ed.ac.uk ilaria.lunesu@diee.unica.it info@targetprocess.com james@jpallister.com jarmo.ahonen@uef.fi jasmin.blanchette@mpi-inf.mpg.de jasonweiyi@gmail.com javier.alonso@duke.edu jean-luc.autran@univ-provence.fr jfmendes@ua.pt jgo@ua.pt jianh@illinois.edu jimbo@business.siu.edu jmunson@uidaho.edu jo-anne.lefevre@carleton.ca john.krogstie@ntnu.no john.zhang@business.uconn.edu jordan.weissmann@slate.com jose.campos@sheffield.ac.uk josephborel@aol.com jselby@maplesoft.com June.Verner@gmail.com junyang@engr.pitt.edu justinek@alumni.stanford.edu justin.hollands@drdc-rddc.gc.ca j.visser@sig.eu kaisa.still@vtt.fi kantor@cs.technion.ac.il kevin.mcdaid@dkit.ie kewusi@lmu.edu K.Markantonakis@rhul.ac.uk konstantinos.chronis@gmail.com ktrivedi@duke.edu laertexavier@dcc.ufmg.br larissanadja@copin.ufcg.edu.br lcao@odu.edu leo@susaventures.com lionel.briand@uni.lu lsarigia@pme.duth.gr lucia.2009@smu.edu.sg magnus@magnusdettmar.com mail@kaidence.org ma.khan@uleth.ca manuel.oriol@ch.abb.com marc.schulz@rwth-aachen.de Marek@gryting.biz marie-jeanne.lesot@lip6.fr mariusz.musial@ericpol.com maruyama@atr.jp matthias.biggeleben@open-xchange.com matthias.stuermer@iwi.unibe.ch mcknight@bus.msu.edu mdettmar@deloitte.com mdettmar@deloitte.se melanie@cs.columbia.edu Michael.english@lero.ie michael.english@ul.ie michael.grottke@fau.de Michael.Grottke@wiso.uni-erlangen.de Michael@targetprocess.com mingshu@iscas.ac.cn mischael.schill@inf.ethz.ch misof@ksp.sk mjaber@ryerson.ca monica.pais@ifgoiano.edu.br monicaspais@gmail.com mschermann@scu.edu mtov@dcc.ufmg.br mzhu@ets.org ncerpa@utalca.cl Neil.Stewart@warwick.ac.uk Nelson.W.Green@jpl.nasa.gov nick.wells@jobstats.co.uk o.alexy@tum.de oliver.krancher@iwi.unibe.ch Oliver.Laitenberger@horn-company.de olivier.gendreau@polymtl.ca paula.j.savolainen@uef.fi paulmcb@seas.upenn.edu paul@strassmann.com pchatzog@pme.duth.gr perry@mail.utexas.edu philippe.roche@st.com phoonakker@cqpi.engr.wisc.edu pierre.robillard@polymtl.ca ploaiza@lsm.in2p3.fr P.Love@curtin.edu.au pokech@uonbi.ac.ke psidhu@cmu.edu pyzychen@gmail.com ren@iit.edu rh13@aub.edu.lb ricardo.colomo@uc3m.es rkiyer@illinois.edu robert.benkoczi@uleth.ca roberto.natella@unina.it roberto.pietrantuono@unina.it salvaneschi@cs.tu-darmstadt.de saurabh.dighe@intel.com sdorogov@ua.pt sebastien.lefort@lip6.fr sebastien.sauze@l2mp.fr shaji@scit.edu shilin@itechs.iscas.ac.cn show@um.edu.my siegfrie@adelphi.edu simona.ibba@diee.unica.it simon.gaechter@nottingham.ac.uk simonk@rpi.edu simvrh@gmail.com sl@monochromata.de soenke.albers@the-klu.org songxue@microsoft.com s.raemaekers@sig.eu sriram.vangal@intel.com ssg@engr.uconn.edu stavrino@eap.gr stavrino@gmail.com stefan@garage-coding.com sterusso@unina.it steve.a.shogren@gmail.com svkbharathi@scit.edu swilson@tcd.ie tamada@cse.kyoto-su.ac.jp tien@iastate.edu tien.n.nguyen@utdallas.edu tjleffel@gmail.com tkabdelh@nps.edu tsunoda@info.kindai.ac.jp tung@iastate.edu victoria@stodden.net wangyi@us.ibm.com William.L.Taber@jpl.nasa.gov wmhan@takming.edu.tw wobbrock@uw.edu wq@itechs.iscas.ac.cn xenos@eap.gr xhua@hawk.iit.edu xiao.qu@us.abb.com yanglusi@comp.nus.edu.sg ychen200@cba.ua.edu yi.wang@rit.edu yiw@ics.uci.edu yoaval@checkpoint.com zhangx@nku.edu zhij@cs.toronto.edu Zhongju.Zhang@asu.edu zibran@cs.uno.edu |
Update:
Have received a response relating to 6 papers (corresponding paper/author entries in above list deleted).
Recent Comments