Archive
After 55.5 years the Fortran Specialist Group has a new home
In the 1960s and 1970s, new developments in Cobol and Fortran language standards and implementations regularly appeared on the front page of the weekly computer papers (Algol 60 news sometimes appeared). Various language user groups were created, which produced newsletters and held meetups (this term did not become common until a decade or two ago).
In January 1970 the British Computer Society‘s Fortran Specialist Group (FSG) held its first meeting and 55.5 years later (this month) this group has moved to a new parent organization the Society of Research Software Engineering. The FSG is distinct from BSI‘s Fortran Standards panel and the ISO Fortran working group, although they share a few members.
I believe that the FSG is the oldest continuously running language user group. Second place probably goes to the ACCU (Association on C and C++ Users) which was started in the late 1980s. Like me, both of these groups are based in the UK (the ACCU has offshoots in other countries). I welcome corrections from readers familiar with the language groups in other countries (there were many Pascal user groups created in the 1980s, but I don’t know of any that are still active). COBOL is a business language, and I have never seen a non-vendor meetup group that got involved with language issues.
The plot below shows estimated FSG membership numbers for various years, averaging 180 (thanks to David Muxworthy for the data; code+data):

My experience of national user groups is that membership tends to hover around a thousand. Perhaps the more serious, professional approach of the BCS deters the more casual members that haunt other user groups (whose membership fees help keep things afloat).
What are the characteristics of this Fortran group that have given it such a long and continuous life?
- It was started early. Fortran was one of the first, of two (perhaps three), widely used programming languages,
- Fortran continued to evolve in response to customer demand, which made it very difficult for new languages to acquire a share of Fortran’s scientific/engineering market. Compiler vendors have kept up, or at least those selling to high-end power customers have (the Open source Fortran compilers have lagged well behind).
Most developers don’t get involved with calculations using floating-point values, and so are unfamiliar with the multitude of issues that can have a significant impact on program output, e.g., noticeably inaccurate results. The Fortran Standard’s committee has spent many years making it possible to write accurate, portable floating-point code.
A major aim of the 1999 revision of the C Standard was to make its support for floating-point programming comparable to Fortran, to entice Fortran developers to switch to C,
- people being willing to dedicate their time, over a long period, to support the activities of this group.
The minutes of all the meetings are available. The group met four times a year until 1993, and then once or twice a year. Extracting (imperfectly) the attendance from the minutes finds around 525540 unique names, with 322350 attending once and one person attending 8155 meetings. The plot below shows the number of people who attended a given number of meetings (code+data):

The survival of any group depends on those members who turn up regularly and help out. The plot below shows a sorted list of FSG member tenure, in years, excluding single attendance members (code+data):

Will the FSG live on for another 55 years at the Society of Research Software Engineering?
Fortran continues to be used in a wide range of scientific/engineering applications. There is a lot of Fortran source out there, but it’s not a fashionable language and so rarely a topic of developer conversation. A group only lives because some members invest their time to make things happen. We will have to wait and see if this transplanted groups attracts a few people willing to invest in it.
Update the next day. Added attendance from pdf minutes, and removed any middle initials to improve person matching.
Student projects for 2024/2025
It will soon be that time of year when university students are looking for an interesting idea for a project. On an irregular basis, I post some ideas for thesis projects (here and here); primarily for students studying computing. In a change of direction, this post suggests software related ideas for business student projects.
Two idea areas require data analysis skills, one requires people skills, and one an interest in theory.
More suggestions welcome in the comments.
Career paths in software
Organizations employ people to work on software systems. What is the career path of people who work on software systems? Question include: how long people stay in a particular job or company, and salary changes over time (the only data I know of investigates the career paths of 500 people working in IT).
Governments are interested in employment, and they collect and publish data at various levels of granularity. The US Bureau of Labor Statistics contains a vast amount of information, but finding the bits of interest can require a lot of work.
In the US, government employee salary is public information, and various sites make this available, e.g., OpePayrolls and Transparent California. There is a Japanese Open Salaries, and various commercial companies operate an open salary policy (Buffer is perhaps the most famous).
This project requires students with some data analysis skills.
There is some data on job postings,
Computer company lifecycle
Companies are born, do business and eventually die (unless bought/merged). How do the lifecycle characteristics of computer companies differ from companies doing business in other domains? Lifecycle characteristics of interest might include profiles of age, number of employees, and profitability. What are the consequences, if any, of these differences?
Details of all UK registered companies are freely available from Companies House.
Open Corporates provides company information from across the world, but it is not free in bulk.
Some analysis of the geographical clustering of software companies in the UK.
This project requires students with some data analysis skills.
AI startup ecosystem
AI has exploded on the tech scene, and lots of people are creating startups to build services/products around LLMs. Teams are very fluid, with people moving around a lot looking for a viable service/product. Sometimes these teams form companies, and these might eventually leave stealth mode and become visible. What are the characteristics of the AI startup ecosystem within a city; questions include: how many people are working within it, their backgrounds, and the business areas are they focusing on?
This project requires students with people skills and a willingness to get out and about. Much of the current AI ecosystem is only visible to those within it. Evening meetups and workshops offer a way into this personal network. This research involves bootstrapping the data gathering by spending evenings schmoozing with founders and their new hires, and is probably only practical in major cities with a very active tech meeting scene.
An analysis of a Dutch software business network.
Theoretical analysis
Those with an interest in theory might like to analyse cost-benefit decision-making within software development. Examples of simple analysis+supporting data include:
Analysis of when refactoring becomes cost-effective, and Cost-effectiveness decision for fixing a known coding mistake, and Break even ratios for development investment decisions
Looking for a measurable impact from developer social learning
Almost everything you know was discovered/invented by other people. Social learning (i.e., learning from others) is the process of acquiring skills by observing others (teaching is explicit formalised sharing of skills). Social learning provides a mechanism for skills to spread through a population. An alternative to social learning is learning by personal trial and error.
When working within an ecosystem that changes slowly, it is more cost-effective to learn from others than learn through trial and error (assuming that experienced people are available to learn from, and the learner is capable of identifying them); “Social Learning” by Hoppitt and Layland analyzes the costs and benefits of using social learning.
Since its inception, much of software engineering has been constantly changing. In a rapidly changing ecosystem, the experience of established members may suggest possible solutions that do not deliver the expected results in a changed world, i.e., social learning may not be a cost-effective way of building a skill set applicable within the new ecosystem.
Opportunities for social learning occur wherever developers tend to congregate.
When I started writing software people, developers would print out a copy of their code to take away and correct/improve/add-to (this was when 100+ people were time-sharing on a computer with 256K words of memory, running at 1 MHz). People would cluster around the printer, which ran sufficiently slowly that it was possible, in real-time, to read the code and figure out what was going on; it was possible to learn from others code (pointing out mistakes in programs that people planned to hand in was not appreciated). Then personal computers became available, along with low-cost printers (e.g., dot matrix), which were often shared, and did not print so fast that an experienced developer could not figure things out in real-time. Then laser printers came along, delivering a page at a time every 15 seconds, or so; experiencing the first print out from a Laser printer, I immediately knew that real-time code reading was a thing of the past (also, around this time, full-screen editors achieved the responsiveness needed to enthral developers, paper code listings could not compete). A regular opportunity for social learning disappeared.
Mentoring and retrospectives are intended as explicit (perhaps semi-taught) learning contexts, in which social learning opportunities may be available.
The effectiveness of social learning is dependent on being able to select a good enough source of expertise to learn from. Choosing the person with the highest prestige is a common social selection technique; selecting web pages appearing on the first page of a Google search is actually a form of conformist learning (i.e., selecting what others have chosen).
It is possible to point at particular instances of social learning in software engineering, but to what extent does social learning, other than explicit teaching, contribute to developer skills?
Answering this question requires enumerating all the non-explicitly taught skills a developer uses to get the job done, excluding the non-developer specific skills. A daunting task.
Is it even possible to consistently distinguish between social learning (implicit or taught) and individual learning?
For instance, take source code indentation. Any initial social learning is likely to have been subsequently strongly influenced by peer pressure, and default IDE settings.
Pronunciation of operator names is a personal choice that may only ever exist within a developer’s head. In my head, I pronounce the ^ operator as up-arrow, because I first encountered its use in the book Algorithms + Data Structures = Programs which used the symbol ↑, which appears as the ^ character on modern keyboards. I often hear others using the word caret, which I have to mentally switch over to using. People who teach themselves to program have to invent names for unfamiliar symbols, until they hear somebody speaking code (the widespread availability of teach-yourself videos will make it rare to need for this kind of individual learning; individual learning is giving way to social learning).
The problem with attempting to model social learning is that much of the activity occurs in private, and is not recorded.
One public source of prestigious experience is Stack Overflow. Code snippets included as part of an answer on Stack Overflow appear in around 1.8% of Github repositories. However, is the use of this code social learning or conformist transmission (i.e., copy and paste)?
Explaining social learning to people is all well and good, but having to hand wave when asked for a data-driven example is not good. Suggestions welcome.
Ecosystems as major drivers of software development
During the age of the Algorithm, developers wrote most of the code in their programs. In the age of the Ecosystem, developers make extensive use of code supplied by third-parties.
Software ecosystems are one of the primary drivers of software development.
The early computers were essentially sold as bare metal, with the customer having to write all the software. Having to write all the software was expensive, time-consuming, and created a barrier to more companies using computers (i.e., it was limiting sales). The amount of software that came bundled with a new computer grew over time; the following plot (code+data) shows the amount of code (thousands of instructions) bundled with various IBM computers up to 1968 (an antitrust case eventually prevented IBM bundling software with its computers):
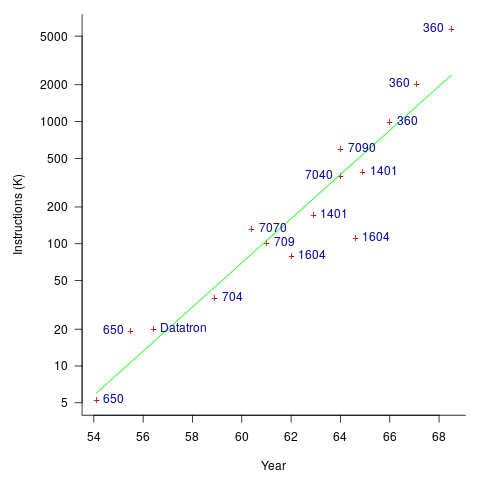
Some tasks performed using computers are common to many computer users, and users soon started to meet together, to share experiences and software. SHARE, founded in 1955, was the first computer user group.
SHARE was one of several nascent ecosystems that formed at the start of the software age, another is the Association for Computing Machinery; a great source of information about the ecosystems existing at the time is COMPUTERS and AUTOMATION.
Until the introduction of the IBM System/360, manufacturers introduced new ranges of computers that were incompatible with their previous range, i.e., existing software did not work.
Compatibility with existing code became a major issue. What had gone before started to have a strong influence on what was commercially viable to do next. Software cultures had come into being and distinct ecosystems were springing up.
A platform is an ecosystem which is primarily controlled by one vendor; Microsoft Windows is the poster child for software ecosystems. Over the years, Microsoft has added more and more functionality to Windows, and I don’t know enough to suggest the date when substantial Windows programs substantially depended on third-party code; certainly small apps may be mostly Windows code. The Windows GUI certainly ties developers very closely to a Windows way of doing things (I have had many people tell me that porting to a non-Windows GUI was a lot of work, but then this statement seems to be generally true of porting between different GUIs).
Does Facebook’s support for the writing of simple apps make it a platform? Bill Gates thought not: “A platform is when the economic value of everybody that uses it, exceeds the value of the company that creates it.”, which some have called the Gates line.
The rise of open source has made it viable for substantial language ecosystems to flower, or rather substantial package ecosystems, with each based around a particular language. For practical purposes, language choice is now about the quality and quantity of their ecosystem. The dedicated followers of fashion like to tell everybody about the wonders of Go or Rust (in fashion when I wrote this post), but without a substantial package ecosystem, no language stands a chance of being widely used over the long term.
Major new software ecosystems have been created on a regular basis (regular, as in several per decade), e.g., mainframes in the 1960s, minicomputers and workstation in the 1970s, microcomputers in the 1980s, the Internet in the 1990s, smartphones in the 2000s, the cloud in the 2010s.
Will a major new software ecosystem come into being in the future? Major software ecosystems tend to be hardware driven; is hardware development now basically done, or should we expect something major to come along? A major hardware change requires a major new market to conquer. The smartphone has conquered a large percentage of the world’s population; there is no larger market left to conquer. Now, it’s about filling in the gaps, i.e., lots of niche markets that are still waiting to be exploited.
Software ecosystems are created through lots of people working together, over many years, e.g., the huge number of quality Python packages. Perhaps somebody will emerge who has the skills and charisma needed to get many developers to build a new ecosystem.
Software ecosystems can disappear; I think this may be happening with Perl.
Can a date be put on the start of the age of the Ecosystem? Ideas for defining the start of the age of the Ecosystem include:
- requiring a huge effort to port programs from one ecosystem to another. It used to be very difficult to port between ecosystems because they were so different (it has always been in vendors’ interests to support unique functionality). Using this method gives an early start date,
- by the amount of code/functionality in a program derived from third-party packages. In 2018, it’s certainly possible to write a relatively short Python program containing a huge amount of functionality, all thanks to third-party packages. Was this true for any ecosystems in the 1980s, 1990s?
Recent Comments