Archive
Economics chapter added to “Empirical software engineering using R”
The Economics chapter of my Empirical software engineering book has been added to the draft pdf (download here).
This is a slim chapter, it might grow a bit, but I suspect not by a huge amount. Reasons include lots of interesting data being confidential and me not having spent a lot of time on this topic over the years (so my stash of accumulated data is tiny). Also, a significant chunk of the economics data I have is used to discuss issues in the Ecosystems and Projects chapters, perhaps some of this material will migrate back once these chapters are finalized.
You might argue that Economics is more important than Human cognitive characteristics and should have appeared before it (in chapter order). I would argue that hedonism by those involved in producing software is the important factor that pushes (financial) economics into second place (still waiting for data to argue my case in print).
Some of the cognitive characteristics data I have been waiting for arrived, and has been added to this chapter (some still to be added).
As always, if you know of any interesting software engineering data, please tell me.
I am after a front cover. A woodcut of alchemists concocting a potion appeals, perhaps with various software references discretely included, or astronomy related (the obvious candidate has already been used). The related modern stuff I have seen does not appeal. Suggestions welcome.
Ecosystems next.
Is the ISO C++ standard’s committee past its sell by date?
The purpose of having a standard is economic. The classic (British) example is screw threads, having a standard set of screw threads means that products from different manufacturers are interchangeable and competition drives down prices; the US puts more emphasis on standards being an enabler of people interchangeability, i.e., train people once and they can use the acquired skills in multiple companies.
In the early days of computing we had umpteen compilers for Cobol, Fortran and then Pascal and then C and then C++. There were a lot of benefit to be had getting the vendors signed up to support a single standard for their language (of course they still added bells and whistles to ‘enhance’ their offerings). Language standard’s meeting were full of vendors, with a few end users (mostly from large corporations and government).
Fast forward to today and the ranks of compiler vendors has thinned significantly. Microfocus dominates Cobol, Fortran is dominated by a few number cruncher oriented companies, Pascal die hards cling on in surprising places, C vendors are till in double figures (down by an order of magnitude from its heyday) and C++ vendors will soon be accurately countable by Trolls (1, 2, 3, many).
What purpose does an ISO language standard serve in a world with only a few compilers? These days the standard is actually set by the huge volume of existing code that has to be handled by any vendor hoping to be adopted by developers.
The ISO C++ committee has become the playground of bored consultants looking for a creative outlet that work is not providing. Is there any red blooded developer who would not love spending a week, two or three times a year, holed up in a hotel with 100+ similarly minded people pouring over newly invented language features?
Does the world need all these new features in C++? Fortunately for the committee there are training companies who like nothing better than being able to offer ‘latest features of C++’ courses to all those developers who have been on previous ‘latest features of C++’ courses. Then there is the media, who just love writing about new stuff, there is even an ‘official’ C++ Standard news outlet.
In the good old days compiler vendors loved updates to the language standard because it gave them an opportunity to sell upgrades to customers; things are a bit different in the open source compiler market. What is the incentive of an open source compiler vendor to support features added by an ISO committee? In the past there has been a community expectation that it will happen, but is the ground swell of opinion enough to warrant spending resources on supporting new languages? Perhaps the GCC and LLVM folk will get together and mutually agree not to waste resources being the first mover.
Would developers at large notice if the C++ committee didn’t do anything for the next 10 years?
The Javascript ECMAscript standard also has a membership that includes many end users. In this case I suspect companies are sending people to make sure that new languages features don’t impact large code bases and existing investment in ways of doing things.
Update: I’m not saying that C++ language and libraries should stop evolving, but questioning the need to have an ISO Standard’s committee in a world of Open Source and a small number of compilers (that is likely to only become fewer).
Cost/performance analysis of 1944-1967 computers: Knight’s data
Changes In Computer Performance and Evolving Computer Performance 1963-1967, by Kenneth Knight, are the references to cite when discussing the performance of early computers. I suspect that very few people have read the two papers they are citing (citing without reading is a surprisingly common practice). Both papers were published in Datamation, a computer magazine whose technical contents could rival that of the ACM journals in the 1960s, but later becoming more of a trade magazine. Until the articles appeared on bitsavers.org they were only really available through national or major regional libraries.
Both papers contain lots of interesting performance and cost data on computers going back to the 1940s. However, I was not interested enough to type in all that data. This week I found high quality OCRed copies of the papers on the Internet Archive; my effort was reduced to fixing typos, which felt like less work.
So let’s try to reproduce Knight’s analysis of the data (code and data). Working in the mid-1960s, I imagine Knight did everything manually, with the help of mechanical calculators. I have the advantage of fancy software, a very fast computer and techniques that were invented after Knight did his analysis (e.g., generalized linear methods).
Each paper contains its own dataset: the first contains performance+cost data on 225 computers available between 1944 and 1963, while the second contains this information on 63 computers available between 1963 and 1967.
The dataset lists the computer name, the date it was introduced, number of operations per second and the number of seconds that can be rented for a dollar (most computer time used to be rented, then 25 years later personal computers came along and people got to own one, now, 25 years after that Cloud is causing a switch back to rental per second).
How are operations measured? The MIPS unit of measurement did not start to be generally used until the 1980s. Knight used 30 or so system characteristics, such as time to perform various arithmetic operations and I/O time, plus characteristics of scientific and commercial applications to calculate a value considered to be a representative scientific or commercial operation.
There is no mention of how seconds-per-dollar values were obtained. Did Knight ask customers or vendors? In a rental market, I imagine vendor pricing could be very flexible.
In the 1970s people started talking about Moore’s law, but in the 1960s there was Grosch’s law: Computer performance increases as the square of the cost, i.e., faster computers were cheaper to rent, for a given number of operations. Knight set out to empirically check Grosch’s law, i.e., he was looking for a quadratic fit.
Fitting a regression model to the 1950-1961 data, Knight obtained an exponent of 2.18, while I obtained 2.38 for commercial operations (using a slightly more sophisticated model, because I could); time on faster computers was cheaper than Grosch claimed. For scientific operations, Knight obtained 1.92, while I obtained 3.56; despite trying all sorts of jiggery-pokery I could not get a lower value. Unless Knight used very different values to the ones published in the ‘scientific’ columns, one of us has made a big mistake (please let me know if my code is wrong).
Fitting a regression model to the 1963-1967 data, I get figures (both around 2.85 and 2.94) that are roughly in agreement with Knight (2.5 and 3.1). Grosch’s law has broken down by 1963 (if it ever held for scientific operations).
The plot below shows operations per second against operationsseconds per dollar for the 1953-1961 data, with fitted lines for some specific years. It shows that while customers get fewer seconds per dollar on faster computers, the number of operations performed in those seconds is raised to the power of two+ (code and data):
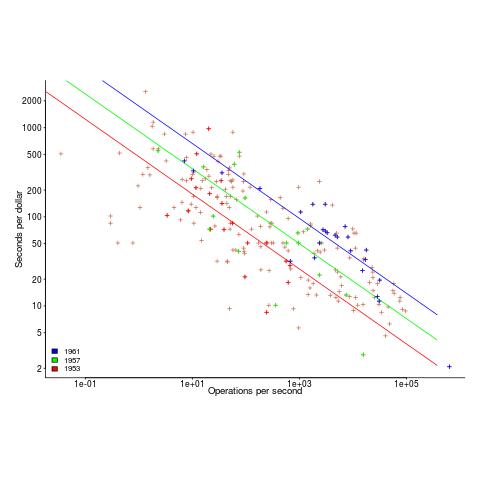
What other information can be extracted from the data? The 1953-1961 data shows seconds per dollar increased, over the whole performance range, by a factor of 1.15 per year, i.e., 15%, for both scientific and commercial; the 1963-1967 year-on-year increase jumps around a lot.
undefined behavior: pay up or shut up
Academia recently discovered undefined behavior in C, twenty five years after industry tool vendors first started trying to help developers catch the problems it causes. Some of the tools that are now being written are doing stuff that we could only dream about back in the day.
The forces that morph occurrences of undefined behavior in source code to unwanted behavior during program execution have changed over the years.
- When developers paid for their compilers there was an incentive for compiler writers to try to be nice to developers by doing the right thing for undefined behaviors. Twenty five years ago there were lots of commercial compilers all having slightly different views about what the right thing might be; a lot of code was regularly ported to different compilers and got to encounter different compiler writer’s views.
- These days there is widespread use of open source compilers, which developers don’t pay for, removing the incentive for compilers writers to be nice to developers. Paying customers want support for new processors, enhancements to existing generated code quality and the sexy topic for PhDs is code optimization; what better climate for treating source containing undefined behavior as road kill. Now developers only need to upgrade to a later release of the compiler they are using to encounter an unexpected handling of undefined behavior.
A recent blog post, authored by some of the academics alluded to above, proposes adding a new option to gcc: -std=friendly-c. If developers feel that this kind of option needs to be supported then they should contribute to a crowdfunding campaign (none exists at the time of writing) to raise, say, $500,000 towards supporting the creation and ongoing support for the functionality behind this option. Of course one developer’s friendly is another developer’s unfriendly, so we could end up with multiple funds each promoting an option that supports a view of the world that is specific to one target environment.
At the moment, in response to user complaints, Open source compiler vendors lamely point out that the C standard permits them to handle source containing undefined behaviors the way they do; they stop short of telling people to quit complaining and that they are getting the compiler for free.
If this undefined behavior issue starts to gain substantial publicity, but insufficient funding, open source compiler vendors will need to start putting a positive spin on the decisions they make. Not being in marketing I might have a problem keeping a straight face when giving the following positive messages:
- We are helping to save the world: optimized programs use less power (ok, every now and again they can use more). Do you really want to stop us adding more optimizations just because you cannot find the time to fix a mistake in your code?
- We are helping your application gain market share. Applications that are not actively maintained are less and less likely to continue to work with every release of the compiler.
Socrates 2014 unconference in the UK
I was at the Socrates unconference at the end of last week. An unconference is a conference with no prearranged speakers, the attendees turn up and some of them volunteer to talk about a topic of their choosing on the day. The talks were structured as half a dozen parallel sessions of an hour each in rooms dotted around two different buildings.
I had previously been to half a dozen or so of the London Software Craftsmanship meetups (there is a large overlap in the organizers of the two groups) and thought I had some understanding of how the community went about building software engineering knowledge. At the end of the first day this understanding underwent a major revamp (the arts and craft movement struck me as something of a parallel).
Based on the experience of one meeting I would say that the Socrates’ community approach to achieving the goals laid out in the Manifesto for Software Craftsmanship (as exemplified by those present at unconference) is primarily a social one based on personal experiences and shared experiences communicated through meetings and pair programming (yes, pair programming).
A great deal of pair programming was constantly going on and a person’s recent experience of pairing with somebody-or-other was a perfectly natural topic to bring up in casual conversation. I have never seen this kind of widespread community practice of interaction on a detailed before; I think it is great and I hope it spreads.
I volunteered to talk Friday morning about “When is it worth investing in reducing maintenance costs?” (I now have more data than used in my blog post on the topic). The talk did not go well in the sense that while people appeared to understood the analysis they did not seem to understand why anybody would want to use the decision making approach proposed. I got the same impression from people who asked me about the topic during food breaks (I had given a lightening talk Thursday evening with about half the attendees present).
The argument I made was that improving software is an investment intended to reduce future maintenance activities; like all investments the person making it wants receive a worthwhile return on the risk they are taking. The talk derived a requirement on the investment/benefit ratio needed for a code improvement activity to at least break even.
Now I am not always the world’s greatest communicator, so peoples’ lack of understanding may have been down to poor presentation on my part. But, in the evening, thinking about everything I had seen during the day I realised that my proposal for driving code improvement decisions using an economic model ran counter to the spirit of software craftsmanship as practiced by those present. This is not to say that the software craftsman are anti-economics, but that they want to be proud of their work and require that it meet certain personal and community standards, which may mean being less than economically efficient in some cases. At your average developer conference I would have expected zero interest, but here I had made the mistake of underestimating the strong craft influence and the socially derived approach (rather than trying to use experimental evidence) to finding solutions to software engineering problems.
There were a handful of people at the meeting interested in working towards a scientific approach to obtaining solutions to software engineering problems, i.e., using evidence derived from experiments. At one of the sessions a small group of us talked about how the software craftsman community might help researchers interested in experimental research (perhaps by helping to find professional subjects or by being willing to spend time discussing industry problems). I made my usual appeal for data that could be made public.
I suspect that many software craftsman would be interested in monitoring their own performance and that it would be worthwhile providing pointers to tools and techniques that might be used. Watch this space for progress.
The most interesting session I went to was by Steve Hayes who talked about his experience of starting and running a transparent company (this involves making information that companies usually keep confidential, such as employee, public). I had read about such companies before but this was my first encounter with somebody who had done it in practice.
The event appeared to run itself very smoothly, probably as much due to the invisible hard work of the organizers as much as the more visible attendee work. I would recommend the host venue, Farncombe conference centre, to anyone wanting to run a conference with lots of breakout rooms and social spaces. The food was high quality and artistically presented, demanding that both desserts on the menu be consumed.
Anybody who is in a rush to experience a Socrates unconference can visit Germany in August (a contingent from the UK are already booked).
Only compiler vendor customers, not its users, count
The hardest thing about working on compilers is getting somebody to pay you to do it (its a close run race against having the cpu instructions chop and change under you during initial development, but that’s another story). The major shift of compiler vendor business model from proprietary to open source has significant implications for users of compilers. Note I said user not customer, only one of them pays money. Under the commercial model there was usually a very direct connection between compiler user and customer (even in large organizations users rather than the manager who makes the purchase decision are often regarded by vendors as the customer), while under the Open source model most users are not customers (paying money for a distribution does not make you a customer of the people maintaining the compiler who probably don’t receive any of the money you spent).
Like all good businesses compiler vendors don’t want to make their customers unhappy. There is one way guaranteed to make all customers so unhappy that they will remember the experience for years; ship a new compiler release that breaks their existing code (this usually happens because their is a previously undetected bug in the code or because use is being made of an implemented defined/undefined part of the language {the compiler gets to decide what to do when it encounters such code}). Not breaking existing customer code is priority ONE in any commercial compiler development group.
Proprietary vendors have so many customers its almost impossible for them to know in advance what changes will break existing code and the only option is to be ultra conservative about adding new code optimizations (new optimizations can so easily change how source containing undefined behavior is processed). Ultra conservative is the polite term, management paranoia would be more accurate. There is another advantage to vendors for not breaking their customers’ code, they are protected against competition by new market entrants; a new vendor with a shiny go faster compiler doing all the optimizations the existing vendor was not willing to do in case it broke existing code will quickly find out that the performance improvements they offer are rarely big enough to tempt potential customers to switch compilers. Really, the only time companies switch compiler is when they have to port to a new platform to make a sale or their existing vendor goes bust.
Open source vendors (e.g., those commercially involved in support/maintenance of gcc or llvm) have relatively few customers (e.g., big companies paying them lots of money for specific reasons) and as always these customers want existing code to continue to work. If the customer is paying for a code generator for a previously unsupported processor then there probably isn’t any existing code for that processor; it is a fact of life that porting source to a new processor always involves work. Some Linux distributors (e.g., Suse and Redhat) are customers in the sense that they pay the salary of developers who spend a lot of their time in compiler maintenance/upgrades and presumably work to try and ensure that the code in their respective Linux distributions does not get broken.
Compiler users who are not customers don’t count on the code breakage front (well, count for very very little, if an update broke lots of different developers’ code and enough fuss was made there might well be an update than unbroke the previous one).
What can a user do if code that used to work ok is broken when compiled with a later version of the compiler? The obvious answer is to continue using the older version that produces the desired behavior, fixing the code causing the problem is a better answer (but might involve a lot of work). There is no point in flaming the compiler developers, you are not contributing towards their upkeep; Open source does not give users the consideration that a customer enjoys.
Ternary radix will have to wait for photonic computers
Computer cpu economics suggest that a ternary radix representation rather than binary should be used for representing integer values. The economic cost of a cpu is is roughly proportional to  , where
, where  is the integer radix and
is the integer radix and  is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is
is the width, in bits, of the basic integer type (for simplicity I’m assuming there is only one and that the bus width has the same value); the maximum value that can be represented is  .
.
If we fix the maximum representable value  and ask which value of minimises , then we need to differentiate
and ask which value of minimises , then we need to differentiate  w.r.t. , giving
w.r.t. , giving ^2})") and this equals 0 when
and this equals 0 when  (the closest integer to
(the closest integer to  is 3).
is 3).
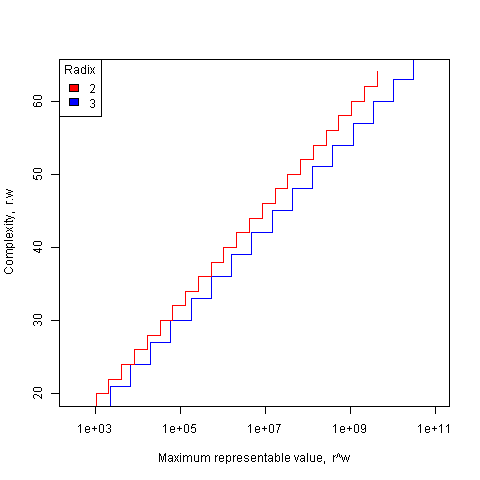
The following plot shows the maximum representable value (right point of horizontal line) that can be achieved for a given ‘cost’ when the radix is 2 and 3.
The reason binary is used in practice is purely to do with the characteristics of power consumption in electronic switching circuits (originally vacuum tube and then transistor based). Electrical power is proportional to voltage times current and a binary circuit can be implemented by switching between states where either the voltage or the current is very small, in either of these two states the power consumption is very low; it is only during the very short transition period switching between them, when the voltage and current have intermediate values, that the power consumed is relatively high. A 3-state switch would need a voltage/current combination denoting a state other than 0/1, and any such combination would consume non-trivial amounts of power (tri-state devices are used in some situations).
I have little idea about the complications of storing ternary values in memory systems, but I guess there will be complications.
In the 1960’s the Setun computer used a ternary radix and there has been the odd experimental systems since.
Are there any kinds of switching circuit whose use is not primarily dictated by device power characteristics and hence might be used to support a ternary radix? One possibility is a light based cpu (i.e., using photons rather than electrons), using polarization to specify state has been proposed. What about storage? Using Josephson junctions could provide the high speed and low power consumption required (we just need somebody to discover a room temperature superconductor).
The technology needed to build a practical cpu using a ternary radix appears to be some years in the future.
What about all the existing code containing a myriad of dependencies on the characteristics of two’s complement integer representation? If a photonic cpu became available that was ten times faster than existing cpus, or consumed 10 times less power or some combination thereof, then I’m sure here would be plenty of economic incentive to get software running on it. The problem is that 10 times better cpus are unlikely to just turn up, they will probably need to be developed in steps and the economics of progressing from step to step don’t look good.
While our civilization is likely to continue on down the binary rabbit hole, another one may have started down, or switched to, the ternary hole. I hope the SETI people are not to blinkered by the binary view of the universe.
Why do companies fix faults in software they sell?
Once I buy some software from a company they have my money, if sometime later I find a fault software what incentive does that company have to fix the software and provide me with an update (assuming the software is not so fault ridden that I take advantage of laws allowing me to return a purchase for a refund)?
There are three economic incentives for companies to fix faults:
- because I am paying them a fee for updates that include fixes to known faults,
- because they want to make future sales to me and to others (faults encountered by customers contribute towards the perception of product quality),
- they don’t want to lose money because a fault had consequences that resulted in legal action (this reason is overhyped, in practice software engineering has a missing dead body problem).
Which faults get fixed? Software is surprisingly fault-tolerant and there is no point in fixing faults that customers are unlikely to encounter. This means that once a product has been released and known to be acceptable to many customers, there is no incentive to actively search for faults; this means that the only faults likely to be fixed are the ones reported by customers.
When reporting a fault, customers are often asked to rate its severity. This is a useful technique for prioritizing what gets fixed first, or perhaps what does not get fixed at all. Customers who actively set out to find faults are not appreciated and are labelled as disruptive if they continue doing it. Finding faults is surprisingly easy, finding the faults that have a high probability of being encountered by customers and ranked by them as critical is very hard (this is one of the reasons static analysis tools are not widely used).
What is the motivation for developers to fix faults in Open Source?
- There are companies who provide support services for a fee, just like commercial offerings,
- Open Source is free, gaining more users is not an obvious incentive to fix faults. However, being known as the go-to guys for a given package is a way of attracting companies looking to hire somebody to provide support services or make custom modifications to that package. Fixing faults is a way of getting visibility, it is advertising.
- Developers hate the thought of doing something wrong resulting in a fault in code they have written, and writing faulty code is not socially acceptable behavior in software development circles. These feelings about what constitutes appropriate behavior are often enough to make developers want to spend time fixing faults in code they have written or feel responsible for, provided they have the time. I suspect a lot of faults get fixed by developers when their manager/wife thinks they are working on something more ‘useful’.
Licensing to decide the result of gcc vs llvm?
I was not surprised to hear today that Nvidia are halting development of their in-house C/C++ compiler and switching to one of the Open Source compilers. It is a lot cheaper to have one or two people looking after a company’s interests in a compiler developed by somebody else than having an in-house development group. It will be interesting to see how much longer Intel continues to fund their in-house compiler.
Nvidia chose llvm and gave a variety of technical reasons why this was the best choice over gcc.
One advantage (from Nvidia’s point of view) not mentioned is that llvm is licensed under a BSD style agreement. This means Nvidia don’t have to release the source code of any modifications or additions they make (they said these will be kept closed source); gcc is licensed under the GNU General Public License which requires source to be released. Arch rivals AMD (well, the ATI bit of AMD that does graphics hardware) also promote llvm, and I’m sure Nvidia does not want to help them in any way.
The licensing difference between gcc and llvm has the potential to make a big difference to the finances of both development teams.
My understanding of gcc funding is that most of it comes from back-end work (i.e., a company pays to have gcc work or do a better job on some [I imagine their] processor). Given a choice, would these companies rather release the source they paid to have written/modified or keep it closed? Some probably don’t care and hope that by making the source available others will help find and fix problems (i.e., there is a benefit to making it available), on the other hand companies introducing processors with fancy new features will want to minimise any technology that competitors can get for free.
In the years to come, it is possible that gcc will loose a significant amount of this back-end income to llvm because of licensing.
PhD projects are the life-blood of new compiler optimization techniques and for many years source code from them has often ended up as the experimental version of a new optimization phase of gcc. Many students are firm believers in making source freely available and shy away from being involved in non-GPL projects. Will this deter them from using llvm in their research (there may be a growing trend favoring llvm over gcc in research, or the llvm people may be better than the gcc folk at marketing {not hard})?
If llvm does not get the new fancy optimizations for ‘free’ they are going to have to spend money doing the implementing themselves or have their performance slowly fall behind that of gcc. Will this cost be more or less than the additional income from closed source customers?
We are unlikely to know the impact that licensing has on the fortunes of both compilers until the end of this decade. Perhaps designing and building a new processor will not be economically worthwhile in 10 years, perhaps all the worthwhile optimizations will be done. We will have to wait and see.
Update 4 Jan 2012: Video (235M) of talk on status of effort to make llvm the default compiler in FreeBSD at LLVM 2011 Developer’s meeting.
ISO Standards, the beauty and the beast
Standards is one area where a monopoly can provide a worthwhile benefit. After all the primary purpose of a standard for something is having just the one document for everybody to follow (having multiple standards because they are so useful is not a good idea). However, a common problem with monopolies is that charge a very inflated price for their product.
Many years ago the International Standard Organization settled on a pricing scheme for ISO Standards based on document page count. Most standards are very short and have a very small customer base, so there is commercial logic to having a high cost per page (especially since most are bought by large companies who need a copy if they do business in the corresponding application domain). Programming language standards do not fit this pattern, often being very long and potentially having a very large customer base.
With over 18,500 standards in their catalogue ISO might be forgiven for overlooking the dozen or so language standards, or perhaps they figured there is as much profit in charging a few hundred pounds on a few sales as charging less on more sales.
How does the move to electronic distribution effect prices? For a monopoly electronic distribution is an opportunity to make more profit, not to reduce prices. The recently published revision of the Fortran Standard is available for 338 Swiss francs (around £232) from ISO and £356 from BSI (at $351 the price from ANSI in the US is similar to ISO’s). Many years ago, at the dawn of the Internet, members of the US C Standard committee were able to convince ANSI to sell electronic copies at a reasonable rate ($30) and this practice has continued ever since (and now includes C++).
The market for the C and C++ Standards is sufficiently large that a commercial publisher (Wiley) was willing to take the risk of publishing them in book form (after some prodding and leg work by the likes of Francis Glassborow). It will be interesting to see if a publisher is willing to take a chance on a print run of the revised C Standard due out in a few years (I think the answer for the revised C++ Standard is more obvious).
Don’t Standards bodies care about computer languages? Unfortunately we are thorn in their side and they would be happy to be rid of us (but their charter’s do not allow them to do this). Our standards take much longer to produce than other standards, they are large and sales are almost non-existent (at ISO/BSI prices). What is more many of those involved in creating these standards actively subvert ISO/BSI sales by making draft documents, that are very close to the final copyrighted versions, freely available over the Internet.
In a sense ISO programming language standards exist because the organizational structure requires them to accept our work proposals and what we do does not have a large enough impact within the standards world for them to try and be rid of those tiresome people whose work is so far removed from what everybody else does.
Recent Comments