Archive
Decline in downloads of once popular packages
What happens to the popularity of Open source packages, measured in monthly downloads, once they cease to be updated or attract new users?
If the software does not have any competition within its domain, there is no reason why its popularity should decline. In practice, there are usually alternative packages offering the same or similar functionality. Even when alternatives are available, existing practice and sunk costs can slow migration. A year or so after I started using Asciidoc to write by Software Engineering book, the author announced that he was no longer going to update the software; initially there was no alternative, but the software did what I wanted, and I have been happily using it over the last 12 years.
The paper: Do All Software Projects Die When Not Maintained? Analyzing Developer Maintenance to Predict OSS Usage by Emily Nguyen measured the monthly downloads, commits and other characteristics of 38K GitHub packages having at least 10K downloads during any month between January 2015 and December 2020. The data made available (more here) is a subset, i.e., downloads for 1,583 projects starting in May 2015.
The author investigated the connection between various project characteristics (focusing on commits or lack thereof in particular) and downloads by fitting a Cox proportional hazards model.
The plot below shows the 67 monthly downloads for a selection of packages; the red line is a fitted local regression used to smooth the data (code and data):

Reasons for a decline from a peak number of downloads include: competition from alternative packages, change of fashion, and market saturation, or perhaps the peak was caused by a one-off event. Whatever the reason for a peak+decline, my interest is learning about patterns in the rate of decline.
Some of the monthly package downloads in the above plot have an obvious peak and decline, with others continually increasing, and others having multiple peaks. The following algorithm was used to select packages having a peak followed by a decline, based on the predicted values from a fitted loess model:
- find the month with the most downloads, this is the primary peak,
- if this month is within 10 months of the end of the measurement period, this is not a peak/decline package,
- does a secondary peak exist? A secondary peak is a month containing the most downloads from 10 months after the end of the primary peak, where the number of downloads is within 66% of the primary peak downloads,
- the secondary peak becomes the primary peak, provided it is not within 10 months of the end of the measurement period.
The final fraction of the primary peak is the average monthly download during the last three months divided by the peak month downloads.
The plot below shows the 693 packages whose final fraction of peak was below 0.6 against months from peak to the last month (at the end of 2020), with the red line showing a fitted regression of the form  (code and data):
(code and data):

As the above plot shows, there don’t appear to be any patterns in the decline of package downloads, and  is a poor predictor of fraction of peak.
is a poor predictor of fraction of peak.
Perhaps a more sophisticated peak+decline selection algorithm will uncover some patterns. Both ChatGPT (its generated python script failed) and Grok (very wrong answers) failed miserably at classifying the plots. Deepseek will only process images to extract text.
Evidence-based book: six months of downloads
When my C book was first made available as a freely downloadable pdf, in 2005, there were between 19k to 37k downloads in the first week. The monthly download rate remained stable at around 1k per month for several years, and now floats around 100 per month.
I was hoping to have many more downloads for my Evidence-based software engineering book. The pdf became available last year on November 8th, and there were around 10k downloads in the first week. Then a link to my blog post announcing the availability of the book was posted to news.ycombinator. That generated quarter million downloads of the pdf, with an end-of-month figure of 275,309 plus 16,135 for the mobile friendly version.
The initial release did not include a mobile friendly version. After a half-a-dozen or so requests in various forums, I quickly worked up a mobile friendly pdf (i.e., the line length was reduced to be visually readable on a mobile phone, or at least on my 7-year-old phone which is smaller than most).
In May a link to the book’s webpage was posted on news.ycombinator. This generated 125k+ downloads, and the top-rated comment was that this was effectively a duplicate of the November post.
The plot below shows the number of pdf downloads for A4 and mobile formats, along with the number of kilo-bytes downloaded, for the 6-months since the initial release (code+data):
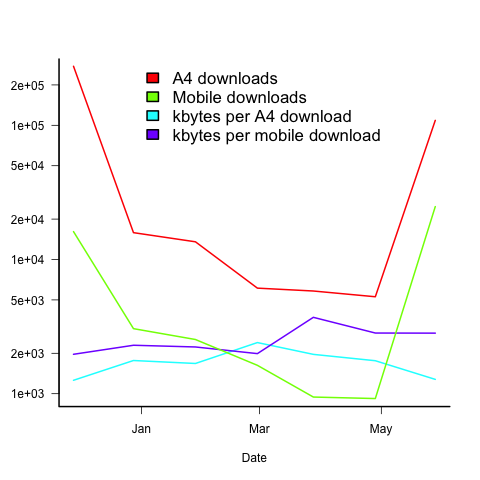
On average, there are five A4 downloads per mobile download (excluding November because of the later arrival of a mobile friendly version).
A download is rarely a complete copy (which is 23Mbyte), with the 6-month average being 1.7M for A4 and 2.5M for mobile. I have no idea of the reason for this difference.
The bytes per download is lower in the months when the ycombinator activity occurred. Is this because the ycombinator crowd tend to skim content (based on some of the comments, I suspect that many comments never read further than the cover)?
Copies of the pdf were made available on other sites, but based on the data I have seen, the downloads were not more than a few thousand.
I have not had any traffic spikes caused by non-English language interest. The C book experienced a ‘China’ spike, and I emailed the author of the blog post that caused it, to notify him of the Evidence-based book; he kindly posted an article on the book, but this did not generate a noticeable spike.
I’m confident that eventually a person in China/Russia/India/etc, with tens of thousands of followers, will post a link and there will be a noticeable download spike from that region.
What was the impact of content delivery networks and ISP caching? I have no idea. Pointers to write-ups on the topic welcome.
Recent Comments