Archive
Double exponential performance hit in C# compiler
Yesterday I was reading a blog post on the performance impact of using duplicated nested types in a C# generic class, such as the following:
class Class<A, B, C, D, E, F> { class Inner : Class<Inner, Inner, Inner, Inner, Inner, Inner> { Inner.Inner inner; } } |
Ah, the joys of exploiting a language specification to create perverse code 🙂
The author, Matt Warren, had benchmarked the C# compiler for increasing numbers of duplicate types; good man. However, the exponential fitted to the data, in the blog post, is obviously not a good fit. I suspected a double exponential might be a better fit and gave it a go (code+data).
Compile-time data points and fitted double-exponential below:
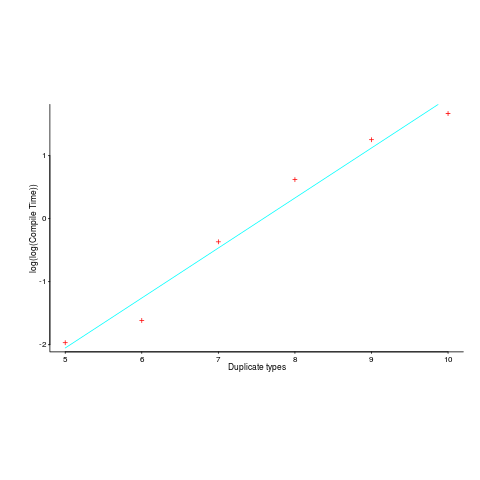
Yes, for compile time the better fit is:  and for binary size:
and for binary size:  , where
, where  ,
,  are some constants and
are some constants and  the number of duplicates.
the number of duplicates.
I had no idea what might cause this pathological compiler performance problem (apart from the pathological code) and did some rummaging around. No luck; I could not find any analysis of generic type implementation that might be used to shine some light on this behavior.
Ideas anybody?
Recent Comments