Archive
Has the seed that gets software development out of the stone-age been sown?
A big puzzle for archaeologists is why Stone Age culture lasted as long as it did (from approximately 2.5 millions years ago until the start of the copper age around 6.3 thousand years ago). Given the range of innovation rates seen in various cultures through-out human history, a much shorter Stone Age is to be expected. A recent paper proposes that low population density is what maintained the Stone Age status quo; there was not enough contact between different hunter gather groups for widespread take up of innovations. Life was tough, and the viable lifetime of individual groups of people may not have been long enough for them to be likely to pass on innovations (either their own ones encountered through contact with other groups).
Software development is often done by small groups that don’t communicate with other groups and regularly die out (well there is a high turn-over, with many of the more experienced people moving on to non-software roles). There are sufficient parallels between hunter gathers and software developers to suggest both were/are kept in a Stone Age for the same reason, lack of a method that enables people to obtain information about innovations and how worthwhile these might be within a given environment.
A huge barrier to the development of better software development practices is the almost complete lack of significant quantities of reliable empirical data that can be used to judge whether a claimed innovation is really worthwhile. Companies rarely make their detailed fault databases and product development history public; who wants to risk negative publicity and lawsuits just so academics have some data to work with.
At the start of this decade, public source code repositories like SourceForge and public software fault repositories like Bugzilla started to spring up. These repositories contain a huge amount of information about the characteristics of the software development process. Questions that can be asked of this data include: what are common patterns of development and which ones result in fewer faults, how does software evolve and how well do the techniques used to manage it work.
Empirical software engineering researchers are now setting up repositories, like Promise, containing the raw data from their analysis of Open Source (and some closed source) projects. By making this raw data available, they are reducing the effort needed by other researchers to investigate their own alternative ideas (I have just started a book on empirical software engineering using the R statistical language that uses examples based on this raw data).
One of the side effects of Open Source development could be the creation of software development practices that have been shown to be better (including showing that some existing practices make things worse). The source of these practices not being what the software developers themselves do or how they do it, but the footsteps they have left behind in the sand.
To if-else-if or if-if, that is the question
I am currently measuring if-statements, occurring in visible source, that might be mapped to an equivalent switch-statement. The most obvious usage to look for is a sequence of if-else-if statements that all involve the same expression being tested against an integer constant, as in
if (x == 1) stmt_1; else if (x == 2) stmt_2; else if (x == 3) stmt_3; |
Another possible sequence is:
if (x == 1) stmt_1; if (x == 2) stmt_2; if (x == 3) stmt_3; |
provided all but the last conditionally executed arms do not change the value of the common control variable (e.g., x).
I started to wonder about what would cause a developer to chose one of these forms over the other. Perhaps the if-if form would be used when it was obvious that the common conditional variable was not modified in the conditionally executed arm. This would imply that there would be more statements in the arms of if-else-if sequences than if-if sequences. The following plot of percentage occurrence (over all detected if-else-if/if-if forms) of line number difference between pars of associated if-statements (e.g., when the controlling expression occurs on line
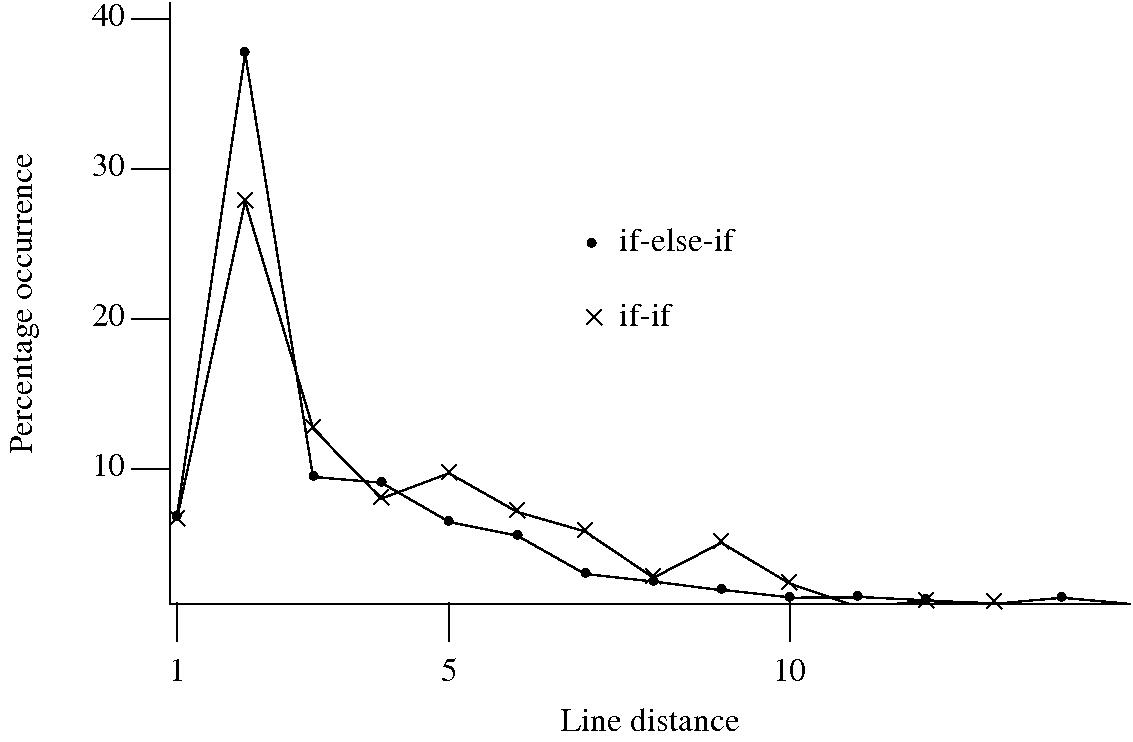
Just over a quarter of the arms contain a single statement (or to be exact the code is contained on a single line); this suggests that when using the if-else-if form most developers put the else and if on the same line. At the next distance along the percentage of if-else-if forms is twice as great as the if-if, probably because of else and if appearing on separate lines (as in the introductory example) in one case and less frequently a comment/blank line in the other. Next along, why the big increase in if-if forms? A comment + blank line, or perhaps no comment or blank line but the use of curly brackets (this is too off the track of where I am supposed to be going to investigate).
This morning I realized why the original plot did not look right, one of the data sets was a way off adding to 100%. An updated version has been uploaded.
It turns out that a single statement (or at least a single line) is more common in the if-else-if form, the opposite of what I had expected. At slightly larger distances there are still differences that can be attributed to else and if appearing on separate lines, curly brackets and a comment/blank line, but the effect is not as large as seen in the original, less accurate, plot.
I have a feeling that I ought to say something about the if-else-if form being preferred to the if-if form. One of the forms will have its behavior changed if the common control variable is modified in one of its arms. But is this an intended or unintended behavior? What is the typical characteristic usage of a common control variable, e.g., do they tend to be accessed but not modified in a given function definition? At the moment I see no obvious cost or benefit strongly favoring one usage over the other, so I will remain silent on the issue.
Recommendations for teachers of programming
The software developers I deal with usually have at least 3 or more years professional experience in industry (I have not taught a beginners programming class in over 25 years) and these recommendations are based on what I tell these people. I like to think that they are applicable to teaching those with a lot less experience.
First. Application domain expertise generally has greater value than programming expertise. That is, an investment of time in learning the application domain will yield a greater return on investment that learning more programming techniques.
Implications:
Second. Computer time is cheap, people time is expensive.
Implications:
Third. Most software is written to solve an immediate problem, used a few times, and then forgotten about (I know of software projects costing in the millions where the code was never used; my own contribution to never used code is somewhat smaller, but still much larger than I would have liked). The point is that writing software involves a cost/benefit trade-off, how much should I invest in making code maintainable given the risk that the benefits from this investment may not be recouped.
Implications:
Fourth. Don’t fool yourself that you are teaching programming; you probably just give a lecture or two and expect students to pick up the details from one of the assigned course books.
Implications:
Fifth. Coding style does exist and can have an effect on the cost of writing and maintaining code as well as how well a compiler can optimize it. These costs and benefits vary with the context in which the code was created and used. A good programmer will adopt a coding style appropriate to the context, just like an actor plays a role with the appropriate characterization (eg, comedy, thriller, suspense). It takes more experience than most undergraduate have to be able to properly discern what style is being used, let alone be capable of changing their own style.
Implications:
Recent Comments