Archive
Algorithm complexity and implementation LOC
As computer functionality increases, it becomes easier to write programs to handle more complicated problems which require more computing resources; also, the low-hanging fruit has been picked and researchers need to move on. In some cases, the complexity of existing problems continues to increase.
The Linux kernel is an example of a solution to a problem that continues to increase in complexity, as measured by the number of lines of code.
The distribution of problem complexities will vary across application domains. Treating program size as a proxy for problem complexity is more believable when applied to one narrow application domain.
Since 1960, the journal Transactions on Mathematical Software has been making available the source code of implementations of the algorithms provided with the papers it publishes (before the early 1970s they were known as the Collected Algorithms of the ACM, and included more general algorithms). The plot below shows the number of lines of code in the source of the 893 published implementations over time, with fitted regression lines, in black, of the form  before 1994-1-1, and
before 1994-1-1, and  after that date (black dashed line is a LOESS regression model; code+data).
after that date (black dashed line is a LOESS regression model; code+data).
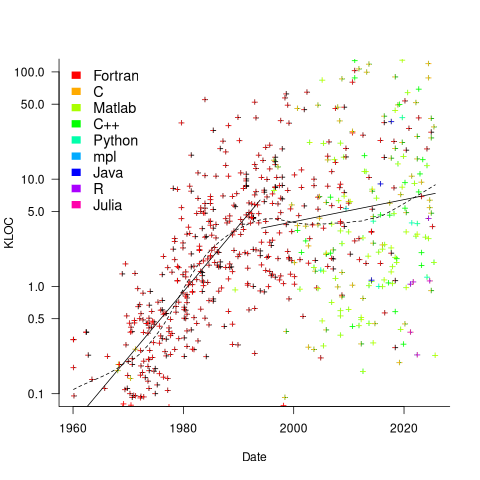
The two immediately obvious patterns are the sharp drop in the average rate of growth since the early 1990s (from 15% per year to 2% per year), and the dominance of Fortran until the early 2000s.
The growth in average implementation LOC might be caused by algorithms becoming more complicated, or because increasing computing resources meant that more code could be produced with the same amount of researcher effort, or another reason, or some combination. After around 2000, there is a significant increase in the variance in the size of implementations. I’m assuming that this is because some researchers focus on niche algorithms, while others continue to work on complicated algorithms.
An aim of Halstead’s early metric work was to create a measure of algorithm complexity.
If LLMs really do make researchers more productive, then in future years LOC growth rate should increase as more complicated problems are studied, or perhaps because LLMs generate more verbose code.
The table below shows the primary implementation language of the algorithm implementations:
Language Implementations
Fortran 465
C 79
Matlab 72
C++ 24
Python 7
R 4
Java 3
Julia 2
MPL 1 |
If algorithms are becoming more complicated, then the papers describing/analysing them are likely to contain more pages. The plot below shows the number of pages in the published papers over time, with fitted regression line of the form  (0.38 pages per year; red dashed line is a LOESS regression model; code+data).
(0.38 pages per year; red dashed line is a LOESS regression model; code+data).
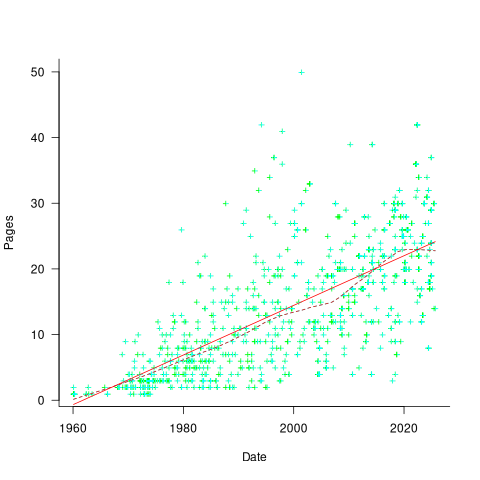
Unlike the growth of implementation LOC, there is no break-point in the linear growth of page count. Yes, page count is influence by factors such as long papers being less likely to be accepted, and being able to omit details by citing prior research.
It would be a waste of time to suggest more patterns of behavior without looking at a larger sample papers and their implementations (I have only looked at a handful).
When the source was distributed in several formats, the original one was used. Some algorithms came with build systems that included tests, examples and tutorials. The contents of the directories: CALGO_CD, drivers, demo, tutorial, bench, test, examples, doc were not counted.
Complex software makes economic sense
Economic incentives motivate complexity as the common case for software systems.
When building or maintaining existing software, often the quickest/cheapest approach is to focus on the features/functionality being added, ignoring the existing code as much as possible. Yes, the new code may have some impact on the behavior of the existing code, and as new features/functionality are added it becomes harder and harder to predict the impact of the new code on the behavior of the existing code; in particular, is the existing behavior unchanged.
Software is said to have an attribute known as complexity; what is complexity? Many definitions have been proposed, and it’s not unusual for people to use multiple definitions in a discussion. The widely used measures of software complexity all involve counting various attributes of the source code contained within individual functions/methods (e.g., McCabe cyclomatic complexity, and Halstead); they are all highly correlated with lines of code. For the purpose of this post, the technical details of a definition are glossed over.
Complexity is often given as the reason that software is difficult to understand; difficult in the sense that lots of effort is required to figure out what is going on. Other causes of complexity, such as the domain problem being solved, or the design of the system, usually go unmentioned.
The fact that complexity, as a cause of requiring more effort to understand, has economic benefits is rarely mentioned, e.g., the effort needed to actively use a codebase is a barrier to entry which allows those already familiar with the code to charge higher prices or increases the demand for training courses.
One technique for reducing the complexity of a system is to redesign/rework its implementation, from a system/major component perspective; known as refactoring in the software world.
What benefit is expected to be obtained by investing in refactoring? The expected benefit of investing in redesign/rework is that a reduction in the complexity of a system will reduce the subsequent costs incurred, when adding new features/functionality.
What conditions need to be met to make it worthwhile making an investment,  , to reduce the complexity,
, to reduce the complexity,  , of a software system?
, of a software system?
Let’s assume that complexity increases the cost of adding a feature by some multiple (greater than one). The total cost of adding  features is:
features is:

where:  is the system complexity when feature
is the system complexity when feature  is added, and
is added, and  is the cost of adding this feature if no complexity is present.
is the cost of adding this feature if no complexity is present.
 ,
,  , …
, … 
where:  is the base complexity before adding any new features.
is the base complexity before adding any new features.
Let’s assume that an investment, , is made to reduce the complexity from  (with
(with  ) to
) to  , where
, where  is the reduction in the complexity achieved. The minimum condition for this investment to be worthwhile is that:
is the reduction in the complexity achieved. The minimum condition for this investment to be worthwhile is that:
 or
or 
where:  is the total cost of adding new features to the source code after the investment, and
is the total cost of adding new features to the source code after the investment, and  is the total cost of adding the same new features to the source code as it existed immediately prior to the investment.
is the total cost of adding the same new features to the source code as it existed immediately prior to the investment.
Resetting the feature count back to  , we have:
, we have:
*F_1+(C_B+C_N+C_2)*F_2+...+(C_B+C_N+C_m)*F_m")
and
*F_1+(C_B+C_N-C_R+C_2)*F_2+...+(C_B+C_N-C_R+C_m)*F_m")
and the above condition becomes:
-(C_B+C_N-C_R+C_1))*F_1+...+((C_B+C_N+C_m)-(C_B+C_N-C_R+C_m))*F_m")


The decision on whether to invest in refactoring boils down to estimating the reduction in complexity likely to be achieved (as measured by effort), and the expected cost of future additions to the system.
Software systems eventually stop being used. If it looks like the software will continue to be used for years to come (software that is actively used will have users who want new features), it may be cost-effective to refactor the code to returning it to a less complex state; rinse and repeat for as long as it appears cost-effective.
Investing in software that is unlikely to be modified again is a waste of money (unless the code is intended to be admired in a book or course notes).
Complexity is a source of income in open source ecosystems
I am someone who regularly uses R, and my interest in programming languages means that on a semi-regular basis spend time reading blog posts about the language. Over the last year, or so, I had noticed several patterns of behavior, and after reading a recent blog post things started to make sense (the blog post gets a lot of things wrong, but more of that later).
What are the patterns that have caught my attention?
Some background: Hadley Wickham is the guy behind some very useful R packages. Hadley was an academic, and is now the chief scientist at RStudio, the company behind the R language specific IDE of the same name. As Hadley’s thinking about how to manipulate data has evolved, he has created new packages, and has been very prolific. The term Hadley-verse was coined to describe an approach to data manipulation and program structuring, based around use of packages written by the man.
For the last nine-months I have noticed that the term Tidyverse is being used more regularly to describe what had been the Hadley-verse. And???
Another thing that has become very noticeable, over the last six-months, is the extent to which a wide range of packages now have dependencies on packages in the HadleyTidyverse. And???
A recent post by Norman Matloff complains about the Tidyverse’s complexity (and about the consistency between its packages; which I had always thought was a good design principle), and how RStudio’s promotion of the Tidyverse could result in it becoming the dominant R world view. Matloff has an academic world view and misses what is going on.
RStudio, the company, need to sell their services (their IDE is clunky and will be wiped out if a top of the range product, such as Jetbrains, adds support for R). If R were simple to use, companies would have less need to hire external experts. A widely used complicated library of packages is a god-send for a company looking to sell R services.
I don’t think Hadley Wickam intentionally made things complicated, any more than the creators of the Microsoft server protocols added interdependencies to make life difficult for competitors.
A complex package ecosystem was probably not part of RStudio’s product vision, at least for many years. But sooner or later, RStudio management will have realised that simplicity and ease of use is not in their interest.
Once a collection of complicated packages exist, it is in RStudio’s interest to get as many other packages using them, as quickly as possible. Infect the host quickly, before anybody notices; all the while telling people how much the company is investing in the community that it cares about (making lots of money from).
Having this package ecosystem known as the Hadley-verse gives too much influence to one person, and makes it difficult to fire him later. Rebranding as the Tidyverse solves these problems.
Matloff accuses RStudio of monopoly behavior, I would have said they are fighting for survival (i.e., creating an environment capable of generating the kind of income a VC funded company is expected to make). Having worked in language environments where multiple, and incompatible, package ecosystems existed, I can see advantages in there being a monopoly. Matloff is also upset about a commercial company swooping in to steal their precious, a common academic complaint (academics swooping in to steal ideas from commercially developed software is, of course, perfectly respectable). Matloff also makes claims about teachability of programming that are not derived from any experimental evidence, but then everybody makes claims about programming languages without there being any experimental evidence.
RStudio management rode in on the data science wave, raising money from VCs. The wave is subsiding and they now need to appear to have a viable business (so they can be sold to a bigger fish), which means there has to be a visible market they can sell into. One way to sell in an open source environment is for things to be so complicated, that large companies will pay somebody to handle the complexity.
McCabe’s cyclomatic complexity and accounting fraud
The paper in which McCabe proposed what has become known as McCabe’s cyclomatic complexity did not contain any references to source code measurements, it was a pure ego and bluster paper.
Fast forward 10 years and cyclomatic complexity, complexity metric, McCabe’s complexity…permutations of the three words+metrics… has become one of the two major magical omens of code quality/safety/reliability (Halstead’s is the other).
It’s not hard to show that McCabe’s complexity is a rather weak measure of program complexity (it’s about as useful as counting lines of code).
Just as it is possible to reduce the number of lines of code in a function (by putting all the code on one line), it’s possible to restructure existing code to reduce the value of McCabe’s complexity (which is measured for individual functions).
The value of McCabe’s complexity for the following function is 5 16, i.e., and there are 16 possible paths through the function:
int main(void) { if (W) a(); else b(); if (X) c(); else d(); if (Y) e(); else f(); if (Z) g(); else h(); } |
each if…else contains two paths and there are four in series, giving  paths.
paths.
Restructuring the code, as below, removes the multiplication of paths caused by the sequence of if…else:
void a_b(void) {if (W) a(); else b();} void c_d(void) {if (X) c(); else d();} void e_f(void) {if (Y) e(); else f();} void g_h(void) {if (Z) g(); else h();} int main(void) { a_b(); c_d(); e_f(); g_h(); } |
reducing main‘s McCabe complexity to 1 and the four new functions each have a McCabe complexity of two.
Where has the ‘missing’ complexity gone? It now ‘exists’ in the relationship between the functions, a relationship that is not included in the McCabe complexity calculation.
The number of paths that can be traversed, by a call to main, has not changed (but the McCabe method for counting them now produces a different answer)
Various recommended practice documents suggest McCabe’s complexity as one of the metrics to consider (but don’t suggest any upper limit), while others go as far as to claim that it’s bad practice for functions to have a McCabe’s complexity above some value (e.g., 10) or that “Cyclomatic complexity may be considered a broad measure of soundness and confidence for a program“.
Consultants in the code quality/safety/security business need something to complain about, that is not too hard or expensive for the client to fix.
If a consultant suggested that you reduced the number of lines in a function by joining existing lines, to bring the count under some recommended limit, would you take them seriously?
What about, if a consultant highlighted a function that had an allegedly high McCabe’s complexity? Should what they say be taken seriously, or are they essentially encouraging developers to commit the software equivalent of accounting fraud?
Recent Comments