Archive
Measuring non-determinism in the Linux kernel
Developers often assume that it’s possible to predict the execution path a program will take, for a given set of input values, i.e., program behavior is deterministic. The execution path may be very complicated, and may depend on the contents of certain files (e.g., SQL engines), but it’s deterministic.
There is one kind of program where determinism is not an option; operating systems are non-deterministic when running in a mode where interrupts can occur.
How much non-determinism can occur in, say, Linux? For instance, when a program calls a system function (e.g., open, read, write, close), how often does the execution sequence follow the function call tree that appears in the source code, and how many different call sequences actually occur during program execution (because of diversions caused by an interrupt; ignoring control flow within functions)?
A study by Imanol Allende ran the same program 500K+ times, and traced every function call that occurred within the Linux kernel (thanks to Imanol for sending me the data and answering my questions). The program used appears below; the system calls traced were open (two distinct calls), read, write, and close (two distinct calls); a total of six system calls.
// #includes omitted int main(int argc, char **argv) { unsigned char result; int fd1, fd2, ret; char res_str[10]={0}; fd1 = open("/dev/urandom", O_RDONLY); fd2 = open("/dev/null", O_WRONLY); ret = read(fd1 , &result, 1); sprintf(res_str ,"%d", result); ret = write(fd2, res_str, strlen(res_str)); close(fd1); close(fd2); return ret; } |
Analysing each of these six distinct calls, in around 98% of program runs, each call follows the same sequence of function calls within the kernel (the common case for write involves a chain of around 10 function calls). During the other 2’ish% of calls, the common sequence was interrupted for some reason, and the logged call trace includes additional called functions, e.g., calls involving the Read, Copy, Update synchronization mechanism. The plot below shows the growth in the number of unique traces against the number of program runs (436,827 of them) for the close(fd2) call; a fitted regression line is in red, with the first 1,000 runs not included in the fit (code+data):
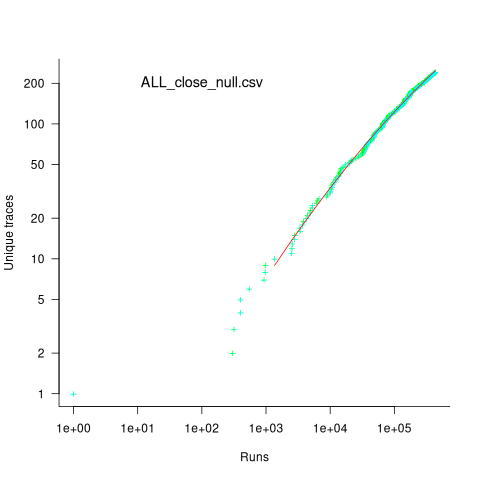
The fitted regression model is ^2") , suggesting that the growth in unique traces is slowing (this equation peaks at around
, suggesting that the growth in unique traces is slowing (this equation peaks at around  ), while the model fitted to some of the system calls implies ever continuing growth.
), while the model fitted to some of the system calls implies ever continuing growth.
Allende investigated more sophisticated techniques for estimating the total number of unique traces, including: extreme value theory and species estimation techniques from ecology.
While around 98% of traces are the common case, over half of the unique traces occurred once in 436,827 runs. The plot below shows the number of occurrences of each unique trace, for the close(fd2) call, with an attempted fit of a bi-exponential model (in red; code+data):
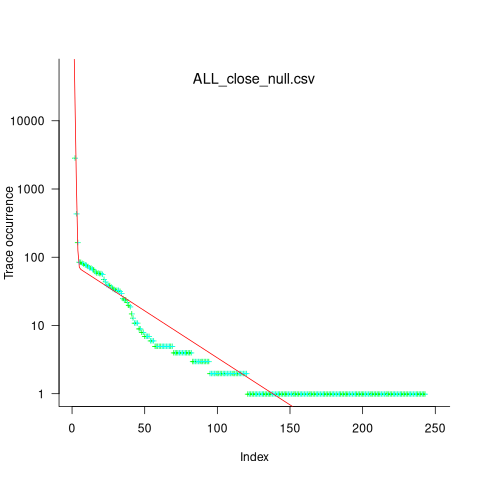
The analysis above looked at one system call, the program contains six system calls. If, for each system call, the probability of the most common trace is 98%, then the probability of all six calls following their respective common case is 89%. As the number of distinct system calls made by a program goes up, the global common case becomes less common, and the number of distinct program traces increases multiplicatively.
Parsing without a symbol table
When processing C/C++ source for the first time through a compiler or static analysis tool there are invariably errors caused by missing header files (often because the search path has not been set) or incorrectly defined, or not defined, macro names. One solution to this configuration problem is to be able to process source without handling preprocessing directives (e.g., skipping them, such as not reading the contents of header files or working out which arm of a conditional directive is applicable). Developers can do it, why not machines?
A few years ago GLR support was added to Bison, enabling it to process ambiguous grammars, and I decided to create a C parser that simply skipped all preprocessing directives. I knew that at least one reasonably common usage would generate a syntax error:
func_call(a, #if SOME_FLAG b_1); #else b_2); #endif |
c);
and wanted to minimize its consequences (i.e., cascading syntax errors to the end of the file). The solution chosen was to parse the source a single statement or declaration at a time, so any syntax error would be localized to a single statement or declaration.
Systems for parsing ambiguous grammars work on the basis that while the input may be locally ambiguous, once enough tokens have been seen the number of possible parses will be reduced to one. In C (and even more so in C++) there are some situations where it is impossible to resolve which of several possible parses apply without declaration information on one or more of the identifiers involved (a traditional parser would maintain a symbol table where this information could be obtained when needed). For instance, x * y; could be a declaration of the identifier y to have type x or an expression statement that multiplies x and y. My parser did not have a symbol table and even if it did the lack of header file processing meant that its contents would only contain a partial set of the declared identifiers. The ambiguity resolution strategy I adopted was to pick the most likely case, which in the example is the declaration parse.
Other constructs where the common case (chosen by me and I have yet to get around to actually verifying via measurement) was used to resolve an ambiguity deadlock included:
f(p); // Very common, // confidently picked function call as the common case (m)*p; // Not rare, // confidently picked multiplication as the common case (s) - t; // Quiet rare, // picked binary operator as the common case (r) + (s) - t; // Very rare, //an iteration on the case above |
At the moment I am using the parser to measure language usage, so less than 100% correctness can be tolerated. Some of the constructs that cause a syntax error to be generated every few hundred statement/declarations include:
offsetof(struct tag, field_name) // Declarators cannot be //function arguments int f(p, q) int p; // Tries to reduce this as a declaration without handling char q; // it as part of an old style function definition { MACRO(+); // Preprocessing expands to something meaningful |
Some of these can be handled by extensions to the grammar, while others could be handled by an error recovery mechanism that recognized likely macro usage and inserted something appropriate (e.g., a dummy expression in the MACRO(x) case).
Recent Comments