Archive
Functions reduce the need to remember lots of variables
What, if any, are the benefits of adding bureaucracy to a program by organizing a file’s source code into multiple function/method definitions (rather than a single function)?
Having a single copy of a sequence of statements that need to be executed at multiple points in a program reduces implementation effort, and any updates only need to be made once (reducing coding mistakes by removing the need to correctly make duplicate changes). A function/method is the container for this sequence of statements.
Why break code up into separate functions when each is only called once and only likely to ever be called once?
The benefits claimed from splitting code into functions include: making it easier to understand, test, debug, maintain, reuse, and scale development (i.e., multiple developers working on the same program). Our LLM overlords also make these claims, and hallucinate references to published evidence (after three iterations of pointing out the hallucinated references, I gave up asking for evidence; my experience with asking people is that they usually remember once reading something but cannot remember the source).
Regular readers will not be surprised to learn that there is little or no evidence for any of the claimed benefits. I’m not saying that the benefits don’t exist (I think there are some), simply that there have not been any reliable studies attempting to measure the benefits (pointers to such studies welcome).
Having decided to cluster source code into functions, for whatever reason, are there any organizational rules of thumb worth following?
Rules of thumb commonly involve function length (it’s easy to measure) and desirable semantic characteristics of distinct functions (it’s very hard to measure semantic characteristics).
Claims for there being an optimal function length (i.e., lines of code that minimises coding mistakes) turned out to be driven by a mathematical artifact of the axis used when plotting (miniscule) datasets.
Semantic rules of thumb such as: group by purpose, do one thing, and Single-responsibility principle are open to multiple interpretations that often boil down to personal preferences and experience.
One benefit of using functions that is rarely studied is the restricted visibility of local variables defined within them, i.e., only visible within the function body.
When trying to figure out what code does, readers have to keep track of the information contained in all the variables accessed. Having to track more variables not only increases demands on reader memory, it also increases the opportunities for making mistakes.
A study of C source found that within a function, the number of local variables is proportional to the square root of the number of statements (code+data). Assuming the proportionality constant is one, a function containing 100 statements might be expected to define 10 local variables. Splitting this function up into, say, four functions containing 25 statements, each is expected to define 5 local variables. The number of local variables that need to be remembered at the same time, when reading a function definition, has halved, although the total number of local variables that need to be remembered when processing those 100 statements has doubled. Some number of global variables and function parameters need to be added to create an overall total for the number of variables.
The plot below shows the number of locals defined in 36,617 C functions containing a given number of statements, the red line is a fitted regression model having the form:  (code+data):
(code+data):
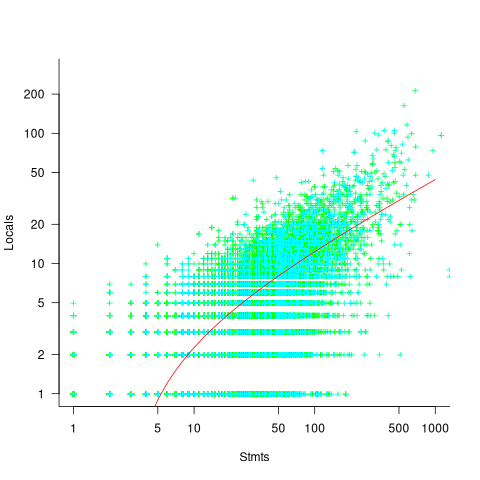
My experience with working with recently self-taught developers, especially very intelligent ones, is that they tend to write monolithic programs, i.e., everything in one function in one file. This minimal bureaucracy approach minimises the friction of a stream of thought development process for adding new code, and changing existing code as the program evolves. Most of these programs are small (i.e., at most a few hundred lines). Assuming that these people continue to code, one of two events teaches them the benefits of function bureaucracy:
- changes to older programs becomes error-prone. This happens because the developer has forgotten details they once knew, e.g., they forget which variables are in use at particular points in the code,
- the size of a program eventually exceeds their ability to remember all of it (very intelligent people can usually remember much larger programs than the rest of us). Coding mistakes occur because they forget which variables are in use at particular points in the code.
Cognitive effort, whatever it might be
Software developers spend a lot of time acquiring knowledge and understanding of the software system they are working on. This mental activity fits within the field of Cognition, which covers all aspects of intellectual functions and processes. Human cognition as it related to software development is covered in chapter 2 of my book Evidence-based software engineering; a reading list.
Cognitive effort (e.g., thinking) is hard work, or at least mental effort feels like hard work. It has become fashionable for those extolling the virtues of some development technique/process to claim that one of its benefits is a reduction in cognitive effort; sometimes the term cognitive load is used, but I suspect this is not a reference to cognitive load theory (which is working memory based).
A study by Arai, with herself as the subject, measured the time taken to mentally multiply two four-digit values (e.g., 2,645 times 5,784). Over 2-weeks, Arai practiced on four days, on each day multiplying over 20 four-digit value pairs. A week later Arai multiplied 40 four-digit value pairs (starting at 1:45pm, finishing at 6:31pm), had dinner between 6:31-7:41 pm, and then, multiplied 20 four-digit value pairs (starting at 7:41, finishing at 10:07). The plot below shows the time taken for each mental multiplication sequence, with fitted regression lines (code+data):
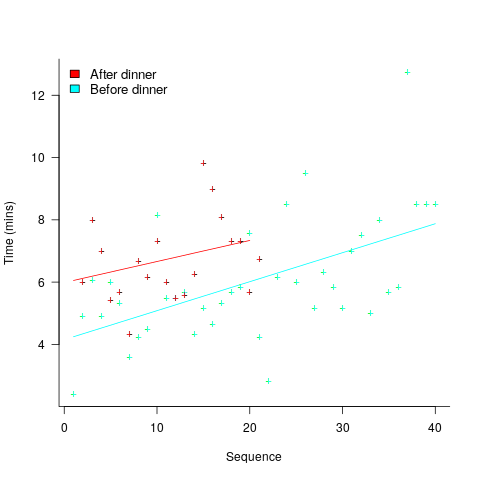
Over the course of the first, 5-hour session, average time taken slowed from four to eight minutes. The slope of the regression fit for the second session is poor, although the fit for the start value (6 minutes) is good.
The average increase in time taken is assumed to be driven by a reduction in mental effort, caused by the mental fatigue experienced during an extended period of continuous mental work.
What do we know about cognitive effort?
TL;DR Many theories and little evidence.
Cognitive psychologists are still at the stage of figuring out what exactly cognitive effort is. For instance, what is going on when we try harder (or decide to give up), and what is being conserved when we conserve our mental resources? The major theories include:
- Cognitive control: Mental processes form a continuum, from those that can be performed automatically with little or no effort, to those requiring concentrated conscious effort. Here, cognitive control is viewed as the force through which cognitive effort is exerted. The idea is that mental effort regulates the engagement of cognitive control in the same way as physical effort regulates the engagement of muscles.
- Metabolic constraints: Mental processes consume energy (glucose is the brain’s primary energy source), and the feeling of mental effort is caused by reduced levels of glucose. The extent to which mental effort is constrained by glucose levels is an ongoing debate.
- Capacity constraints: Working memory has a limited capacity (i.e., the oft quoted 7±2 limit), and tasks that fill this capacity do feel effortful. Cognitive load theory is based around this idea. A capacity limited working memory, as a basis of cognitive effort, suffers from the problem that people become mentally tired in the sense that later tasks feel like they require more effort. A capacity constrained model does not predict this behavior. Neither does a constraints model predict that increasing rewards can result in people exerting more cognitive effort.
How might cognitive effort be measured?
TL;DR It’s all relative or not at all.
To date, experiments have compared relative expenditure of effort between different tasks (some comparing cognitive with physical effort, other purely cognitive). For instance, showing that subjects are willing to perform a task requiring more cognitive effort when the expected reward is higher.
As always with human experiments, people can have very different behavioral characteristics. In particular, people differ in what is known as need for cognition, i.e., their willingness to invest cognitive effort.
While a lot of research has investigated the characteristics of working memory, the only real metric studied has been capacity, e.g., the longest sequence of digits that can be remembered/recalled, or span tasks involving having to remember words while performing simple arithmetic operations.
Experimental research on cognitive effort seems to be picking up, but don’t hold your breadth for reliable answers. Research of human characteristics can start out looking straight forward, but tends to quickly disappear down multiple, inconclusive rabbit holes.
Recent Comments