Archive
Number of calls to/from functions vs function length
Depending on the language the largest unit of code is either a sequence of statements contained in a function/procedure/subroutine or a set of functions/methods contained in a larger unit, e.g., class/module/file. Connections between these largest units (e.g., calls to functions) provide a mechanism for analysing the structure of a program. These connections form a graph, and the structure is known as a call graph.
It is not always possible to build a completely accurate call graph by analysing a program’s source code (i.e., a static call graph) when the code makes use of function pointers. Uncertainty about which functions are called at certain points in the code is a problem for compiler writers wanting to do interprocedural flow analysis for code optimization, and static analysis tools looking for possible coding mistakes.
The following analysis investigates two patterns in the function call graph of C/C++ programs. While calls via function pointers can be very common at runtime, they are uncommon in the source. Function call information was extracted from 98 GitHub projects using CodeQL.
Functions that contain more code are likely to contain more function calls. The plot below shows lines of code against number of function calls for each of the 259,939 functions in whatever version of the Linux kernel is on GitHub today (25 Jan 2026), the red line is a regression fit showing  (the fit systematically deviates for larger functions {yet to find out why}; code and data):
(the fit systematically deviates for larger functions {yet to find out why}; code and data):
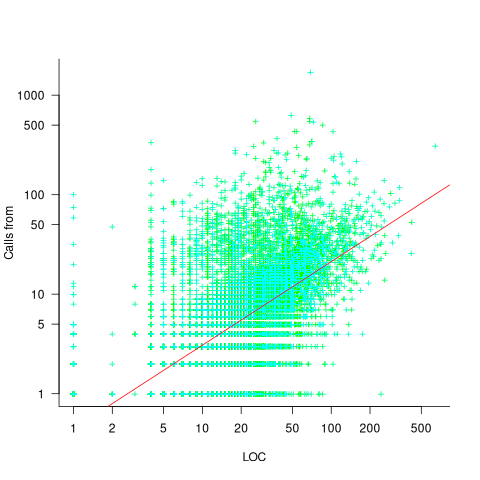
Researchers sometimes make a fuss of the fact that the number of calls per function is a power law, failing to note that this power law is a consequence of the number of lines per function being a power law (with an exponent of 2.8 for C, 2.7 for Java and 2.6 for Pharo). There are many small functions containing a few calls and a few large functions containing many calls.
Are more frequently called functions smaller (perhaps because they perform a simple operation that often needs to be done)? Widely used functionality is often placed in the same source file, and is usually called from functions in other files. The plot below shows the size of functions (in line of code) and the number of calls to them, for the 259,939 functions in the Linux kernel, with lines showing a LOESS fit to the corresponding points (code and data):
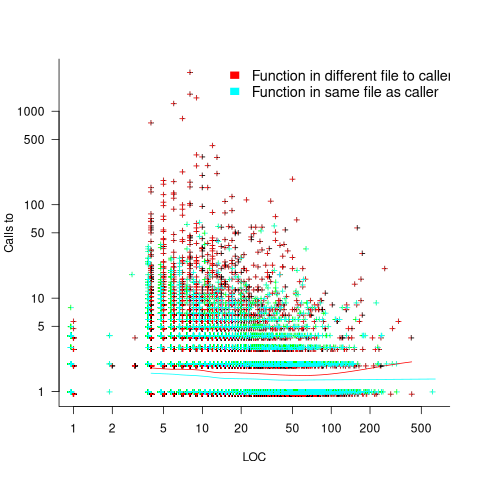
The apparent preponderance of red towards the upper left suggests that frequently called functions are short and contained in files different from the caller. However, the fitted LOESS lines show that the average difference is relatively small. There are many functions of a variety of sizes called once or twice, and few functions called very many times.
The program structure visible in a call graph is cluttered by lots of noise, such as calls to library functions, and the evolution baggage of previous structures. Also, a program may be built from source written in multiple languages (C/C++ is the classic example), and language interface issues can influence organization locally and globally (for instance, in Alibaba’s weex project the function main (in C) essentially just calls serverMain (in C++), which contains lots of code).
I suspect that many call graphs can be mapped to trees (the presence of recursion, though a chain of calls, sometimes comes as a surprise to developers working on a project). Call information needs to be integrated with loops and if-statements to figure out story structures (see section 6.9.1 of my C book). Don’t hold your breath for progress.
I expect that the above patterns are present in other languages. CodeQL supports multiple languages, but CodeQL source targeting one language has to be almost completely reworked to target another language, and it’s not always possible to extract exactly the same information. C/C++ appears have the best support.
Function calls are a component information
Forces driving patterns found in call graphs of human written code
It has been a while since I posted anything about generating source that mimics the characteristics of human written code.
Generating function definitions is the easy bit, although variable selection is fiddly and naming needs to be handled.
The hardest part of mimicking human written code is linking functions together, via calls, in apparently meaningful ways. Within one source file it is probably possible to get away with individual calls to other local functions (most function definitions are called once) and a couple of calls to third party libraries. At the complete program level the code needs to tell a story, and doing this is very hard.
I think function calls can be divided into three categories, all based on the relationship between the developer who writes the code than does the call and the developer(s) who wrote the called function:
- Caller developer is the same person as the callee developer. One person gets to decide how things are done,
- Caller developer works on the same team as the callee developer. Here an interface needs to be negotiated with one or more other people,
- Caller developer is making use of a third-party library. The interface is pre-decided, take it or leave it (the same principle applies to library updates, the caller has to decide whether to stay with the existing version or make the changes needed to upgrade to the new version; Android is the (in)famous example of a frequently changed library that developers are under strong pressure to continually adapt to).
Calls to functions in third-party libraries tend to follow stylized sequences, e.g., open_* occurs before read_*/write_* and close_* appears last. Most of the time a generator could get away not calling functions from third-party libraries, because the number of such calls is often small, but when they occur they had better look correct.
Needing to call a function written by another developer on the team opens up all sorts of possibilities: there is always the option of them modifying the function to make life easier for the new call, but the cost of modifying all the existing call sites (plus any associated call chains) may be too high, perhaps a new global variable can be used to communicate the desired information, or perhaps the proposed usage is a small cog in a large wheel and has to make do (or perhaps they don’t like the person asking for the change and reasons are invented for staying as-is).
Then there is correlation in time and space (this has a big impact on patterns of evolution, at least I think so; models of forest fires, i.e., growth, death, fires of various sizes creating space for new growth, is the obvious parallel):
- The longer a function exists the more likely it is to accumulate callers. A function definition can remain unchanged and yet over time become more and more difficult to change.
- It can be very expensive to make changes to an existing function definition when there are lots of calls to it.
What do measurements of code have to say? Almost nothing; existing studies mostly do weird things like treating a system’s call graph as-if it were a social network (using a currently trendy metaphor is good for getting papers published, even if the mapping is all wrong), plotting power law-like graphs and sprouting portentous nonsense.
What is really needed is measurements of forked systems; comparing systems derived from a common past will tell us how much natural variation exists due to individual choice.
FreeBSD, NetBSD and OpenBSD are the obvious poster children of forked, common heritage, systems written in C; I cannot think of any such systems written in Java or C++.
Recent Comments