Archive
A fault in the C Standard or existing compilers?
Software is not the only entity that can contain faults. The requirements listed in a specification are usually considered to be correct, almost by definition. Of course the users of software implementing a specification may be unhappy with the behavior specified and wish that some alternative behavior occurred. A cut and dried fault occurs when two requirements conflict with each other.
The C Standard can be read as a specification for how C compilers should behave. Despite over 80 man years of effort and the continued scrutiny of developers over 20 years, faults continue to be uncovered. The latest potential fault (it is possible that the fault actually occurs in many existing compilers rather than the C Standard) was brought to my attention by Al Viro, one of the Sparse developers.
The issue involved the following code (which I believe the standard considers to be strictly conforming, but all the compilers I have tried disagree):
int (*f(int x))[sizeof x]; // A prototype declaration int (*g(int y))[sizeof y] // A function definition { return 0; } |
These function declarations are unusual in that their return type is a pointer to an array of integers, a type rarely encountered in this context (the original question involved a return type of pointer to function returning … and was more complicated).
The specific issue was the scope of the parameter (i.e., x and y), is the declaration still in scope at the point that the second occurrence of the identifier is encountered?
As a principle I think that the behavior, whatever it turns out to be, should be the same in both cases (neither the C standard or its rationale state such a principle).
Taking the function prototype case first:
The scope of the parameter x “… terminates at the end of the function declarator.” (sentence 409).
and does function prototype scope include the return type (the syntax calls the particular construct a declarator and there are at least two of them, one nested inside the other, in a function prototype declaration)?
Sentence 1592 says Yes, but sentence 279 and 1845 say No.
None of these references are normative references (standardize for definitive).
Moving on to the function definition case:
Where does the scope of the parameter x begin (sentence 418)?
“… scope that begins just after the completion of its declarator.”
and where does the scope end (sentence 408)?
“… which terminates at the end of the associated block.”
and what happens between the beginning and ending of the scope (sentence 412)?
“Within the inner scope, the identifier designates the entity declared in the inner scope;”
This looks very straight forward, there are no ‘gaps’ in the scope of the parameter definition appearing in a function definition. Consistency with the corresponding function prototype case requires that function declarator be interpreted to include the return type.
There is a related discussion involving a previous Defect Report 345 submitted a while ago.
The problem is that many existing compilers do not treat parameter scope in this way. They operate as-if there was a ‘gap’ in the parameter scope of function definition (probably because the code implementing this functionality is shared with that implementing function prototypes, which have been interpreted to not include the return type).
What happens next? Probably lots of discussion on the C Standard email reflector. Possible outcomes include somebody finding wording that requires a ‘gap’ in the scope of parameters in function definitions, it agreed that such a gap ought to be specified by the standard (because this is how existing code behaves because this is how compilers operate), or that the standard is correct as is and any compiler that behaves differently needs to be fixed.
The probability of encountering a given variable
If I am reading through the body of a function, what is the probability of a particular variable being the next one I encounter? A good approximation can be calculated as follows: Count the number of occurrences of all variables in the function definition up to the current point and work out the percentage occurrence for each of them, the probability of a particular variable being seen next is approximately equal to its previously seen percentage. The following graph is the evidence I give for this approximation.
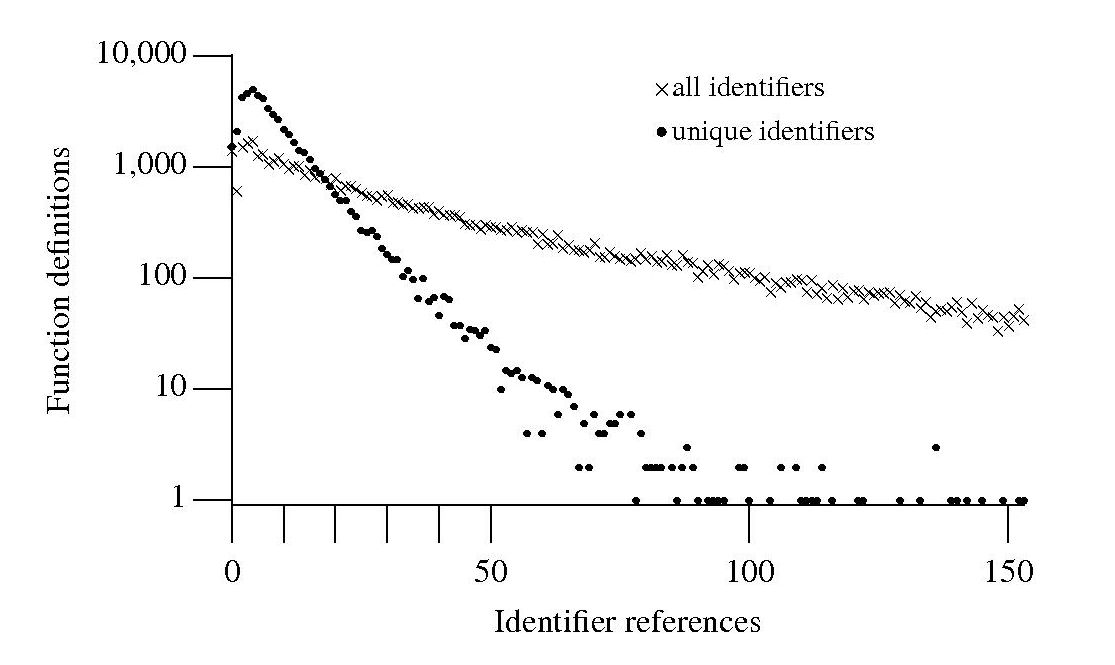
The graph shows a count of the number of C function definitions containing identifiers that are referenced a given number of times, e.g., if the identifier x is referenced five times in one function definition and ten times in another the function definition counts for five and ten are both incremented by one. That one axis is logarithmic and the bullets and crosses form almost straight lines hints that a Zipf-like distribution is involved.
There are many processes that will generate a Zipf distribution, but the one that interests me here is the process where the probability of the next occurrence of an event occurring is proportional to the probability of it having previously occurred (this includes some probability of a new event occurring; follow the link to Simon’s 1955 paper).
One can think of the value (i.e., information) held in a variable as having a given importance and it is to be expected that more important information is more likely to be operated on than less important information. This model appeals to me. Another process that will generate this distribution is that of Monkeys typing away on keyboards and while I think source code contains lots of random elements I don’t think it is that random.
The important concept here is operated on. In x := x + 1; variable x is incremented and the language used requires (or allowed) that the identifier x occur twice. In C this operation would only require one occurrence of x when expressed using the common idiom x++;. The number of occurrences of a variable needed to perform an operation on it, in a given languages, will influence the shape of the graph based on an occurrence count.
One graph does not provide conclusive evidence, but other measurements also produce straightish lines. The fact that the first few entries do not form part of an upward trend is not a problem, these variables are only accessed a few times and so might be expected to have a large deviation.
More sophisticated measurements are needed to count operations on a variable, as opposed to occurrences of it. For instance, few languages (any?) contain an indirection assignment operator (e.g., writing x ->= next; instead of x = x -> next;) and this would need to be adjusted for in a more sophisticated counting algorithm. It will also be necessary to separate out the effects of global variables, function calls and the multiple components involved in a member selection, etc.
Update: A more detailed analysis is now available.
Semantic pattern matching (Coccinelle)
I have just discovered Coccinelle a tool that claims to fill a remarkable narrow niche (providing semantic patch functionality; I have no idea how the name is pronounced) but appears to have a lot of other uses. The functionality required of a semantic patch is the ability to write source code patterns and a set of transformation rules that convert the input source into the desired output. What is so interesting about Coccinelle is its pattern matching ability and the ability to output what appears to be unpreprocessed source (it has to be told the usual compile time stuff about include directory paths and macros defined via the command line; it would be unfair of me to complain that it needs to build a symbol table).
Creating a pattern requires defining identifiers to have various properties (eg, an expression in the following example) followed by various snippets of code that specify the pattern to match (in the following <… …> represents a bracketed (in the C compound statement sense) don’t care sequence of code and the lines starting with +/- have the usual patch meaning (ie, add/delete line)). The tool builds an abstract syntax tree so urb is treated as a complete expression that needs to be mapped over to the added line).
@@ expression lock, flags; expression urb; @@ spin_lock_irqsave(lock, flags); <... - usb_submit_urb(urb) + usb_submit_urb(urb, GFP_ATOMIC) ...> spin_unlock_irqrestore(lock, flags); |
Coccinelle comes with a bunch of predefined equivalence relations (they are called isomophisms) so that constructs such as if (x), if (x != NULL) and if (NULL != x) are known to be equivalent, which reduces the combinatorial explosion that often occurs when writing patterns that can handle real-world code.
It is written in OCaml (I guess there had to be some fly in the ointment) and so presumably borrows a lot from CIL, perhaps in this case a version number of 0.1.3 is not as bad as it might sound.
My main interest is in counting occurrences of various kinds of patterns in source code. A short-term hack is to map the sought-for pattern to some unique character sequence and pipe the output through grep and wc. There does not seem to be any option to output a count of the matched patterns … yet 🙂
What I changed my mind about in 2008
A few years ago The Edge asked people to write about what important issue(s) they had recently changed their mind about. This is an interesting question and something people ought to ask themselves every now and again. So what did I change my mind about in 2008?
1. Formal verification of nontrivial C programs is a very long way off. A whole host of interesting projects (e.g., Caduceus, Comcert and Frame-C) going on in France has finally convinced me that things are a lot closer than I once thought. This does not mean that I think developers/managers will be willing to use them, only that they exist.
2. Automatically extracting useful information from source code identifier names is still a long way off. Yes, I am a great believer in the significance of information contained in identifier names. Perhaps because I have studied the issues in detail I know too much about the problems and have been put off attacking them. A number of researchers (e.g., Emily Hill, David Shepherd, Adrian Marcus, Lin Tan and a previously blogged about project) have simply gone ahead and managed to extract (with varying amount of human intervention) surprising amounts of useful from identifier names.
3. Theoretical analysis of non-trivial floating-point oriented programs is still a long way off. Daumas and Lester used the Doobs-Kolmogorov Inequality (I had to look it up) to deduce the probability that the rounding error in some number of floating-point operations, within a program, will exceed some bound. They also integrated the ideas into NASA’s PVS system.
You can probably spot the pattern here, I thought something would not happen for years and somebody went off and did it (or at least made an impressive first step along the road). Perhaps 2008 was not a good year for really major changes of mind, or perhaps an earlier in the year change of mind has so ingrained itself in my mind that I can no longer recall thinking otherwise.
Parsing without a symbol table
When processing C/C++ source for the first time through a compiler or static analysis tool there are invariably errors caused by missing header files (often because the search path has not been set) or incorrectly defined, or not defined, macro names. One solution to this configuration problem is to be able to process source without handling preprocessing directives (e.g., skipping them, such as not reading the contents of header files or working out which arm of a conditional directive is applicable). Developers can do it, why not machines?
A few years ago GLR support was added to Bison, enabling it to process ambiguous grammars, and I decided to create a C parser that simply skipped all preprocessing directives. I knew that at least one reasonably common usage would generate a syntax error:
func_call(a, #if SOME_FLAG b_1); #else b_2); #endif |
c);
and wanted to minimize its consequences (i.e., cascading syntax errors to the end of the file). The solution chosen was to parse the source a single statement or declaration at a time, so any syntax error would be localized to a single statement or declaration.
Systems for parsing ambiguous grammars work on the basis that while the input may be locally ambiguous, once enough tokens have been seen the number of possible parses will be reduced to one. In C (and even more so in C++) there are some situations where it is impossible to resolve which of several possible parses apply without declaration information on one or more of the identifiers involved (a traditional parser would maintain a symbol table where this information could be obtained when needed). For instance, x * y; could be a declaration of the identifier y to have type x or an expression statement that multiplies x and y. My parser did not have a symbol table and even if it did the lack of header file processing meant that its contents would only contain a partial set of the declared identifiers. The ambiguity resolution strategy I adopted was to pick the most likely case, which in the example is the declaration parse.
Other constructs where the common case (chosen by me and I have yet to get around to actually verifying via measurement) was used to resolve an ambiguity deadlock included:
f(p); // Very common, // confidently picked function call as the common case (m)*p; // Not rare, // confidently picked multiplication as the common case (s) - t; // Quiet rare, // picked binary operator as the common case (r) + (s) - t; // Very rare, //an iteration on the case above |
At the moment I am using the parser to measure language usage, so less than 100% correctness can be tolerated. Some of the constructs that cause a syntax error to be generated every few hundred statement/declarations include:
offsetof(struct tag, field_name) // Declarators cannot be //function arguments int f(p, q) int p; // Tries to reduce this as a declaration without handling char q; // it as part of an old style function definition { MACRO(+); // Preprocessing expands to something meaningful |
Some of these can be handled by extensions to the grammar, while others could be handled by an error recovery mechanism that recognized likely macro usage and inserted something appropriate (e.g., a dummy expression in the MACRO(x) case).
C++ goes for too big to fail
If you believe the Whorfian hypothesis that language effects thought, even in one of its weaker forms, then major changes to a programming language will affect the shape of the code its users write.
I was at the first International C++ Standard meeting in London during 1991 and coming from a C Standard background I could not believe the number of new constructs being invented (the C committee had a stated principle that a construct be supported by at least one implementation before it be considered for inclusion in the standard; ok, this was not always followed to the letter). The C++ committee members continued to design away, putting in a huge amount of effort, and the document was ratified before the end of the century.
The standard is currently undergoing a major revision, and the amount of language design going on puts the original committee to shame. With over 1,300 pages in the latest draft nobodies favorite construct is omitted. The UK C++ panel has over 10 people actively working on producing comments and may produce over 1,000 on the latest draft.
With so many people committed to the approach being taken in the development of the revised C++ Standard its current direction is very unlikely to change. The fact that most ‘real world’ developers only understand a fraction of what is contained in the existing standard has not stopped it being very widely used and generally considered as a ‘success’. What is the big deal over a doubling of the number of pages in a language definition, the majority of developers will continue to use the small subset that they each individually have used for years.
The large number of syntactic ambiguities make it is very difficult to parse C++ (semantic information is required to resolve the ambiguities and the code to do this is an at least an order of magnitude bigger than the lexer+parser). This difficulty is why there are so few source code analysis tools available for C++, compared to C and Java, which are much much easier to parse. The difficulty of producing tools means that researchers rarely analyse C++ code, and only reasonably well funded efforts are capably of producing worthwhile static analysis tools.
Like many of the active committee members, I have mixed feelings about this feature bloat. Yes, it is bad, but it will keep us all actively employed on interesting projects for many years to come. As the current financial crisis has shown, one of the advantages of being big and not understood is that you might get to being too big to fail.
Recent Comments