Archive
Christmas books for 2025
My rate of book reading has remained steady this year, however, my ability to buy really interesting books has declined. Consequently, the list of honourable mentions is longer than the main list. Hopefully my luck/skill will improve next year. As is usually the case, most book were not published in this year.
Liberal Fascism: The secret history of the Left from Mussolini to the Politics of Meaning by Jonah Goldberg is reviewed in a separate post.
Oxygen: The molecule that made the world by Nick Lane, a professor of evolutionary biochemistry, published in 2016. The book discusses changes in the percentage of oxygen in the Earth’s atmosphere over billions of years and the factors that are thought to have driven these changes. The content is at the technical end of popular science writing. The author is a strong proponent that life (which over a billion or so years produced most of the oxygen in the atmosphere) originated in hydrothermal vents, not via lightening storms in the Earth’s primordial atmosphere (as suggested by the Miller–Urey experiment). The Wikipedia article on the origins of life contains a lot more words on the Miller–Urey experiment.
“By the Numbers: Numeracy, Religion and the Quantitative Transformation of Early Modern England” by Jessica Marie Otis, a professor of history, published in 2024. Here, early modern England starts around 1543 with the publication of an arithmetic textbook, The Ground of Artes, that was republished 45 times up until 1700. As the title suggests, the book discusses the factors driving the spread of numeracy into the general population, e.g., the need for traders and organizations to keep accounts, and the people to keep track of time. For the general reader, the book is rather short at 160 readable pages. Historians get to enjoy the 51 pages of notes and 37 pages of bibliography.
For insightful long, discursive book reviews that are often more interesting than the books themselves (based on those I have purchased), see: Mr. and Mrs. Psmith’s Bookshelf. This year, Astral Codex ran a Non-Book Review Contest.
The blog Worshipping the Future by Helen Dale and Lorenzo Warby continues to be an excellent read. It is “… a series of essays dissecting the social mechanisms that have led to the strange and disorienting times in which we live.” The series is a well written analysis that attempts to “… understand mechanisms of how and the why, …” of Woke.
As an aside, one of the few pop cds I bought this year turned out to be excellent: “PARANOÏA, ANGELS, TRUE LOVE” by Christine and the Queens.
Honourable mentions
The Knowledge: How to Rebuild Our World from Scratch by Lewis Dartnell, an astrobiologist. Assuming you are among the approximately 5% of people still alive after civilizations collapses (the book does not talk about this, but without industrial scale production of food, most people will starve to death), how can useful modern day items (i.e., available in the last hundred years or so) be created? Items include ammonia-based fertilizer, electricity, radio receiver and simple drugs. The processes sound a lot easier to do than they are likely to be in practice (manufacturing processes invariably make use of a lot of tacit knowledge), but then it is a popular book covering a lot of ground. It’s really a list of items to consider, along with some starting ideas.
“Goodbye, Eastern Europe: An Intimate History of a Divided Land” by Jacob Mikanowski, a historian and science writer, published in 2023. A history of Eastern Europe from the first century to today, covering the countries encircled by Germany, the Baltic Sea, Russia, and the Black Sea/Mediterranean. The story is essentially one of migrations, and mass slaughters, with the accompanying creation and destruction of cultures. Harrowing in places. It’s no wonder that the people from that part of the world cling to whatever roots they have.
“Reframe Your Brain: The User Interface for Happiness and Success” by Scott Adams of Dilbert fame, published in 2023. To quote Wikipedia: “Cognitive reframing is a psychological technique that consists of identifying and then changing the way situations, experiences, events, ideas and emotions are viewed.” This book contains around 200 reframes of every day situations/events/emotions, with accompanying discussion. Some struck me as a bit outlandish, but sometimes outlandish has the desired effect.
Details on your best books of the year very welcome in the comments.
The inconvenient history of Liberal Fascism
Based purely on its title, Liberal Fascism: The secret history of the Left from Mussolini to the Politics of Meaning by Jonah Goldberg, published in 2007, is not a book that I would usually consider buying.
The book traces the promotion and application of fascistic ideas by activists and politicians, from their creation by Mussolini in the 1920s to the start of this century. After these ideas first gained political prominence in the 1920s/30s as Fascism, they and the term Fascism became political opposites, i.e., one was adopted by the left and the other labelled as right-wing by the left.
The book starts by showing the extreme divergence of opinions on the definition of Fascism. The author’s solution to deciding whether policies/proposals are Fascist to compare their primary objectives and methods against those present (during the 1920s and early 1930s) in the policies originally espoused by Benito Mussolini (president of Italy from 1922 to 1943), Woodrow Wilson (the 28th US president between 1913-1921), and Adolf Hitler (Chancellor of Germany 1933-1945).
Whatever their personal opinions and later differences, in the early years of Fascism Mussolini, Wilson and Hitler made glowing public statements about each other’s views, policies and achievements. I had previously read about this love-in, and the book discusses the background along with some citations to the original sources.
Like many, I had bought into the Mussolini was a buffoon narrative. In fact, he was extremely well-read, translated French and German socialist and philosophical literature, and was considered to be the smartest of the three (but an inept wartime leader). He was acknowledged as the father of Fascism. The Italian fascists did not claim that Nazism was an offshoot of Italian fascism, and went to great lengths to distance themselves from Nazi anti-Semitism.
At the start of 1920 Hitler joined the National Socialist party, membership number 555. There is a great description of Hitler: “… this antisocial, autodidactic misanthrope and the consummate party man. He has all the gifts a cultist revolutionary party needed: oratory, propaganda, an eye for intrigue, and an unerring instinct for populist demagoguery.”
Woodrow Wilson believed that the country would be better off with the state (i.e., the government) dictating how things should be, and was willing for the government to silence dissent. The author describes the 1917 Espionage Act and the Sedition Act as worse than McCarthyism. As a casual reader, I’m not going to check the cited sources to decide whether the author is correct and that the Wikipedia articles are whitewashing history (he does not claim this), or that the author is overselling his case.
Readers might have wondered why a political party whose name contained the word ‘socialist’ came to be labelled as right-wing. The National Socialist party that Hitler joined was a left-wing party, i.e., it had the usual set of left-wing policies and appealed to the left’s social base.
The big difference, as perceived by those involved, between National Socialism and Communism, as I understand it, is that communists seek international socialism and define all nationalist movements, socialist or not, as right-wing. Stalin ordered that the term ‘socialism’ should not be used when describing any non-communist party.
Woodrow Wilson died in 1924, and Franklin D. Roosevelt (FDR) became the 32nd US president, between 1933 and 1945. The great depression happens and there is a second world war, and the government becomes even more involved in the lives of its citizens, i.e., Mussolini Fascist policies are enacted, known as the New Deal.
History repeats itself in the 1960s, i.e., Mussolini Fascist policies implemented, but called something else. Then we arrive in the 1990s and, yes, yet again Mussolini Fascist policies being promoted (and sometimes implemented) under another name.
I found the book readable and enjoyed the historical sketches. It was an interesting delve into the extent to which history is rewritten to remove inconvenient truths associated with ideas promoted by political movements.
Christmas books for 2024
My rate of book reading has picked up significantly this year. The following are the really interesting books I read, as is usually the case, most were not published in this year.
I have enjoyed Grayson Perry’s TV programs on the art world, so I bought his book “Playing to the Gallery: Helping Contemporary Art in its Struggle to Be Understood“. It’s a fun, mischievous look at the art world by somebody working as a traditional artist, in the sense of creating work that they believe means/says something, rather than works that are only considered art because they are displayed in an art gallery.
“The Computer from Pascal to von Neumann” by H. H. Goldstine. This history of computing from the mid-1600s (the time of Blaise Pascal) to the mid-1900s (von Neumann died in 1957) told by a mathematician who was first involved in calculating artillery firing tables during World War II, and then worked with early computers and von Neumann. This book is full of insights that only a technical person could provide and is a joy to read.
I saw a poster advertising a guided tour of the trees in my local park, organized by Trees for Cities. It was a very interesting lunchtime; I had not appreciated how many different trees were growing there, including three different kinds of Oak tree. Trees for Cities run events all over the UK, and abroad. Of course, I had to buy some books to improve my tree recognition skills. I found “Collins tree guide” by O. Johnson and D. More to be the most useful and full of information. Various organizations have created maps of trees in cities around the world. The London Tree Map shows the location and species information for over 880,000 of trees growing on streets (not parks), New York also has a map. For a general analysis of patterns of tree growth, see “How to Read a Tree” by T. Gooley.
“Medieval Horizons: Why the Middle Ages Matter” by I. Mortimer. This book takes the reader through the social, cultural and economic changes that happened in England during the Middle Ages, which the author specifies as the period 1000 to 1600. I knew that many people were surfs, but did not know that slaves accounted for around 10% of the population, dropping to zero percent during this period. Changes, at least for the well-off, included moving from living in longhouses to living in what we would call a house, art works moved from two-dimensional representations to life-like images (e.g., renaissance quality), printing enables an explosion of books, non-poor people travelled more, ate better, and individualism started to take-off.
Statistical Consequences of Fat Tails: Real World Preasymptotics, Epistemology, and Applications by N. N. Taleb is a mathematically dense book (while the pdf is in color, I was disappointed that the printed version is black/white; this is the one I read while travelling). This book tells you a lot more than you need to know about the consequences of fat tail distributions. Why might you be interested in the problems of fat tails? Taleb starts by showing how little noise it takes for the comforting assumptions implied by the Normal/Gaussian distribution to fly out the window. The primary comforting assumptions are that the mean and variance of a small sample are representative of the larger population. A world of fat tail distributions is one where the unexpected is to be expected, where a single event can wipe out an organization or industry (banks are said to have lost more in the 2008 financial crisis than they had made in the previous many decades). This book is hard going, and I kept at it to get a feel for the answers to some of the objections to the bad news conveyed. There are a couple of places where I should have been more circumspect in my Evidence-based software engineering book.
I have previously reviewed General Relativity: The Theoretical Minimum by Susskind and Cabannes.
“Embracing Defeat: Japan in the Wake of World War II” by John W. Dower describes in harrowing detail the dire circumstances of the population of Japan immediately after World War II and what they had to endure to survive.
For more detailed book reviews, see: Mr. and Mrs. Psmith’s Bookshelf with some excellent and insightful long book reviews, and the annual Astral Codex Ten book review contest usually has a few excellent reviews/books.
For those of you who think that civilization is about to collapse, or at least like talking about the possibility, a reading list. At the practical level, I think sword fighting and archery skills are more likely to be useful in the longer term.
Learning General relativity at a rudimentary mathematical level
For the longest time, I have wanted to have an understanding of Einstein’s theory of General relativity at a rudimentary mathematical level. Because General relativity has never been a mainstream topic in undergraduate physics, there are almost no books at this level. Also, the mathematics of General relativity is based on tensor calculus, which until recently was rarely used in engineering and non-relativistic physics; market size explains the lack of non-specialist books on the subject.
The Theoretical Minimum is a book series that aims to teach everything required to gain a basic understanding of various areas of modern physics. The primary author of the books is Leonard Susskind.
At the start of this year, “General Relativity: The Theoretical Minimum” by Susskind and Cabannes was published as a paperback (i.e., convenient for reading on the London Underground), and over the last two months I have been slowly working my way through it.
At the start of this week, I discovered Eddie Boyes’ YouTube series on General relativity.
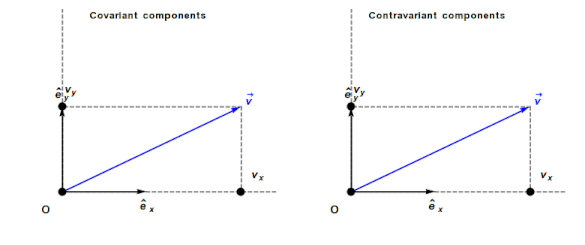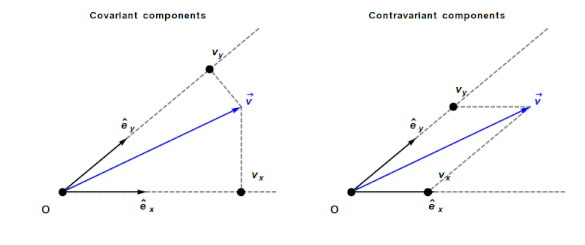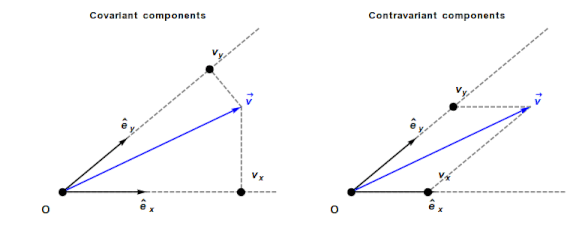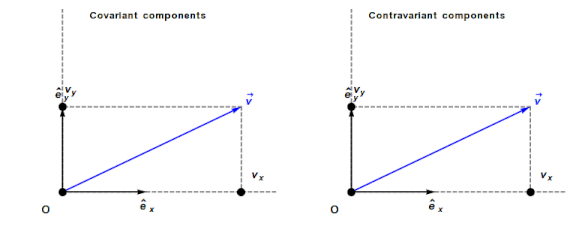
An understanding of General relativity requires an understanding of Tensor calculus, which in turn requires understanding the contravariant and covariant components of a vector. In the Cartesian coordinates system, which pervades undergraduate physics, the axes are at right angles and the measurement units are constant. The covariant component of a vector is the same as the contravariant component.
Contravariant/covariant vectors are different when the axes are not at right angles, as the plot below (from Wikipedia), shows. Choosing one component of the blue vector, the  component of its contravariant vector is measured by drawing a line parallel to the y-axis (on right), while the component of its covariant vector is found by drawing a line perpendicular to the x-axis (on left). The plot below shows how the measurements of each component vary as the angle between the x/y axes varies:
component of its contravariant vector is measured by drawing a line parallel to the y-axis (on right), while the component of its covariant vector is found by drawing a line perpendicular to the x-axis (on left). The plot below shows how the measurements of each component vary as the angle between the x/y axes varies:
Susskind’s definition of covariant vectors is a differential equation, which might be enough for some people, but not me. Boyes gives a very clear description (he does labour points, and I watched at 1.75 speed).
There are other places where I found Boyes’ explanation to be clearer, and a few where I preferred Susskind. I would recommend both.
What complicates the use of Tensor calculus is the multiplicity of terms in an equation. In 3-dimensional Cartesian coordinates there are three variables x/y/z, while in 3-dimensional Tensor calculus there are nine variables (the coordinate system can produce an interaction between any axis and another one). The equation for the proper acceleration of an object, written using the Einstein summation convention (there is a summation over the repeated indexes,  ,
,  ,
,  ) is:
) is:  . In three dimensions, there would be three equations (i.e.,
. In three dimensions, there would be three equations (i.e.,  ), each with nine terms on the right, for
), each with nine terms on the right, for  ,
,  ;
;  is the Christoffel symbol which calculates the unit distance for a location in space (in Cartesian coordinates this simplifies down to what we all learned in school); the superscripts denote contravariant components, and the subscripts denote covariant components:
is the Christoffel symbol which calculates the unit distance for a location in space (in Cartesian coordinates this simplifies down to what we all learned in school); the superscripts denote contravariant components, and the subscripts denote covariant components:
How did Einstein derive his field equation,  , of General relativity?
, of General relativity?
I had known of the equivalence principle, that the force experienced by an accelerating observer (e.g., travelling in an elevator) is indistinguishable from the force of gravity, but had not appreciated how this principle played an integral part in the derivation of the equations for the force experienced in a gravitational field.
The derivation is based on asking about the trajectory of a rocket accelerating at a constant rate in a flat space-time (allowing Cartesian coordinates to be used). If a stationary observer on the ground tracks the rocket from when it starts with zero velocity and then constantly accelerates in a straight line for a very long time, how will the velocity and distance of the rocket (from the observer) change over time? From the ground-based observer’s perspective, the rocket’s velocity will get closer and closer to the speed of light; Special relativity prevents it exceeding the speed of light. The distance travelled by the rocket over time, as tracked by the ground-based observer, will be seen to be fitted by a hyperbolic equation. This analysis is used to justify the use of hyperbolic geometric as a coordinate system for dealing with gravity.
A hyperbolic metric space was not enough for Einstein to derive his equations. He also assumed conservation of various quantities, and appears to have included some idealism about how the Universe ought to operate.
Special relativity predicts some very surprising behaviors, such as of time dilation. What very surprising behaviours does General relativity predict?
The bending of light by gravity is often cited as an example of a prediction by General relativity. However, bending is predicted my Newtonian mechanics, but the amount is half that predicted by General relativity.
While Black holes get a lot of public attention, and are discussion time by Susskind and Boyes, General relativity is not needed to make the prediction that that gravitational attraction of a sufficiently massive body will be greater than the speed of light.
General relativity deals with accelerating frames of reference (gravity or rocket ships). Both Susskind and Boyes discuss some version of Bell’s spaceship paradox, which is actually a consequence of Special relativity; I think that Boyes YouTube video is the easiest to follow.
Apart from ticking another item on my to-do list, I now appreciate some of the subtle points people make about General relativity. I’m sure that this knowledge will increase the likelihood of me getting in over my head in some future discussion on relativity.
A distillation of Robert Glass’s lifetime experience
Robert Glass is a software engineering developer, manager, researcher and author who, until six months ago, I had vaguely heard of; somehow I had missed reading any of his 25 books. After seeing citations to some of Glass’s books, I bought half-a-dozen or so, second hand. They are well written, and twenty-five years ago I would have found them very interesting; now I simply agree with the points made.
“software creativity 2.0” is Glass’s penultimate book, published in 2006, and the one that caught my attention. I would recommend his other books to anybody who is new to software engineering, or experienced people looking for an encapsulation in print of what they encounter at work.
Glass was 74 when this book was published, having started working in computing in 1954. He was there and seems to have met many of the major names in software engineering, working with some of them.
The book is a clear-eyed summary of what Glass has learned from being involved with software engineering, and watching method/tool fashions come and go. My favourite section draws parallels between software development cultures and the culture of Rome vs. Greek vs. Barbarian:
Models Roman Greek Barbarians Organization Organize people Organize things Barely Focus Manages projects Writes programs Leap to coding Motivation Group goals Problem to be solved Heroics Working style Organizations Small groups Solo Politics Imperial Democratic Anarchist Tool use People are tools Things are tools Avoid tools Status Function-ocracy Meritocracy Fear-ocracy Activities Plan things Do things Break things Emphasize Form Substance Line of code |
The contents are essentially a collection of short essays, organized under the 19 chapter headings below, which in turn are grouped into four parts. The first nine chapters (part I, and 60% of pages) contain the experience based material, with the subsequent parts/pages having a creativity theme. A thread running through the discussion is idealism/practice:
Discipline vs. Flexibility
Formal methods versus Heuristics
Optimizing versus Satisficing
Quantitative versus Qualitative Reasoning
Process versus Product
Intellect vs. Clerical Tasks
Theory vs. Practice
Industry vs. Academe
Fun versus Getting Serious
Creativity in the Software Organization
Creativity in Software Technology
Creative Milestones in Software History
Organizational Creativity
The Creative Person
Computer Support for Creativity
Creativity Paradoxes#'twas Always Thus
A Synergistic Conclusion
Other Conclusions |
This book deserves to be widely read. I found it best to read a single section per sitting.
Christmas books for 2023
This year’s Christmas book list, based on what I read this year, and for the first time including a blog series that I’m sure will eventually appear in book form.
“To Explain the World: The discovery of modern science” by Steven Weinberg, 2015. Unless you know that Steven Weinberg won a physics Nobel prize, this looks like just another history of science book (the preface tells us that he also taught a history of science course for over a decade). This book is written by a scientist who appears to have read the original material (I’m assuming in translation), who puts the discoveries and the scientists involved at the center of the discussion; this is not the usual historian who sprinkles in a bit about science, while discussing the cast of period characters. For instance, I had never understood why the work of Galileo was considered to be so important (almost as a footnote, historians list a few discoveries of his). Weinberg devotes pages to discussing Galileo’s many discoveries (his mathematics was a big behind the times, continuing to use a geometric approach, rather than the newer algebraic techniques), and I now have a good appreciation of why Galileo is rated so highly by scientists down the ages.
Chapter 2 of “When Old Technologies Were New: Thinking about electric communication in the late nineteenth century” by Carolyn Marvin, 1988. The book is worth buying just for chapter 2, which contains many hilarious examples of how the newly introduced telephone threw a spanner in to the workings of the social etiquette of the class of person who could afford to install one. Suitors could talk to daughters without other family members being present, public phone booths allowed any class of person to be connected directly to the man of the house, and when phone companies started publishing publicly available directories containing subscriber name/address/number, WELL!?! In the US there were 1 million telephones installed by 1899, and subscribers were sometimes able to listen to live musical concerts and sports events (commercial radio broadcasting did not start until the 1920s).
“The Grand Strategy of the Roman Empire: From the first century A.D. to the third” by Edward Luttwak, 1976; h/t Mr. and Mrs. Psmith’s review. I cannot improve or add to John Psmith’s review. The book contains more details; the review captures the essence. On a related note, for the hard core data scientists out there: Early Imperial Roman army campaigning: observations on marching metrics, energy expenditure and the building of marching camps.
“Innovation and Market Structure: Lessons from the computer and semiconductor industries” by Nancy S. Dorfman, 1987. An economic perspective on the business of making and selling computers, from the mid-1940s to the mid-1980s. Lots of insights, (some) data, and specific examples (for the most part, the historians of computing are, well, historians who can craft a good narrative, but the insights are often lacking). The references led me to: Mancke, Fisher, and McKie, who condensed the 100K+ pages of trial transcript from the 1969–1982 IBM antitrust trial down to 1,500+ pages of Historical narrative.
Worshipping the Future by Helen Dale and Lorenzo Warby. Is “… a series of essays dissecting the social mechanisms that have led to the strange and disorienting times in which we live.” The series is a well written analysis that attempts to “… understand mechanisms of how and the why, …” of Woke.
Honourable mentions
“The Big Con: The story of the confidence man and the confidence trick” by David W. Maurer (source material for the film The Sting).
“Cubed: A secret history of the workplace” by Nikil Saval.
Rereading The Mythical Man-Month
The book The Mythical Man-Month by Fred Brooks, first published in 1975, continues to be widely referenced, my 1995 edition cites over 250K copies in print. In the past I have found it to be a pleasant, relatively content free, read.
Having spent some time analyzing computing data from the 1960s, I thought it would be interesting to reread Brooks in the light of what I had recently learned. I cannot remember when I last read the book, and only keep a copy to be able to check when others cite it as a source.
Each of the 15 chapters, in the 1975 edition, takes the form of a short five/six page management briefing on some project related topic; chapters start with a picture of some work or art on one page, and a short quote from a famous source occupies the opposite page. The 20th anniversary edition adds four chapters, two of which ‘refire’ Brooks’ 1986 paper introducing the term No Silver Bullet (that no single technlogy will produce an order of magnitude improvement in productivity).
Rereading, I found the 1975 contents to be sufficiently non-specific that my newly acquired knowledge did not change anything. It was a pleasant read, various ideas and some data points are presented, the work of others is covered and cited, a few points are briefly summarised and the chapter ends. The added chapters have a different character than the earlier ones, being more detailed in their discussion and more specific in suggesting outcomes. The ‘No Silver Bullet’ material dismisses some of the various claimed discoveries of a silver bullet.
Why did the book sell so well?
The material is an easy read, and given that no solutions are heavily pushed, there is little to disagree with.
Being involved on a project for the first time can be a confusing experience, and even more experienced people get lost. Brooks can provide solace through his calm presentation of project behaviors as stuff that happens.
What project experience did Brooks have?
Brooks’ PhD thesis The Analytic Design of Automatic Data Processing Systems was completed in 1956, and, aged 25, he joined IBM that year. He was project manager for System/360 from its inception in late 1961 to its launch in April 1964. He managed the development of the operating system OS/360 from February 1964, for a year, before leaving to found the computer science department at the University of North Carolina at Chapel Hill, where he remained.
So Brooks gained a few years of hands-on experience at the start of his career and spent the rest of his life talking about it. A not uncommon career path.
Managing the development of an O/S intended to control a machine containing 16K of memory (i.e., IBM’s System/360 model 30) might not seem like a big deal. Teams of half-a-dozen good people had implemented projects like this since the 1950s. However, large companies create large teams, operating over multiple sites, with every changing requirements and interfaces, changing hardware, all with added input from marketing (IBM was/is a sales-driven organization). I suspect that the actual coding effort was a rounding error, compared to the time spent in meetings and on telephone calls.
Brooks looked after the management, and Gene Amdahl looked after the technical stuff (for lots of details see IBM’s 360 and early 370 systems by Pugh, Johnson, and Palmer).
Brooks was obviously a very capable manager. Did the O/360 project burn him out?
An evidence-based software engineering book from 2002
I recently discovered the book A Handbook of Software and Systems Engineering: Empirical Observations, Laws and Theories by Albert Endres and Dieter Rombach, completed in 2002.
The preface says: “This book is about the empirical aspects of computing. … we intend to look for rules and laws, and their underlying theories.” While this sounds a lot like my Evidence-based Software Engineering book, the authors take a very different approach.
The bulk of the material consists of a detailed discussion of 50 ‘laws’, 25 hypotheses and 12 conjectures based on the template: 1) a highlighted sentence making some claim, 2) Applicability, i.e., situations/context where the claim is likely to apply, 3) Evidence, i.e., citations and brief summary of studies.
As researchers of many years standing, I think the authors wanted to present a case that useful things had been discovered, even though the data available to them is nowhere near good enough to be considered convincing evidence for any of the laws/hypotheses/conjectures covered. The reasons I think this book is worth looking at are not those intended by the authors; my reasons include:
- the contents mirror the unquestioning mindset that many commercial developers have for claims derived from the results of software research experiments, or at least the developers I talk to about software research. I’m forever educating developers about the need for replications (the authors give a two paragraph discussion of the importance of replication), that sample size is crucial, and using professional developers as subjects.
Having spent twelve chapters writing authoritatively on 50 ‘laws’, 25 hypotheses and 12 conjectures, the authors conclude by washing their hands: “The laws in our set should not be seen as dogmas: they are not authoritatively asserted opinions. If proved wrong by objective and repeatable observations, they should be reformulated or forgotten.”
For historians of computing this book is a great source for the software folklore of the late 20th/early 21st century,
- the Evidence sections for each of the laws/hypotheses/conjectures is often unintentionally damming in its summary descriptions of short/small experiments involving a handful of people or a few hundred lines of code. For many, I would expect the reaction to be: “Is that it?”
Previously, in developer/researcher discussions, if a ‘fact’ based on the findings of long ago software research is quoted, I usually explain that it is evidence-free folklore; followed by citing The Leprechauns of Software Engineering as my evidence. This book gives me another option, and one with greater coverage of software folklore,
- the quality of the references, which are often to the original sources. Researchers tend to read the more recently published papers, and these are the ones they often cite. Finding the original work behind some empirical claim requires following the trail of citations back in time, which can be very time-consuming.
Endres worked for IBM from 1957 to 1992, and was involved in software research; he had direct contact with the primary sources for the software ‘laws’ and theories in circulation today. Romback worked for NASA in the 1980s and founded the Fraunhofer Institute for Experimental Software Engineering.
The authors cannot be criticized for the miniscule amount of data they reference, and not citing less well known papers. There was probably an order of magnitude less data available to them in 2002, than there is available today. Also, search engines were only just becoming available, and the amount of material available online was very limited in the first few years of 2000.
I started writing a book in 2000, and experienced the amazing growth in the ability of search engines to locate research papers (first using AltaVista and then Google), along with locating specialist books with Amazon and AbeBooks. I continued to use university libraries for papers, which I did not use for the evidence-based book (not that this was a viable option).
Christmas books for 2022
This year’s list of books for Christmas, or Isaac Newton’s birthday (in the Julian calendar in use when he was born), returns to its former length, and even includes a book published this year. My book Evidence-based Software Engineering also became available in paperback form this year, and would look great on somebodies’ desk.
The Mars Project by Wernher von Braun, first published in 1953, is a 91-page high-level technical specification for an expedition to Mars (calculated by one man and his slide-rule). The subjects include the orbital mechanics of travelling between Earth and Mars, the complications of using a planet’s atmosphere to slow down the landing craft without burning up, and the design of the spaceships and rockets (the bulk of the material). The one subject not covered is cost; von Braun’s estimated 950 launches of heavy-lift launch vehicles, to send a fleet of ten spacecraft with 70 crew, will not be cheap. I’ve no idea what today’s numbers might be.
The Fabric of Civilization: How textiles made the world by Virginia Postrel is a popular book full of interesting facts about the economic and cultural significance of something we take for granted today (or at least I did). For instance, Viking sails took longer to make than the ships they powered, and spinning the wool for the sails on King Canute‘s North Sea fleet required around 10,000 work years.
Wyclif’s Dust: Western Cultures from the Printing Press to the Present by David High-Jones is covered in an earlier post.
The Second World Wars: How the First Global Conflict Was Fought and Won by Victor Davis Hanson approaches the subject from a systems perspective. How did the subsystems work together (e.g., arms manufacturers and their customers, the various arms of the military/politicians/citizens), the evolution of manufacturing and fighting equipment (the allies did a great job here, Germany not very good, and Japan/Italy terrible) to increase production/lethality, and the prioritizing of activities to achieve aims. The 2011 Christmas books listed “Europe at War” by Norman Davies, which approaches the war from a data perspective.
Through the Language Glass: Why the world looks different in other languages by Guy Deutscher is a science driven discussion (written in a popular style) of the impact of language on the way its speakers interpret their world. While I have read many accounts of the Sapir–Whorf hypothesis, this book was the first to tell me that 70 years earlier, both William Gladstone (yes, that UK prime minister and Homeric scholar) and Lazarus Geiger had proposed theories of color perception based on the color words commonly used by the speakers of a language.
Printing press+widespread religious behavior: A theory
The book The Weirdest People in the World: How the West Became Psychologically Peculiar and Particularly Prosperous provides an explanation of the processes which weakened the existing social ties of family and tribe; however, the emergence of WEIRD people (Western, Educated, Industrialized, Rich and Democratic) required new social norms to spread and be accepted throughout society. A major technical innovation, in the form of the printing press, provided the means for mass communication of ideas and practices.
David High-Jones’ book Wyclif’s Dust: Western Cultures from the Printing Press to the Present describes the social consequences of what he calls book religion; a combination of deeply religious western societies and the ability of individuals to write and sell affordable books (made possible by the printing press). Religion+printing press created the conditions for what High-Jones calls a hothouse culture, a period from the 1600s to the end of the 1800s.
Around 1440 the printing press is invented and quickly spreads; around 5 million books were handwritten in the 1400s, about 80 million books were produced in the first 50 years of printing, and around a billion in the 1700s. During the 1500s the Protestant reformation happens; Protestant encouraged its followers to read the Bible, which creates a demand for printed Bibles and the need to be able to read (which increases literacy rates). In England, between 1480-1640, 40% of published books were religious.
The changes to society’s existing norms are wrought by cultural transmission, initially via middle class parents making use of edifying books to teach their children moral values and social skills, later Sunday schools took on this role, but also had to offer reading lessons to attract members. In the adult world, accepted norms were maintained by social enforcement. The impact on western societies was widespread because observant religious behavior was widespread.
The original intent, of those writing the religious books, was the creation of a god fearing society. In practice, a trust based society was created, where workers might be relied upon not to shirk their duties and businessmen to not renege on agreements.
In the beginning science, in the form of printed technical books, rarely made an appearance. In the 1700s the Enlightenment happens, and scientific books are discussed by small collections of disparate individuals. The industrial revolution happens, but the bulk of the demand is for trustworthy workers; technical and scientific know how remains a minority interest.
In Part I of the book, High-Jones weaves a reading and convincing narrative. Part II, 1900 to today, is a tale of the crumbling and breakdown of the social forces and incentives that creates the trust based society; while example are enumerated, no overarching theory is proposed (I skimmed this part).
Recent Comments