Archive
Program fault reports are caused by its users
Faults are generated by users of the software; no users, no fault reports. Fault reports will be generated for software that is free of coding mistakes; one study found that 42.6% of fault reports were misclassified as either requests for an enhancement, changes to documentation, or a refactoring request, or not requiring changes to the code; a study of NASA spaceflight software found that 63% of reports in the defect tracking tool were change requests.
Is the number of reported faults proportional to the number of users, the log of the number of users, or perhaps it depends on the application, or who knows what?
Some users will only use some features, others other features. Some users will be occasional users, while some will be heavy users.
There are a handful of fault report datasets containing measurements of software usage. The largest, and most widely cited, is “Optimizing Preventive Service of Software Products” by E. N. Adams. The data is this paper lists the number of faults reported in eight time intervals (20 to 50,000 months), for nine applications running on IBM mainframes between 1975 and 1980. Traditionally, the licensing for many Mainframe applications charge customers a fee based on their usage. Does this usage data still exist? Perhaps there is some sitting on a shelf in court documents. Pointers to possible cases most welcome.
Early papers on software testing sometimes measured the amount of cpu, or elapsed time, between each fault experience. However, the raw data was rarely published.
Data is available, for the Debian and Ubuntu distributions, on the number of installs for each application (counts rely on local machine sending information on installs, which is now an opt-in process for Ubuntu).
The following analysis uses data from the paper Impact of Installation Counts on Perceived Quality: A Case Study on Debian by Herraiz, Shihab, Nguyen, and Hassan, and the Ubuntu popularity project.
The plot below shows the number of reported faults against number of installs for the 14,565 programs in the “wheezy” Debian release; red line is the fitted power law:  (code+data):
(code+data):
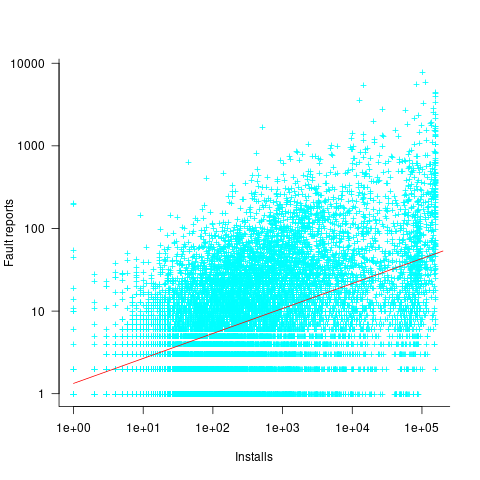
The huge variability in the number of fault reports for a given number of installs is likely driven by variability in the usage of the installed programs (or even no usage; I installed ImageMagick purely to use its convert program), the propensity of users of particular programs to report fault experiences (which in turn depends on the need for a fix, and the ease of reporting), and the number of coding faults in the source code.
The Debian installs/faults data does not include any usage information, however, the Ubuntu popularity data includes not only a count of installs, but the corresponding counts of regular users and non-usages. Given that Ubuntu is a fork of Debian, and has substantial usage, I’m assuming that the user base is sufficiently similar that the Ubuntu usage data at the time of the “wheezy” release can be applied to the “wheezy” Debian install/fault data.
The plot below shows, for 220,309 programs, the fraction of installs that are regularly used against the corresponding number of installs. The left-most line running top-left to bottom-right shows programs regularly used by one install, next line two regular users, etc (code+data):

Using the merged, by program name, Ubuntu usage/Debian fault counts, I built several regression models, along with plotting the data/fits. The quality of the models was worse than the original Debian model 🙁 . Two possibilities that spring to mind are: the correlation between usage and fault reports only becomes visible when the counts are divided into short periods (perhaps a year?), or the correlation is very weak. It is probably going to take a lot of time to work through this.
Research ideas for 2023/2024
Students sometimes ask me for suggestions of interesting research problems in software engineering. A summary of my two recurring suggestions, for this year, appears below; 2016/2017 and 2019/2020 versions.
How many active users does a program or application have?
The greater the number of users, the greater the number of reported faults. Estimates of program reliability have to include volume of usage as an integral part of the calculation.
Non-trivial amounts of public data on program usage is non-existent (in a few commercial environments, users are charged for using software on a per-usage basis, but this data is confidential). Usage has to be estimated by indirect means.
A popular indirect technique for estimating the popularity of Github repos is to count the number of stars it has; however, stars have a variety of interpretations. The extent to which Github stars tracks usage of the repo’s software is not known.
Other indirect techniques include: web server logs, installs of the application, or the operating system.
One technique that has not yet been researched is to make use of the identity of those reporting faults. A parallel can be drawn with the fish population in lakes, which is not directly visible. Ecologists have developed techniques for indirectly estimating the population size of distinct creatures using information about a subset of the population, and some of the population models developed for ecology can be adapted to estimating program user populations.
Estimates of population size can be obtained by plugging information on the number of different people reporting faults, and the number of reports from the same person into these models. This approach is not as easy as it sounds because sometimes the same person has multiple identities, reported faults also need to be deduplicated and cleaned (30-40% of reports have been found to be requests for enhancements).
Nested if-statement execution
As if-statement nesting depth increases, the number of conditions controlling the execution of the enclosed code increases.
Being able to estimate the likelihood of executing the code controlled by an if-statement is of interest to: compilers wanting to target optimizations along the most frequently executed paths, special handling for error paths, testing along the least/most likely paths (e.g., fuzzers wanting to know the conditions needed to reach a given block), those wanting to organize code for ease of understanding, by reducing cognitive effort to understand.
Possible techniques for analysing the likelihood of executing code controlled by one or more nested if-statements include:
- Compiler writers have discovered various heuristics for predicting the likely outcome of a branch, and there are probably more to be discovered. Statement coverage counts provides a ground truth against which to compare ideas,
- analysis of the conditional expression,
- mathematical analysis of the distribution of values of variables in conditional expressions.
New users generate more exceptions than existing users (in one dataset)
Application usage data is one of the rarest kinds of public software engineering data.
Even data that might be used to approximate application usage is rare. Server logs might be used as a proxy for browser usage or operating system usage, and number of Debian package downloads as a proxy for usage of packages.
Usage data is an important component of fault prediction models, and the failure to incorporate such data is one reason why existing fault models are almost completely worthless.
The paper Deriving a Usage-Independent Software Quality Metric appeared a few months ago (it’s a bit of a kitchen sink of a paper), and included lots of usage data! As far as I know, this is a first.
The data relates to a mobile based communications App that used Google analytics to log basic usage information, i.e., daily totals of: App usage time, uses by existing users, uses by new users, operating system+version used by the mobile device, and number of exceptions raised by the App.
Working with daily totals means there is likely to be a non-trivial correlation between usage time and number of uses. Given that this is the only public data of its kind, it has to be handled (in my case, ignored for the time being).
I’m expecting to see a relationship between number of exceptions raised and daily usage (the data includes a count of fatal exceptions, which are less common; because lots of data is needed to build a good model, I went with the more common kind). So a’fishing I went.
On most days no exception occurred (zero is the ideal case for the vendor, but I want lots of exception to build a good model). Daily exception counts are likely to be small integers, which suggests a Poisson error model.
It is likely that the same set of exceptions were experienced by many users, rather like the behavior that occurs when fuzzing a program.
Applications often have an initial beta testing period, intended to check that everything works. Lucky for me the beta testing data is included (i.e., more exceptions are likely to occur during beta testing, which get sorted out prior to official release). This is the data I concentrated my modeling.
The model I finally settled on has the form (code+data):

Yes,  had a much bigger impact than
had a much bigger impact than  . This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two.
. This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two.
Why square-root, rather than log? The model fit was much better for square-root; too much better for me to be willing to go with a model which had  as a power-law.
as a power-law.
The impact of  varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).
varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).
There were not nearly as many exceptions once the App became generally available, and there were a lot fewer exceptions for the iOS version.
The outsized impact of new users on exceptions experienced is easily explained by developers failing to check for users doing nonsensical things (which users new to an App are prone to do). Existing users have a better idea of how to drive an App, and tend to do the kind of things that developers expect them to do.
As always, if you know of any interesting software engineering data, please let me know.
Recent Comments