Finding the gold nugget papers in software engineering research
Academic research projects are like startups in that most fail to make any return on their investment (e.g., the tax payer does not get any money back) and a few pay for themselves and all the failures. Irrespective of whether a project succeeds or fails, those involved will publish papers on the work, give talks at conferences and workshops and general try to convince anyone who will listen that the project was a great success.
Number or papers published plays an important role in evaluating the quality of a university department and the performance on an individual researcher. As you can imagine, this publish or perish culture leads to huge amounts of clueless nonsense ending up in print. Don’t be fooled by the ‘peer reviewed’ label, most of this gets done by the least experienced people (e.g., postgrad students) as a means of gaining social recognition in their specific research community, i.e., those doing the reviewing don’t always know much.
The huge number of papers describing failed projects and/or containing clueless nonsense is a major obstacle for anyone wanting to locate useful new knowledge.
While writing my C book I refined the following approach to finding high quality papers and created filtering rules for the subjects it covered. The rules below are being applied to papers relating to my Empirical Software Engineering book. I don’t claim any usefulness for these rules outside of academic software engineering research.
I use a scatter gun approach to obtain a basic collection of papers followed by ruthless filtering.
The scatter gun approach might start with one or two papers; following links on Google Scholar or even just Google search results filtered on “filetype:pdf”, in the past I have used CiteSeer which Google now does a better job of indexing, and Semantic Scholar is now starting to be quite good.
After 30 minutes or so I have 50 pdfs (I download maybe 4,000 a year). Now I need to quickly filter the nonsense to end up with maybe 10 that I will spend 5 minutes each reading, leaving maybe 2 or 3 for detailed reading (often not the original ones I started with).
When dealing with this kind of volume you have to be ruthless.
Spend just 10 seconds on the first pass. If a paper has some merits, let it remain for the next pass. Scan the paper looking for major indicators of clueless nonsense; these are not hard to spot, don’t linger, hit the delete (if data is involved, it is worth quickly checking the footnotes for a url to a dataset, which may be new and worth collecting):
- it relies on machine learning,
- it relies on information theory,
- it relies on Halstead’s metric,
- it investigates software quality. This is a marketing term used to give a patina of relevance to the worthless metric that is likely used in the research. Be on the lookout for other high relevance terms being used to provide a positive association with a worthless metric, e.g., developer productivity defined as volume of code written
- it involves fault prediction. Academic folk psychology includes a belief that some project files contain more faults than other files, because more faults are reported in some files than others (or even that entire projects are more reliable because fewer faults have been reported). This is a case of the drunk searching under a streetlight for lost keys because that is where the ground can be seen. Faults are found by executing code, more execution means more faults. I only know of two papers that are exceptions to this rule (one of them is discussed here),
- the primary claim in the conclusion is to have done something novel. Research requires doing new stuff, novel is a key attribute that is rather pointless for its own sake. Typing code using your nose would be novel, but would you want to spend more than 10 seconds reading a paper on the subject (and this example is at the more sensible end of the spectrum of novel research I have read about).
The first pass removes around 70-80% of the papers, at least for me.
For the second pass I will spend a minute or so doing a slightly slower scan. This often cuts the papers remaining in half.
By now, I have been collecting and filtering for over 90 minutes; time to do something else, perhaps not returning for many hours.
The third pass involves trying to read the paper. The question is: Am I having trouble reading this paper because the author has managed to compress a lot of useful information into a publication page limit, or is the paper so bad I cannot see the wood for the dead trees?
Answering this question takes practice and some knowledge of the subject area. You will speed up with practice and learning about the subject.
Some things that might be thought worth paying attention to, but should be ignored:
- don’t bother looking at the names of the authors or which university they work at (who wrote the paper almost always provides no clues to its quality; there are very few exceptions to this and you will learn who they are over time),
- ignore the journal or conference that published the paper (gold nuggets appear everywhere and high impact venues only restrict the clueless nonsense to the current trendy topics and papers citing the ‘right’ people),
- ignore year of publication, quality is ageless (and sometimes fades from view because research fashions change).
If you have your own tips for finding the gold nuggets in software engineering, please let me know.
Predicting the next value in an integer sequence
There was a Kaggle meetup group hackathon on Saturday. Integer sequence learning is a recently posted Kaggle challenge; build a model to predict the next value in an integer sequence, with example data coming from the On-Line Encyclopedia of Integer Sequences. How could I not want to try my hand at this challenge, and I signed up for the hackathon hoping to find like-minded folk.
My only previous encounter with mining the OEIS was a paper that attempted to combine two or more existing sequences to match one existing sequence and to contribute a few sequences I had found.
The event was well attended, and I found a fellow enthusiast in Lampros.
We kicked around a few ideas and while I jumped in and started investigating the characteristics of the data, Lampros started searching for solutions that others had found to the next value in an integer sequence problem (a much more sensible approach, but probably not as much fun as jumping in feet first; this was his first hackathon, so he has not picked up any bad habits yet ;-).
This is one of those few problems when over-fitting is required for things to work.
I concentrated on characterizing the 113,845 sequences in the training set and the following is a summary (code and data):
- 74,465 sequences contained a maximum value less than
 and 98,916 less than
and 98,916 less than  . So symbolic maths is going to be needed (a shame since I had found tscount, an R package for analyzing count time series),
. So symbolic maths is going to be needed (a shame since I had found tscount, an R package for analyzing count time series), - a goodly 72,202 sequences are in sorted order, leaving 41,643 to go up and down,
- The least significant digit of the values in many sequences are a subset of the ten possible values. The following is a list of the number of unique least significant digits in the training sequences:
1 2 3 4 5 6 7 8 9 10 1289 4692 6800 11589 15773 13701 7635 8644 10837 32885
After removing sequences containing fewer than 20 values (the -1 count)
-1 1 2 3 4 5 6 7 8 9 10 33398 764 3006 3171 6068 8930 7898 3690 5604 9073 32243
Lampros found Martin Rubey’s work on guessing formulas for sequences, which had an Open Source implementation using FriCAS (source code, which needs Steel Bank Common Lisp to build, which itself needs your OS to support 512 open files {OS X default is 256}).
Other software and papers include: the gfun package plus paper, sequence prediction in Mathematica and a Masters thesis on Inductive Inference of Integer Sequences.
These systems are all based on fitting, a potentially very complicated, polynomial to each sequence and achieve a success rate of around 20% on the complete OEIS.
What are the characteristics of the 80% for which a polynomial fit does not predict the next value? Perhaps there are not enough values specified in these sequence to fit the necessary polynomial. Perhaps the values grow at a faster rate than can be fitted by any polynomial expression, e.g., the Busy beaver function.
A 11:00-17:00 hackathon is not really enough time to get anything sensible up and running. People doing Masters projects had more hours and were managing to get around 20% correct.
The competition leaderboard currently has somebody with a score of 0.74. This is a big lead over everybody else. Am I being cynical by thinking the model might be reading the OEIS text to find the formula describing the sequence and then evaluating this?
Update
Comparing Computer Models Solving Number Series Problems provides an interesting review of systems using an AI based approach, i.e., trying to mimic what people do.
The fall of Rome and the ascendancy of ego and bluster
The idea that empirical software engineering started 10 years ago, driven by the availability of Open Source that could be measured, turns out to be a rather blinkered view of history.
A few months ago I was searching for a report and tried the Defense Technical Information Center (DTIC), which I had last tried many years ago. The search quickly located the report, plus lots of other stuff, and over the next few weeks I downloaded a few hundred interesting looking reports. These are pdfs that often don’t show up in Google searches and sometimes not on DTIC searches unless the right combination of words is used (many of the pdfs have been created by converting microfiche copies of the original paper, with some, often very good, OCR thrown into the mix).
It turns out that during the 1970s at the Rome Air Development Center (RADC was the primary research lab of the US Air Force) something of a golden age for empirical software engineering research occurred (compared to the following 25 years).
The ingredients necessary for great research came together at Rome during this decade: the US Department of Defense were spending huge amounts of money creating lots of software systems; the management at RADC understood the importance of measurement and analysis, and had the money to hire good consultants to do it.
Why did the volume of quality reports coming out of RADC decline in the 1980s (it closed in 1991)? I have no idea, perhaps the managers responsible for the great work moved on or priorities changed.
Ego and bluster is how software engineering research operated after the decline of Rome (I’m sure plenty of it occurred before and during Rome). A researcher or independent consultant had an idea about how they thought things worked (perhaps bolstered by a personal experience, not lots of data) and if their ego was big enough to think this idea was a good model of reality and they invest enough time blustering their way through workshop presentations and publishing papers, then the idea could become part of mainstream thinking in academia; no empirical evidence needed.
The start of the ego and bluster period could be said to be 1981, the year in which Software Engineering Economics by Barry Boehm was published, and 2008 as the end of the ego and bluster period (or at least the start of its decline) the year of publication of the 3rd edition of Applied Software Measurement by Capers Jones. Both books dress up tiny amounts of empirical data as ‘proof’ of the ideas being promoted.
Without measurement data researchers have to resort to bluster to hide the flimsy foundations of the claims being made, those with the biggest egos taking center stage. Commercial companies are loath to let outsiders measure what they are doing and very few measure what they are doing themselves (so even confidential data is rare). Most researchers moved onto other topics once they realised how little data was available or could be made available to them.
Around 2005, or so, the volume of papers using new empirical data started to grow and a trickle has now turned into a flood. Of course making use of empirical data does not prevent research papers being a complete waste of time and ego and bluster is still widely practiced (and not limited to software engineering).
While a variety of individuals and research groups around the world (sadly only individuals in the UK) are actively working on extracting and analysing open source systems, practical progress has been very slow. Researchers are still coming to grips with the basic characteristics of the data they are seeing.
The current legacy, in software engineering, of long standing beliefs (built on tiny datasets) is a big problem. Lots of researchers have not seen through the bluster and are spending lots of time and effort trying to accommodate the results they are obtaining with what are mistakenly taken to be ‘established’ theories. One example is “Program Evolution – Processes of Software Change” by Lehman and Belady, from the late 1970s. Researchers need to stop looking at Lehman’s ‘laws’ through rose tinted glasses; a modern paper making Lehman’s claims based on such a small set of measurements would be laughed.
Most of those now working with empirical data are students working towards a postgraduate degree, some of whom have gone on to get full-time research jobs. Unfortunately there are still many researchers applying the habits they acquired during the ego and bluster period; fit some old data using the latest fashionable technique, publish and quickly move on to the next fashionable technique. As Max Planck observed, science advances one funeral at a time.
What is the name should be given to this new period of software engineering research? We will probably have to wait many more years before things become clear.
Software Reliability is one report from the Rome period that is well worth checking out.
NASA sponsored research was hit and mostly miss. One very interesting sequence of experiments is documented in: Software reliability: Repetitive run experimentation and modeling and An experiment in software reliability.
Software Reliability: Lots of detailed data and thoughtful analysis
The 1978 book “Software Reliability” by Thayer, Lipow and Nelson is the only wide-ranging publicly available source of detailed software development project data that I am aware of. While analysis of Open Source, which started around 10 years ago, has added much more detail in some areas it has added almost nothing in other areas (e.g., manpower and requirements data). The analysis in this book is also very thorough, making good use of the statistical techniques available back in the day.
A few weeks ago I found an online pdf of the report from which the book is very closely derived. Anyone interested in software engineering should read this report, I’m not sure much of the state of the art has progressed that much since its publication in 1976.
The pdf was created from a microfiche copy of the original document and the numbers in some tables are illegible. I have photographed, in my copy of the book, the tables containing numbers printed using a small point size and you can download the jpegs (I don’t have the time to transcribe them to ascii text; please let me know if you do this).
Why did this book/report rapidly disappear into almost total obscurity? Perhaps it contained too much data and did too good a job of analysing it, compared to what came soon after it. Perhaps because it did not have a champion to sing its praises (wanting to build a personal career can have benefits for those other than the person doing the building).
COCOMO: Not worth serious attention
The Constructive Cost Model (COCOMO) was introduced to the world by the book “Software Engineering Economics” by Barry Boehm; this particular version of the model is now known by the year of publication, COCOMO 81. The book describes a model that estimates software project cost drivers, such as effort (in man months) and elapsed time; the data from the 63 projects used to help calibrate the equations appears on pages 496-497.
Only having 63 measurements to model such a complex problem means any predictions will have very wide error bounds; however, the small amount of data did not stop Boehm building an academic career out of over-fitting these 63 measurements using 17 input parameters (the COCOMO II book came out in 2000 and was initially calibrated by fitting 22 parameters to 83 measurement points and then by fitting 23 parameters to 161 measurement points; the measurement data does not appear to be publicly available).
A sentence on page 493 suggests that over-fitting may not be the only problem to be found in the data analysis: “The calibration and evaluation of COCOMO has not relied heavily on advanced statistical techniques.”
Let’s take the original data and duplicate the original analysis, before trying something more advanced (code+data).
A central plank of the COCOMO model is the equation:  , where
, where  is total effort in man months,
is total effort in man months,  a constant obtained by fitting the data,
a constant obtained by fitting the data,  thousands of lines of source code and
thousands of lines of source code and  a constant obtained by fitting the data.
a constant obtained by fitting the data.
This post discusses fitting this equation for the three modes of software projects defined by Boehm (along with the equations he fitted):
- Organic, relatively small teams operating in a highly familiar environment:
 ,
, - Embedded, the product has to operate within strongly coupled, complex, hardware, software and operational procedures such as air traffic control:
 ,
, - Semidetached, an intermediate stage between the two extremes:
 .
.
The plot below shows kSLOC against Effort, with solid lines fitted using what I guess was Boehm’s approach and dashed lines showing fitted lines after removing outliers (Figure 6-5 in the book has the x/y axis switched; the points in the above plot appear to match those in this figure):
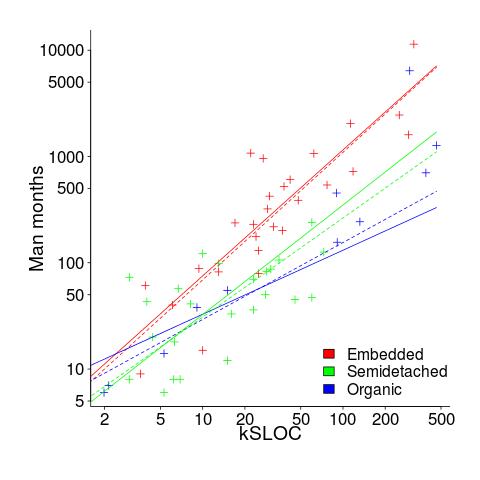
The fitted equations are (the standard error on the multiplier, , is around ±30%, while on the exponent, , the absolute value varies between ±0.1 and ±0.2):
- Organic:
 , after outlier removal
, after outlier removal 
- Embedded:
 , after outlier removal
, after outlier removal 
- Semidetached:
 , after outlier removal
, after outlier removal  .
.
The only big difference is for Organic, which is very different. My first reaction on seeing this was to double check the values used against those in the book. How did Boehm make such a big mistake and why has nobody spotted it (or at least said anything) before now? Papers by Boehm’s students do use fancy statistical techniques and contain lots of tables of numbers relating to COCOMO 81, but no mention of what model they actually found to be a good fit.
The table on pages 496-497 contains man month estimates made using Boehm’s equations (the EST column). The values listed are a close match to the values I calculated using Boehm’s Semidetached equation, but there are many large discrepancies between printed values and values I calculated (using Boehm’s equations) for Organic and Embedded. If the data in this table contains a lot of mistakes, it may explain why I get very different values fitting the data for Organic. Some ther columns contain values calculated using the listed EST values and the few I have checked are correct, so if there was an error in the EST value calculation it must have occurred early in the chain of calculations.
The data for each of the three modes of software development contain several in your face outliers (assuming the values are correct). Based on the fitted equations is does not look like Boehm removed these (perhaps detecting outliers is an advanced technique).
Once the very obvious outliers are removed the quadratic equation,  , becomes a viable competing model. Unfortunately we don’t have enough data to do a serious comparison of this equation against the COCOMO equation.
, becomes a viable competing model. Unfortunately we don’t have enough data to do a serious comparison of this equation against the COCOMO equation.
In practice the COCOMO 81 model has been found to be highly inaccurate and very much dependent upon the interpretation of the input parameters.
Further down on page 493 we have: “I have become convinced that the software field is currently too primitive, and cost driver interaction too complex, for standard statistical techniques to make much headway;”.
With so much complexity and uncertainty, careful application of statistical techniques is the only way of reliable way of distinguishing any signal from noise.
COCOMO does not deserve anymore serious attention (the code+data includes some attempts to build alternative models, before I decided it was not worth the effort).
Applied Software Measurement: shame about the made up numbers
“Applied Software Measurement” by Capers Jones (no relation) is widely cited, but I find it a very frustrating book; while the text is full of useful commentary the numbers in the tables are mostly made up or estimated from other numbers (some of which may be actual measurements).
This book’s many tables of numbers will catch the attention of anyone searching for software engineering data (which until recently was very hard to find). However, closer inspection of the numbers suggests that the real purpose of the empirical looking tables is to serve as eye-candy to impress casual readers.
Let’s take as an example the analysis of multiple implementations, in different languages, of software implementing telephone switching system functionality. The numbers are from the third edition of the book (the one I have; code+data, separate paper discussing the numbers).
Below are the numbers from Table 2-7: Function Point and Source Code Sizes for 10 Versions of the Same Project.
All those 1,500’s are a bit suspicious; the second paragraph under the table says “… the original sizes ranged from about 1,300 to 1,750 …”. Why has a gratuitous 1.5% error been introduced?
Where did the values for language level come from? I once wrote the semantics phase of a CHILL compiler in Pascal and would have put CHILL’s language level on a par with Ada83. Objective C at 11 is surely a joke. Language level is a number, so obviously we can take its average.
This table looks like it has one column of actual data. Oh, five pages before the table appears we are told that the Ada95 and Objective C results were modeled, i.e., made up. So there are really only eight real implementations, not ten.
Language Function pts Language level LOC/Func. Pt. Size in LOC Assembly 1,500 1 250 375,000 C 1,500 3 127 190,500 CHILL 1,500 3 105 157,500 PASCAL 1,500 4 91 136,500 PL/I 1,500 4 80 120,000 Ada83 1,500 5 71 106,500 C++ 1,500 6 55 82,500 Ada95 1,500 7 49 73,500 Objective C 1,500 11 29 43,500 Smalltalk 1,500 15 21 31,500 Average 1,500 6 88 131,700 |
Moving on to Table 2-6, see below: “Staff Months of Effort for 10 Versions of the Same Software Project”
The use of two decimal places of accuracy is an obvious red flag for wanting to impress via appearance of accuracy.
Is the requirements effort based on one known value, or is it estimated? Why the jump in design time when we get to C++? Does management time really have such a strong dependency on language used?
Language Require.. Design Code Test Document Management TOTAL Effort Assembly 13.64 60.00 300.00 277.78 40.54 89.95 781.91 C 13.64 60.00 152.40 141.11 40.54 53.00 460.69 CHILL 13.64 60.00 116.67 116.67 40.54 45.18 392.69 PASCAL 13.64 60.00 101.11 101.11 40.54 41.13 357.53 PL/I 13.64 60.00 88.89 88.89 40.54 37.95 329.91 Ada83 13.64 60.00 76.07 78.89 40.54 34.99 304.13 C++ 13.64 68.18 66.00 71.74 40.54 33.81 293.91 Ada95 13.64 68.18 52.50 63.91 40.54 31.04 269.81 Objective C 13.64 68.18 31.07 37.83 40.54 24.86 216.12 Smalltalk 13.64 68.18 22.50 27.39 40.54 22.39 194.64 |
The above table makes more sense when LOC is plotted against Total Effort (in man months), see below:
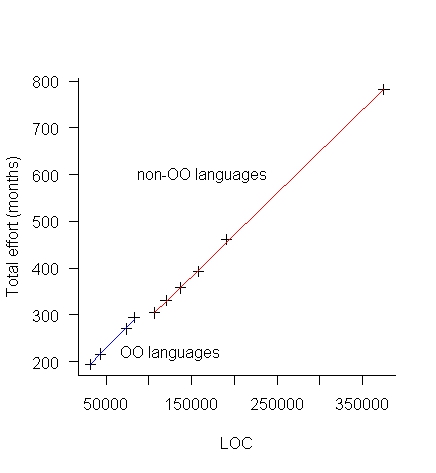
The blue line is for the object oriented languages (i.e., the last four rows of the table) and the red line everything else. Those two straight lines fit the data so well; I think that Total Effort was calculated from LOC and various rules of thumb used to create percentages for requirements, design, code, test, documentation and management.
There is no new data in the above table, it was all calculated from LOC and informed arm waving.
Table 2-9 and Table 2-11 list Total Effort (which has been estimated from LOC) and columns of values created by dividing or multiplying this by other estimated values.
Table 2-12, see below: “Defect Potentials for 10 Versions of the Same Software Project”
What is a Defect Potentials?
Again, a sudden jump in the design numbers at C++.
Language Require.. Design Code Document Bad Fix TOTAL Defects Assembly 1,500 1,875 7,500 900 1,060 12,835 C 1,500 1,875 3,810 900 728 8,813 CHILL 1,500 1,875 3,150 900 668 8,093 PASCAL 1,500 1,875 2,730 900 630 7,635 PL/I 1,500 1,875 2,400 900 601 7,276 Ada83 1,500 1,875 2,130 900 576 6,981 C++ 1,500 2,025 1,650 900 547 6,622 Ada95 1,500 2,025 1,470 900 531 6,426 Objective C 1,500 2,025 870 900 477 5,772 Smalltalk 1,500 2,025 630 900 455 5,510 |
Plotting total defects against LOC (below) suggests that “Defect Potentials” is a number calculated from LOC, i.e., no connection with actual defects found.
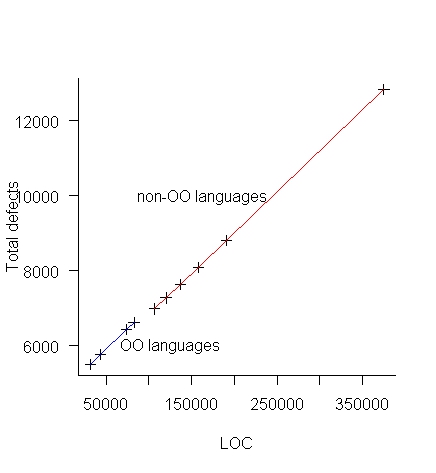
Table 2-13 lists Total Defects (which has been estimated from LOC) and columns of values created by dividing or multiplying this by other estimated values.
So the book contains six impressive looking tables whose numbers have been calculated in one way or another from lines of code. A very good description of the many other tables in the book.
Survival time of Linux distributions
Creating and maintaining Linux distributions is a surprisingly popular activity. The GNU/Linux Distribution Timeline listed over 500 distributions by the time recording stopped at the end of 2012.
Once a distribution becomes available, how long do the people involved on a distribution continue to maintain it? The plot below shows the survival curve for Linux distributions based on their original parent distribution; the five most popular parent distributions are shown (code+data).
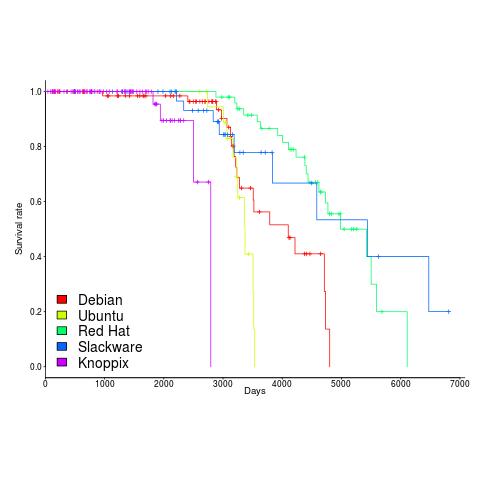
The plus-signs on lines are censored data, that is distributions that are still actively maintained (or at least not listed as no longer supported) when maintenance work on the timeline stopped (October 2012).
My interpretation of the data is that when the maintainers of a parent distribution are responsive to community pressure, it is difficult to motivate people to maintain a distribution derived from it.
RedHat is a commercial distribution and likely to be less focused on the developer community.
Ubuntu (79 derived distributions) and Knoppix (20 derived distributions) are relative newcomers. It looks like Knoppix has been squeezed out by the top 4.
Update in 2024
Fabio Loli has been updating the timeline.
Cost/performance analysis of 1944-1967 computers: Knight’s data
Changes In Computer Performance and Evolving Computer Performance 1963-1967, by Kenneth Knight, are the references to cite when discussing the performance of early computers. I suspect that very few people have read the two papers they are citing (citing without reading is a surprisingly common practice). Both papers were published in Datamation, a computer magazine whose technical contents could rival that of the ACM journals in the 1960s, but later becoming more of a trade magazine. Until the articles appeared on bitsavers.org they were only really available through national or major regional libraries.
Both papers contain lots of interesting performance and cost data on computers going back to the 1940s. However, I was not interested enough to type in all that data. This week I found high quality OCRed copies of the papers on the Internet Archive; my effort was reduced to fixing typos, which felt like less work.
So let’s try to reproduce Knight’s analysis of the data (code and data). Working in the mid-1960s, I imagine Knight did everything manually, with the help of mechanical calculators. I have the advantage of fancy software, a very fast computer and techniques that were invented after Knight did his analysis (e.g., generalized linear methods).
Each paper contains its own dataset: the first contains performance+cost data on 225 computers available between 1944 and 1963, while the second contains this information on 63 computers available between 1963 and 1967.
The dataset lists the computer name, the date it was introduced, number of operations per second and the number of seconds that can be rented for a dollar (most computer time used to be rented, then 25 years later personal computers came along and people got to own one, now, 25 years after that Cloud is causing a switch back to rental per second).
How are operations measured? The MIPS unit of measurement did not start to be generally used until the 1980s. Knight used 30 or so system characteristics, such as time to perform various arithmetic operations and I/O time, plus characteristics of scientific and commercial applications to calculate a value considered to be a representative scientific or commercial operation.
There is no mention of how seconds-per-dollar values were obtained. Did Knight ask customers or vendors? In a rental market, I imagine vendor pricing could be very flexible.
In the 1970s people started talking about Moore’s law, but in the 1960s there was Grosch’s law: Computer performance increases as the square of the cost, i.e., faster computers were cheaper to rent, for a given number of operations. Knight set out to empirically check Grosch’s law, i.e., he was looking for a quadratic fit.
Fitting a regression model to the 1950-1961 data, Knight obtained an exponent of 2.18, while I obtained 2.38 for commercial operations (using a slightly more sophisticated model, because I could); time on faster computers was cheaper than Grosch claimed. For scientific operations, Knight obtained 1.92, while I obtained 3.56; despite trying all sorts of jiggery-pokery I could not get a lower value. Unless Knight used very different values to the ones published in the ‘scientific’ columns, one of us has made a big mistake (please let me know if my code is wrong).
Fitting a regression model to the 1963-1967 data, I get figures (both around 2.85 and 2.94) that are roughly in agreement with Knight (2.5 and 3.1). Grosch’s law has broken down by 1963 (if it ever held for scientific operations).
The plot below shows operations per second against operationsseconds per dollar for the 1953-1961 data, with fitted lines for some specific years. It shows that while customers get fewer seconds per dollar on faster computers, the number of operations performed in those seconds is raised to the power of two+ (code and data):
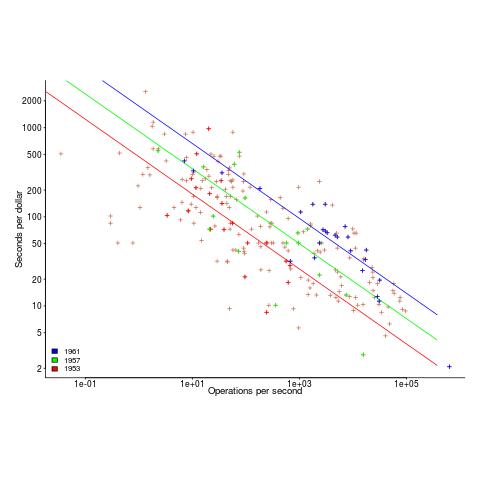
What other information can be extracted from the data? The 1953-1961 data shows seconds per dollar increased, over the whole performance range, by a factor of 1.15 per year, i.e., 15%, for both scientific and commercial; the 1963-1967 year-on-year increase jumps around a lot.
The dance of the dead cat
The flagging of unspecified behavior in C source by static analysis tools (i.e., where the standard specifies two or more possible behaviors for translators to choose from when generating code) is starting to rather get sophisticated, some tools are working out and reporting how many different program outputs are possible given the unspecified behavior in the source (traditionally tools simply point at code containing an instance of unspecified behavior).
A while ago I created a function where the number of possible different values returned, driven by one unspecified behavior in the code, was a Fibonacci number (the value of the function parameter selected the n’th Fibonacci number).
Weird ways of generating Fibonacci numbers are great for entertaining fellow developers, but developers are unlikely to be amused by a tool that flags their code as generating Fibonacci possible values (rather than the one they are expecting).
The possibility of Fibonacci different values relies on the generated code cycling through all possible behaviors, allowed by the standard, at runtime. This can only happen if program execution uses a Just-in-Time compiler; the compile once before execution implementations used by most developers get to generate far fewer possible permitted values (i.e, two for this particular example). Who would be crazy enough to write a JIT compiler for C you ask? Those crazy people who translate C to JavaScript for one.
To be useful for developers who are not using a JIT compiler to execute their C code, static analysis tools that work out the number of possible values that could be produced are going to have to support a code-compiled-before-execution option. Tools that don’t support this option will have what they report dismissed as weird possibilities that cannot happen in the developer’s world.
In the code below, does setting the code-compiled-before-execution option guarantee that the function Schrödinger always returns 1?
int x; int set_x(void) { x=1; return 1; } int two_values(void) { x=0; return x + set_x(); // different evaluation order -> different value } bool Schrödinger(void) { return two_values() == two_values(); } |
A compiler is free to generate code that returns a value that depends on whether two_values appears as the left or right operand of a binary operator. Not the kind of behavior an implementor would choose on purpose, but inlining both calls could result in different evaluation orders for the two instances of the code contained in what was the function body.
Our developer friendly sophisticated static analysis tool vendor is going to have to support a different_calls_to_same_function_have_same_behavior option.
How can a developer find out whether the compiler they were using always generated code having the same external behavior for different instances of calls, in the source, to the same function? Possibilities include reading the compiler source and asking the compiler vendor (perhaps future releases of gcc and llvm will support a different_calls_to_same_function_have_same_behavior option).
As far as I know (not having spent a lot of time looking) none of the tools doing the sophisticated unspecified behavior stuff support either of the developer friendly options I am suggesting need to be supported. Tools I know about include: c-semantics (including its go faster commercial incarnation) and ch2o (which the authors tell me executes the Fibonacci code a lot faster than c-semantics; last time I looked ch2o needed more installation time for the support tools it uses than I was willing to spend, so I have not tried it); the Cerberus project has not released the source of their system yet (I’m assuming they will).
Explaining the decline of German comments in LibreOffice
The LibreOffice suite of office programs traces it origins back to StarWriter, first launched in 1985 by a German company. Given its German parentage it’s no surprise that the source code contains comments written in German.
There has been a push by the LibreOffice folks to convert the German comments to English comments. The plot below shows the number of German comments in the source of LibreOffice over time (release version numbers at the top and red line is the least squares fit of an exponential; code and data).
I am not only surprised to see such a regular decline in the number of German comments, but also that the decline is exponential.
The pattern of behavior may be driven by those doing the work:
Perhaps the issue is the skill required to convert the comments:
I find it hard to believe any of these mechanisms. Suggestions for easier to believe mechanisms welcome.