Producing software for money and/or recognition
In the commercial environment money makes the world go around, while in academia recognition (e.g., number of times your work is cited, being fawned over at conferences, impressive job titles) is the coin of the realm (there are a few odd balls who do it out of love for the subject or a desire to understand how things work, but modern academia is a large bureaucracy whose primary carrot is recognition).
There is an incentive problem for those writing software in academia; software does not attract much, if any, recognition.
Does the lack of recognition for writing software matter? Surely what counts are the research results, not the tools used to get there (be they writing software or doing mathematics).
A recent paper bemoans the lack of recognition for the development of Python packages for Astronomy researchers. Well, its too late now, they have written the software and everybody gets to make perfect copies for free.
What the authors of Astropy want, is for researchers who use this software to include a citation to it in any published papers. Do all 162 authors deserve equal credit? If a couple of people add a new package, should they get a separate citation? What if a new group of people take over maintenance, when should the citation switch over from the old authors/maintainers to the new ones? These are a couple of the thorny questions that need to be answered.
R is perhaps the most widely used academic developed software ecosystem. A small dedicated group of people has invested a lot of their time over many years to make something special. A lot more people have invested effort to create a wide variety of add-on packages.
The base R library includes the citation function, which returns the BibTeX information for a given package; ready to be added to a research papers work flow.
Both commercial and academic producers need to periodically create new versions to keep ahead of the competition, attract more customers and obtain income. While they both produce software to obtain ‘income’, commercial and academic software systems have different incentives when it comes to support for end users of the software.
Keeping existing customers happy is the way to get them to pay for upgrades and this means maintaining compatibility with what went before. Managers in commercial companies make sure that developers don’t break backwards compatibility (developers hate having to code around what went before and would love to throw it all away).
In the academic world it does not matter whether end users upgrade, as long as they cite the package, the version used is irrelevant; so there is a lot less pressure to keep backwards compatibility. Academics are supposed to create new stuff, they are researchers after all, so the incentives are pushing them to create brand new packages/systems to be seen as doing new stuff (and obtain a whole new round of citations). A good example is Hadley Wickham, who has created some great R packages, who seems to be continually moving on, e.g., reshape -> reshape2 -> tidyr (which is what any good academic is supposed to do).
The run-time performance of a system is something end users always complain about, but often get used to. The reason is invariably that there is little or no incentive to address this issue (for both commercial and academic systems). Microsoft Windows is slower than it need be and the R interpreter could go a lot faster (the design of the interpreter looks like something out of the 1980s; I’m seeing a lot of packages in R only, so the idea that R programs spend all their time executing in C/Fortran libraries may be out of date. Where is the incentive to use post-2000 designs?)
How many new versions of a software package can be produced before enough people stop being willing to pay for an update? How many different packages solving roughly the same problem can academics produce?
I don’t think producing new packages for income has a long term future.
Software architect is an illegal job title in the UK
If you are working in the UK with the job title “software architect”, or styling yourself as such, you are breaking the law. Yes, you are committing an offense under: Architects Act 1997 Part IV Section 20. In particular: “(1) A person shall not practise or carry on business under any name, style or title containing the word “architect” unless he is a person registered [F1 in Part 1 of the Register].”
The Architecture Registration Board are happy to take £142 off you, ever year, for the privilege of using architect in your job title. There is also the matter of a Part 3 examination; don’t know what that is.
If you really do like the word architect in your job title and don’t want to pay £142 a year, you could move into another line of business: “(2) Subsection (1) does not prevent any use of the designation “naval architect”, “landscape architect” or “golf-course architect”.” I am assuming that the he in the wording also applies to she‘s and that a sex change will not help.
Do building architects care? I suspect not. Are the police going to do anything about it? Well, if they don’t like you and are looking for some way of hauling you before the courts, the fine is not that bad.
A signature for the “embeddedness” of source code and developers?
Patterns in the use of source code can tell us a lot about the people who wrote the code, the characteristics of the hardware it runs on and what the application is all about.
Often the pattern of usage needs a lot of work to understand and many remain completely baffling, but every now and again the forces driving a pattern leap off the page. One such pattern is visible in the plot below; data courtesy of Jacob Engblom and the cbook data is from my C book (assuming you know something about the nitty gritty of embedded software development). It shows the percentage of functions defined to have a given number of parameters:
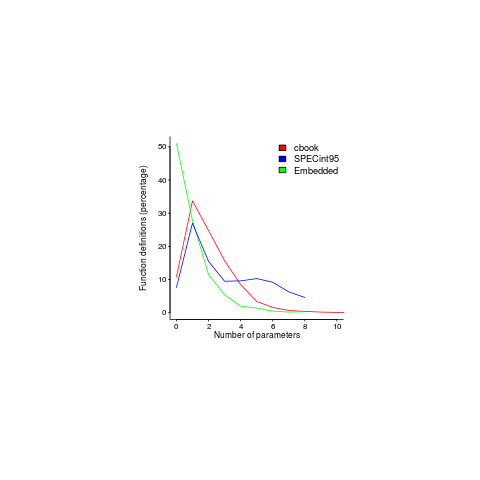
Embedded software has to run in very constrained environments. The hardware is often mass produced and saving a penny per device can add up to big savings, so the cheapest processor is chosen and populated with the smallest possible memory; developers have to work with what they are given. Power consumption may be down below one watt, so clock speeds are closer to 1 MHz than 1 GHz.
Parameter passing is a relatively expensive operation and there are major savings, relatively speaking, to be had by using global variables. Experienced embedded developers know this and this plot is telling us that they are acting on this knowledge.
The following are two ways of interpreting the embedded data (I cannot think of any others that make sense):
- the time/resource critical functions use globals rather than parameters and all the other functions are written more or less the same as in a non-embedded environment. In statistical terms this behavior is described by a zero-inflated model,
- there is pressure on the developer to reduce the number of parameters in all function definitions.
This data contains counts, so a Poisson distribution is the obvious candidate for our model.
My attempts to fit a zero-inflated model failed miserably (code+data). A basic Poisson distribution fitted everything reasonably well (let’s ignore that tiresome bump in the blue line); plus signs are the predictions made from each fitted model.
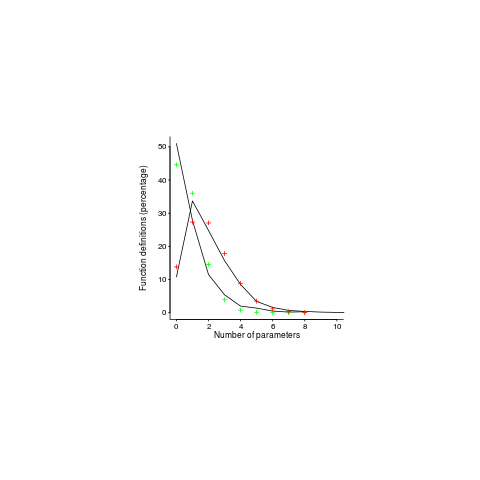
For desktop developers, the distribution of function definitions having a given number of parameters follows a Poisson distribution with a λ of 2, while for embedded developers λ is 0.8.
What about values of λ between 0.8 and 2; perhaps the λ of a project’s, or developer’s, code parameter count can be used as an indicator of ’embeddedness’?
What is needed to parameter count data from a range of 4-bit, 8-bit and 16-bit systems and measurements of developers who have been working in the field for, say, 4, 8, 16 years. Please let me know.
The data is from a Masters thesis written in 1999, is it still relevant today? Have modern companies become kinder to developers and stopped making their life so hard by saving pennies when building mass produced products; are modern low-power devices being used so values can be passed via parameters rather than via globals, or are they being used for applications where even less power is available?
One difference from 20 years ago is that embedded devices are more mainstream, easier to get hold of and sales opportunities abound. This availability creates an environment where developers with a desktop development mentality (which developers new to embedded always seem to have had) don’t get to learn about the overheads of parameter passing.
Have compilers gotten better at reducing the function parameter overhead? The most obvious optimization is inlining a function at the point of call. If the function is only called once, this works fine, with multiple calls the generated code can get larger (one of the things we are trying to avoid). I don’t have any reliable data on modern compiler performance int his area, but then I have not looked hard. Pointers to benchmarks welcome.
Does embedded software have any other signatures that differentiate it from desktop software (other than the obvious one of specifying address in definitions of global variables)? Suggestions welcome.
Fortran 2008 Standard has been updated
An updated version of ISO/IEC 1539-1 Information technology — Programming languages — Fortran — Part 1: Base language has just been published. So what has JTC1/SC22/WG5 been up to?
This latest document is bug a release of the 2010 standard, known as Fortran 2008 (because the ANSI Standard from which the ISO Standard was derived, sed -e "s/ANSI/ISO/g" -e "s/National/International/g", was published in 2008) and incorporates all the published corrigenda. I must have been busy in 2008, because I did not look to see what had changed.
Actually the document I am looking at is the British Standard. BSI don’t bother with sed, they just glue a BSI Standards Publication page on the front and add BS to the name, i.e., BS ISO/IEC 1539-1:2010.
The interesting stuff is in Annex B, “Deleted and obsolescent features” (the new features are Fortranized versions of languages features you have probable seen elsewhere).
Programming language committees are known for issuing dire warnings that various language features are obsolescent and likely to be removed in a future revision of the standard, but actually removing anything is another matter.
Well, the Fortran committee have gone and deleted six features! Why wasn’t this on the news? Did the committee foresee the 2008 financial crisis and decide to sneak out the deletions while people were looking elsewhere?
What constructs cannot now appear in conforming Fortran programs?
- “Real and double precision DO variables. .. A similar result can be achieved by using a DO construct with no loop control and the appropriate exit test.”
What other languages call a for-loop, Fortran calls a DO loop. So loop control variables can no longer have a floating-point type.
- “Branching to an END IF statement from outside its block.”
An if-statement is terminated by the token sequence
END IF, which may have an optional label. It is no longer possible toGOTOthat label from outside the block of the if-statement. You are going to have to label the statement after it. - “PAUSE statement.”
This statement dates from the days when a computer (singular, not plural) had its own air-conditioned room and a team of operators to tend its every need. A
PAUSEstatement would cause a message to appear on the operators’ console and somebody would be dispatched to check the printer was switched on and had paper, or some such thing, and they would then resume execution of the paused program.I think WG5 has not seen the future here. Isn’t the
PAUSEstatement needed again for cloud computing? I’m sure that Amazon would be happy to quote a price for having an operator respond to aPAUSEstatement. - “ASSIGN and assigned GO TO statements and assigned format specifiers.”
No more assigning labels to variables and GOTOing them, as a means of leaping around 1,000 line functions. This modern programming practice stuff is a real killjoy.
- “H edit descriptor.”
First programmers stopped using punched cards and now the H edit descriptor have been removed from Fortran; Herman Hollerith no longer touches the life of working programmers.
In the good old days real programmers wrote
11HHello World. Using quote delimiters for string literals is for pansies. - “Vertical format control. … There was no standard way to detect whether output to a unit resulted in this vertical format control, and no way to specify that it should be applied; this has been deleted. The effect can be achieved by post-processing a formatted file.”
Don’t panic, C still supports the
\vescape sequence.
Student projects for 2016/2017
This is the time of year when students have to come up with an idea for their degree project. I thought I would suggest a few interesting ideas related to software engineering.
- The rise and fall of software engineering myths. For many years a lot of people (incorrectly) believed that there existed a 25-to-1 performance gap between the best/worst software developers (its actually around 5 to 1). In 1999 Lutz Prechelt wrote a report explaining out how this myth came about (somebody misinterpreted values in two tables and this misinterpretation caught on to become the dominant meme).
Is the 25-to-1 myth still going strong or is it dying out? Can anything be done to replace it with something closer to reality?
One of the constants used in the COCOMO effort estimation model is badly wrong. Has anybody else noticed this?
- Software engineering papers often contain trivial mathematical mistakes; these can be caused by cut and paste errors or mistakenly using the values from one study in calculations for another study. Simply consistency checks can be used to catch a surprising number of mistakes, e.g., the quote “8 subjects aged between 18-25, average age 21.3” may be correct because 21.3*8 == 170.4, ages must add to a whole number and the values 169, 170 and 171 would not produce this average.
The Psychologies are already on the case of Content Mining Psychology Articles for Statistical Test Results and there is a tool, statcheck, for automating some of the checks.
What checks would be useful for software engineering papers? There are tools available for taking pdf files apart, e.g., qpdf, pdfgrep and extracting table contents.
- What bit manipulation algorithms does a program use? One way of finding out is to look at the hexadecimal literals in the source code. For instance, source containing
0x33333333,0x55555555,0x0F0F0F0Fand0x0000003Fin close proximity is likely to be counting the number of bits that are set, in a 32 bit value.Jörg Arndt has a great collection of bit twiddling algorithms from which hex values can be extracted. The numbers tool used a database of floating-point values to try and figure out what numeric algorithms source contains; I’m sure there are better algorithms for figuring this stuff out, given the available data.
Feel free to add suggestions in the comments.
Does public disclosure of vulnerabilities improve vendor response?
Does public disclosure of vulnerabilities in vendor products result in them releasing a fix more quickly, compared to when the vulnerability is only disclosed to the vendor (i.e., no public disclosure)?
A study by Arora, Krishnan, Telang and Yang investigated this question and made their data available 🙂 So what does the data have to say (its from the US National Vulnerability Database over the period 2001-2003)?
The plot below is a survival curve for disclosed vulnerabilities, the longer it takes to release a patch to fix a vulnerability, the longer it survives.
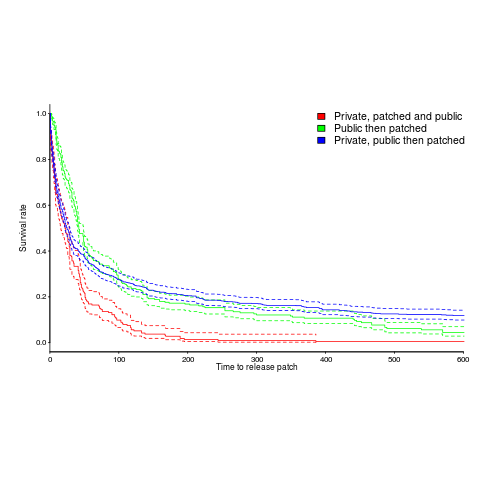
There is a popular belief that public disclosure puts pressure on vendors to release patchs more quickly, compared to when the public knows nothing about the problem. Yet, the survival curve above clearly shows publically disclosed vulnerabilities surviving longer than those only disclosed to the vendor. Is the popular belief wrong?
Digging around the data suggests a possible explanation for this pattern of behavior. Those vulnerabilities having the potential to cause severe nastiness tend not to be made public, but go down the path of private disclosure. Vendors prioritize those vulnerabilities most likely to cause the most trouble, leaving the less troublesome ones for another day.
This idea can be checked by building a regression model (assuming the necessary data is available and it is). In one way or another a lot of the data is censored (e.g., some reported vulnerabilities were not patched when the study finished); the Cox proportional hazards model can handle this (in fact, its the ‘standard’ technique to use for this kind of data).
This is a time dependent problem, some vulnerabilities start off being private and a public disclosure occurs before a patch is released, so there are some complications (see code+data for details). The first half of the output generated by R’s summary function, for the fitted model, is as follows:
Call:
coxph(formula = Surv(patch_days, !is_censored) ~ cluster(ID) +
priv_di * (log(cvss_score) + y2003 + log(cvss_score):y2002) +
opensource + y2003 + smallvendor + log(cvss_score):y2002,
data = ISR_split)
n= 2242, number of events= 2081
coef exp(coef) se(coef) robust se z Pr(>|z|)
priv_di 1.64451 5.17849 0.19398 0.17798 9.240 < 2e-16 ***
log(cvss_score) 0.26966 1.30952 0.06735 0.07286 3.701 0.000215 ***
y2003 1.03408 2.81253 0.07532 0.07889 13.108 < 2e-16 ***
opensource 0.21613 1.24127 0.05615 0.05866 3.685 0.000229 ***
smallvendor -0.21334 0.80788 0.05449 0.05371 -3.972 7.12e-05 ***
log(cvss_score):y2002 0.31875 1.37541 0.03561 0.03975 8.019 1.11e-15 ***
priv_di:log(cvss_score) -0.33790 0.71327 0.10545 0.09824 -3.439 0.000583 ***
priv_di:y2003 -1.38276 0.25089 0.12842 0.11833 -11.686 < 2e-16 ***
priv_di:log(cvss_score):y2002 -0.39845 0.67136 0.05927 0.05272 -7.558 4.09e-14 *** |
The explanatory variable we are interested in is priv_di, which takes the value 1 when the vulnerability is privately disclosed and 0 for public disclosure. The model coefficient for this variable appears at the top of the table and is impressively large (which is consistent with popular belief), but at the bottom of the table there are interactions with other variable and the coefficients are less than 1 (not consistent with popular belief). We are going to have to do some untangling.
cvss_score is a score, assigned by NIST, for the severity of vulnerabilities (larger is more severe).
The following is the component of the fitted equation of interest:
*(0.34+0.4*y2002)-1.4*y2003)}")
where:  is 0/1,
is 0/1, ") varies between 0.8 and 2.3 (mean value 1.8),
varies between 0.8 and 2.3 (mean value 1.8),  and
and  are 0/1 in their respective years.
are 0/1 in their respective years.
Applying hand waving to average away the variables:
)} right e^{{priv~di}(1.6-0.6-(0.7/3+1.4/3))} right e^{{priv~di}*0.3}")
gives a (hand waving mean) percentage increase of *100 right 35%") , when
, when priv_di changes from zero to one. This model is saying that, on average, patches for vulnerabilities that are privately disclosed take 35% longer to appear than when publically disclosed
The percentage change of patch delivery time for vulnerabilities with a low cvvs_score is around 90% and for a high cvvs_score is around 13% (i.e., patch time of vulnerabilities assigned a low priority improves a lot when they are publically disclosed, but patch time for those assigned a high priority is slightly improved).
I have not calculated 95% confidence bounds, they would be a bit over the top for the hand waving in the final part of the analysis. Also the general quality of the model is very poor; Rsquare= 0.148 is reported. A better model may change these percentages.
Has the situation changed in the 15 years since the data used for this analysis? If somebody wants to piece the necessary data together from the National Vulnerability Database, the code is ready to go (ok, some of the model variables may need updating).
Update: Just pushed a model with Rsquare= 0.231, showing a 63% longer patch time for private disclosure.
The wind is not yet blowing in software engineering research
An article by Andrew Gelman is getting a lot of well deserved publicity at the moment. The topic of discussion is sloppy research practices in psychology and how researchers are responding to criticism (head in the sand and blame the messenger).
I imagine that most software developers think this is an intrinsic problem in the ‘soft’ sciences that does not apply to the ‘hard’ sciences, such as software; I certainly thought this until around 2000 or so. Writing a book containing a detailed analysis of C convinced me that software engineering was mostly opinion, with a tiny smattering of knowledge in places.
The C book tried to apply results from cognitive psychology to what software developers do. After reading lots of books and papers on cognitive psychology I was impressed with how much more advanced, and rigorous, their experimental methods were, compared to software engineering.
Writing a book on empirical software engineering has moved my views on to the point where I think software engineering is the ideal topic for the academic fraudster.
The process of cleaning up their act that researchers in psychology are going through now is something that software engineering will have to go through. Researchers have not yet reached the stage of directly pointing out that software engineering research is a train wreck. Instead, they write parody papers and polite article showing how dirty popular datasets are.
Of course, industry is happy to keep quiet. The development of software systems is still a sellers market (the packaged market is dog eat dog) or at least that is still the prevalent mentality. I doubt anything much will change until the production of software systems becomes a buyers market, which will create a real incentive for finding out what really works.
Converting between IFPUG & COSMIC function point counts
Replication, repeating an experiment to confirm the results of previous experiments, is not a common activity in software engineering. Everybody wants to write about their own ideas and academic journals want to publish what is new (they are fashion driven).
Conversion between ways of counting function points, a software effort estimating technique, is one area where there has been a lot of replications (eight studies is a lot in software engineering, while a couple of hundred is a lot in psychology).
Amiri and Padmanabhuni’s Master’s thesis (yes, a thesis written by two people) lists data from 11 experiments where students/academics/professionals counted function points for a variety of projects using both the IFPUG and COSMIC counting methods. The data points are plotted below left and regression lines to each sample on the right (code+data):
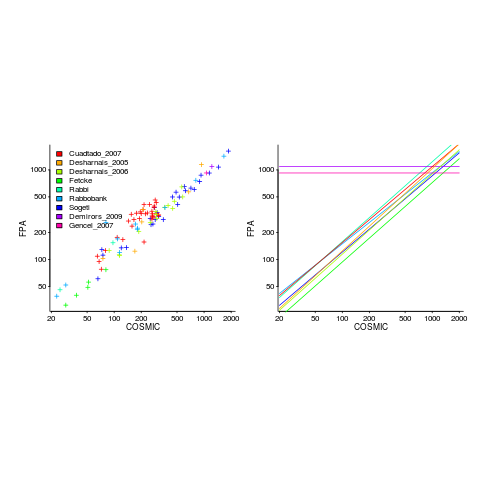
The horizontal lines are two very small samples where model fitting failed.
I was surprised to see such good agreement between different groups of counters. A study by Grimstad and Jørgensen asked developers to estimate effort (not using function points) for various projects, waited one month and repeated using what the developers thought were different projects. Most of the projects were different from the first batch, but a few were the same. The results showed developers giving completely different estimates for the same project! It looks like the effort invested in producing function point counting rules that give consistent answers and the training given to counters has paid off.
Two patterns are present in the regression lines:
- the slope of most lines is very similar, but they are offset from each other,
- the slope of some lines is obviously different from the others, with the different slopes all tilting further in the same direction. These cases mostly occur in the Cuadrado data (these three data sets are not included in the following analysis).
The kind of people doing the counting, for each set of measurements, is known and this information can be used to build a more sophisticated model.
Specifying a regression model to fit requires making several decisions about the kinds of uncertainty error present in the data. I have no experience with function points and in the following analysis I list the options and pick the one that looks reasonable to me. Please let me know if you have theory or data one suggesting what the right answer might be, I’m just juggling numbers here.
First we have to decide whether measurement error is additive or multiplicative. In other words, is there a fixed amount of potential error on each measurement, or is the amount of error proportional to the size of the project being measured (i.e., the error is a percentage of the total).
Does it make a difference to the fitted model? Sometimes it does and its always worthwhile to try building a model that mimics reality. If I tell you that  (Greek lower-case epsilon) is the symbol used to denote measurement error, you should be able to figure out which of the following two equations was built assuming additive/multiplicative error (confidence intervals have been omitted to keep things simple, they are given at the end of this post).
(Greek lower-case epsilon) is the symbol used to denote measurement error, you should be able to figure out which of the following two equations was built assuming additive/multiplicative error (confidence intervals have been omitted to keep things simple, they are given at the end of this post).
log(CFP)}*e^{0.81IFPi-0.6CFPi}*e^{0.24stu}+epsilon")
log(CFP)}*e^{0.83IFPi}*e^{0.29stu}*epsilon")
where:  is 0 when the IFPUG counting is done by academics and 1 when done by industry,
is 0 when the IFPUG counting is done by academics and 1 when done by industry,  is 0 when the COSMIC counting is done by academics and 1 when done by industry,
is 0 when the COSMIC counting is done by academics and 1 when done by industry,  is 1 when the counting was done by students and 0 otherwise.
is 1 when the counting was done by students and 0 otherwise.
I think that measurement error is multiplicative for his problem and the remaining discussion is based on this assumption. Everything after the first exponential can be treated as effectively a constant, say  , giving:
, giving:
log(CFP)}*K")
If we are only interested in converting counts performed by industry we get:

If we are using academic counters the equation is:

Next we have to decide where the uncertainty error resides. Nearly all forms of regression modeling assume that all the uncertainty resides in the response variable and that there is no uncertainty in the explanatory variables are measured without uncertainty. The idea is that the values of the explanatory variables are selected by the person doing the measurement, a handle gets turned and out pops the value of the response variable, plus error, for those particular, known, explanatory variable.
The measurements in this analysis were obtained by giving the subjects a known project specification, getting them to turn a handle and recording the function point count that popped out. So all function point counts contain uncertainty error.
Does the choice of response variable make that big a difference?
Let’s take the model fitted above and do some algebra to invert it, so that COSMIC is expressed in terms of IFPUG. We get the equation:

Now lets fit a model where the roles of response/explanatory variable are switched, we get:

For this problem we need to fit a model that includes uncertainty in both variables containing function point counts. There are techniques for building models from scratch, known as errors-in-variables models. I like the SIMEX approach because it integrates well with existing R functionality for building regression models.
To use the simex function, from the R simex package, I have to decide how much uncertainty (in the form of a value for standard deviation) is present in the explanatory variable (the COSMIC counts in this case). Without any knowledge to guide the choice, I decided that the amount of error in both sets of count measurements is the same (a standard deviation of 3%, please let me know if you have a better idea).
The fitted equation for a model containing uncertainty in both counts is (see code+data for model details):

If I am interested in converting IFPUG counts to COSMIC, then what is the connection between the above model and reality?
I’m guessing that those most likely to perform conversions are in industry. Does this mean we can delete the academic subexpressions from the model, or perhaps fit a model that excludes counts made by academics? Is the Cuadrado data sufficiently different to be treated as an outlier than should be excluded from the model building process, or is it representative of an industry usage that does not occur in the available data?
There are not many industry only counts in the combined data. Perhaps the academic counters are representative of counters in industry that happen not to be included in the samples. We could build a mixed-effects model, using all the data, to get some idea of the variation between different sets of counters.
The 95% confidence intervals for the fitted exponent coefficient, using this data, is around 8%. So in practice, some of the subtitles in the above analysis are lost in the noise. To get tighter confidence bounds more data is needed.
p-values in software engineering
Data relating to software engineering activities is starting to become common and the results of any statistical analysis of data will include something known as the p-value.
Most of the time having a p-value below some cut-off value is a good thing, but sometimes good things occur when the value is above the cut-off (see p-values for programmers for details about what the p-value is).
A commonly encountered cut-off value is 0.05 (sometimes written as 5%).
Where did this 0.05 come from? It was first proposed in 1920s by Ronald Fisher. Fisher’s Statistical Methods for Research Workers and later Statistical Tables for Biological, Agricultural, and Medical Research had a huge impact and a p-value cut-off of 0.05 became enshrined as the magic number.
To quote Fisher: “Either there is something in the treatment, or a coincidence has occurred such as does not occur more than once in twenty trials.”
Once in twenty was a reasonable level for an event occurring by chance (rather than as a result of some new fertilizer or drug) in an experiment in biological, agricultural or medical research in 1900s. Is it a reasonable level for chance events in software engineering?
A one in twenty chance of a new technique resulting in a building falling down would not be considered acceptable in civil engineering. In high energy physics a p-value of  is used to decide whether a new particle has been discovered (or not).
is used to decide whether a new particle has been discovered (or not).
In business p-values should be treated as part of cost/benefit analysis. How confident are we that this effect is for real, how much would it cost to be right or wrong about it? Using a cut-off value to make yes/no decisions (e.g., 0.049 yes, 0.051 no) is very simplistic decision making.
To get a paper published in a software engineering journal requires any data analysis to have p-values below 0.05. In this regard the editors are aping journals in the social sciences; in fact the high impact social science journals require p-values below 0.01 (the high impact journals receive more submissions and can afford to be choosier about what they publish).
What is a sensible choice for a p-value cur-off in software engineering journals? The simple answer is: As low as possible, given the need to accept  papers per month for publication. A more complicated answer would involve different cut-offs for different kinds of measurements, e.g., measuring people or measuring code.
papers per month for publication. A more complicated answer would involve different cut-offs for different kinds of measurements, e.g., measuring people or measuring code.
While the p-value attracts plenty of criticism, there is nothing wrong with p-values. Use of p-values has a dominant market position in statistics and they are frequently misused by the clueless and those wanting to mislead their audience. Any other technique is just as likely to be misused, if not more so.
The killer phrase associated with p-values is “statistically significant”, often abbreviated to just “significant”. How people love to describe the results of their measurements as being shown to be “significant”. Of course, I am free to choose whatever p-value cut-off I like for my experiments and then claim the results are significant. I have had researchers repeatedly tell me that their results were “significant”, every time I asked them about p-values; a serious red flag.
When dealing with statistical results, ask yourself what the reported p-values mean to you. Don’t accept the 0.05 is the cut-off that everybody uses nonsense. If the research won’t reveal actual p-values, walk away from the snake oil.
Software engineering data sets
The pretty pictures from my empirical software engineering book are now online, along with the 210 data sets and R code (330M).
Plotting the number of data sets in each year shows that empirical software engineering has really taken off in the last 10 years (code+data). Around dozen or so confidential data sets are not included; I am only writing about data that can be made public.
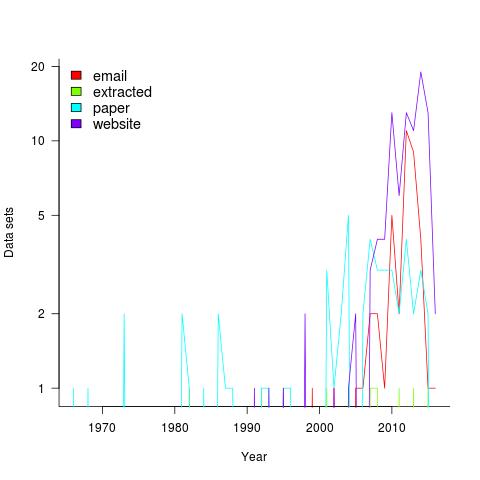
It used to be rare to find the data associated with a paper on the author’s website. Of course, before around 1995 there was no web, but since around 2012 the idea has started to take off.
Contact via email goes back to 1985 and before that people sent mag tapes through the post and many years ago somebody sent me punched tape (there is nothing like seeing the bits with the naked eye).
I have sent several hundred emails asking for data and received 55 data sets. I’m hoping this release will spur those who have promised me data to invest some time to send it.
My experience is that research data often lives on laptops and dies when the laptop is replaced (a study of biologists, who have been collecting data for hundreds of years, found a data ‘death rate’ of 17% a year). Had I started actively collecting data before 2010 the red line in the plot would be much higher for earlier years; I often received data from authors when writing my C book at the start of the century (Google went from nothing to being the best place to search, while I wrote).
In nine cases I extracted the data, either from the pdf or an image and then reverse engineered values.
I have around 50 data sets waiting to be processed. Given that lots more are bound to arrive before the book is finished, I expect to easily reach the 300 mark. A tiny number given my aim of writing about all software engineering issues for which public data exists.
If you know of interesting software engineering data, that is not to be found in these plots, please let me know.
Recent Comments