Plotting artifacts when the axis involves lines of code
While reading a report from the very late Rome period, the plot below caught my attention (the regression line was not in the original plot). The points follow a general trend, suggesting that when implementing a module, lines of code written per man-hour increases as the size of the module increases (in LOC). There are explanations for such behavior: perhaps module implementation time is mostly think-time that is independent of LOC, or perhaps larger modules contain more lines that can be quickly implemented (code+data).
Then I realised that the pattern of points was generated by a mathematical artifact. Can you spot the artifact?
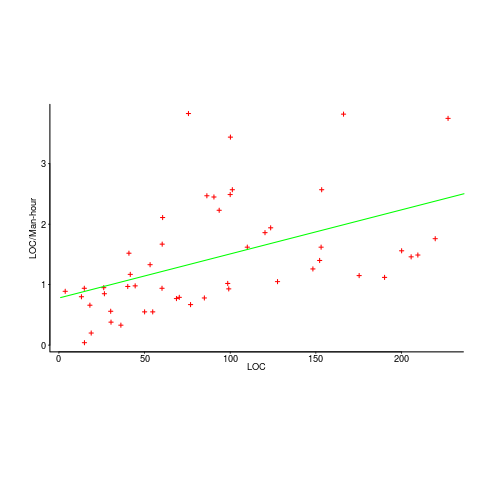
The x-axis shows LOC, and the y-axis shows LOC/man-hour. Just plotting LOC against LOC would produce a row of points along a straight line, and if we treat dividing by man-hours as roughly equivalent to dividing by a random number (which might have some correlation with LOC), the result is points scattered around a line going up to the right.
If LOC-per-hour were constant, the points would form a horizontal line across the plot.
In the below left plot, from a different report (whose axis are function-points, and function-points implemented per month), the author has fitted a line, and it is close to horizontal (suggesting that the mean FP-per-month is constant).
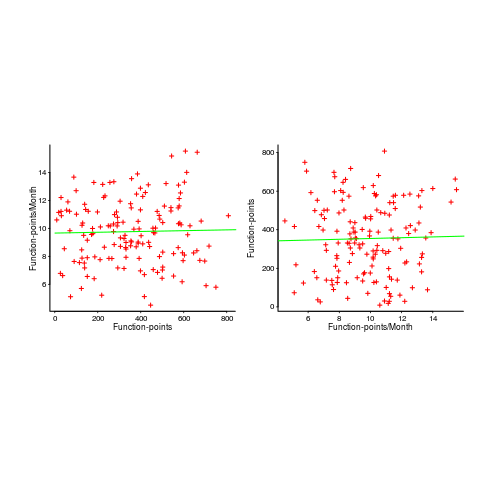
In fact the points are essentially random, and the line is a terrible fit (just how terrible is shown by switching the axis and refitting the line, above right; the refitted line should be vertical, but is horizontal. There is no connection between FP and FP-per-month, which is a good thing because the creators of function-points intended this to be true).
What process might generate this random scattering, rather than the trend seen in the first plot? If the implementation time was proportional to both the number of FP and some uniform random component, then the FP/time ratio would have the pattern seen.
The plots below show module size (in LOC) against man-hour (left) and FP against months (right):
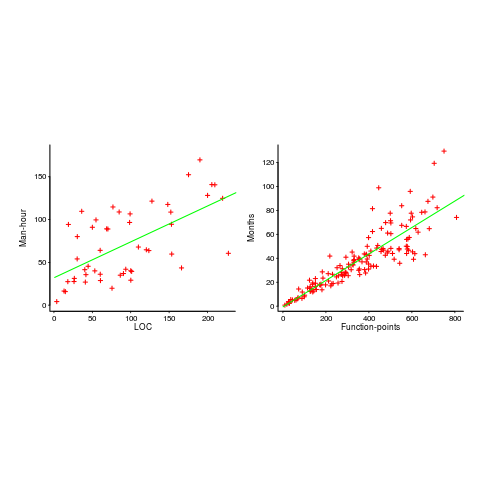
The module-LOC points are all over the place, while the FP points look as-if they are roughly consistent. Perhaps the module-LOC measurements came from a wide variety of sources, and we should not expect a visually pleasant trend.
Plotting LOC against LOC appears in other guises. Perhaps the most common being plotting fault-density against LOC; fault-density is generally calculated as faults/LOC.
Of course the artifacts also occur when plotting other kinds of measurements. Lines of code happens to be a commonly plotted quantity (at least in software engineering).
Team DNA-impersonators create a business plan
This weekend I was at the Hack the Police hackthon, sponsored by the Metropolitan Police+other organizations. My plan was to find an interesting problem to help solve, using the data we were told would be available. My previous experience with crime data is that there is not enough of it to allow reliable models to be built, this is a good thing in that nobody wants lots of crime. Talking to a Police intelligence officer, the publicly available data contained crimes (i.e., a court case had found somebody guilty), not reported incidents, and was not large enough to build allow a good model to be built.
Looking for a team to join, I got talking to Joe and Rebecca. Joe had discovered a very interesting possible threat to the existing DNA matching technique, and they were happy for me to join them analyzing this threat model; team DNA-impersonators was go.
Some background (Joe and Rebecca are the team’s genetic experts, I’m a software guy who has read a few books on the subject; all the mistakes in this post are mine). The DNA matching technique used by the Police is based on 17 specific sequences (each around 100 bases, known as loci), within the human genome (which contains around 3 billion bases).
There are companies who synthesize sequences of DNA to order. I knew that machines for doing this existed, but I did not know it was possible to order a bespoke sequence online, and how inexpensive it was.
Some people have had their DNA sequenced, and have allowed it to be published online; Steven Pinker is the most famous person I could find, whose DNA sequence is available online (link not given; it requires work+luck to find). The Personal Genome Projects aims to sequence and make available the complete genomes of 100,000 volunteers (the UK arm of this project is on hold because of lack of funding; master criminals in the UK have a window of opportunity: offer to sponsor the project on condition that their DNA is included in the public data set).
How much would it cost to manufacture bottles of spray-on Steven Pinker DNA? Is there a viable business model selling Pinker No. 5?
The screenshot below shows a quote for 2-nmol of DNA for the sequence of 100 bases that are one of the 17 loci used in DNA matching. This order is for concentrated DNA, and needs to be diluted to the level likely to be found as residue at a crime scene. Joe calculated that 2-nmol can be diluted to produce 60-liters of usable ‘product’.
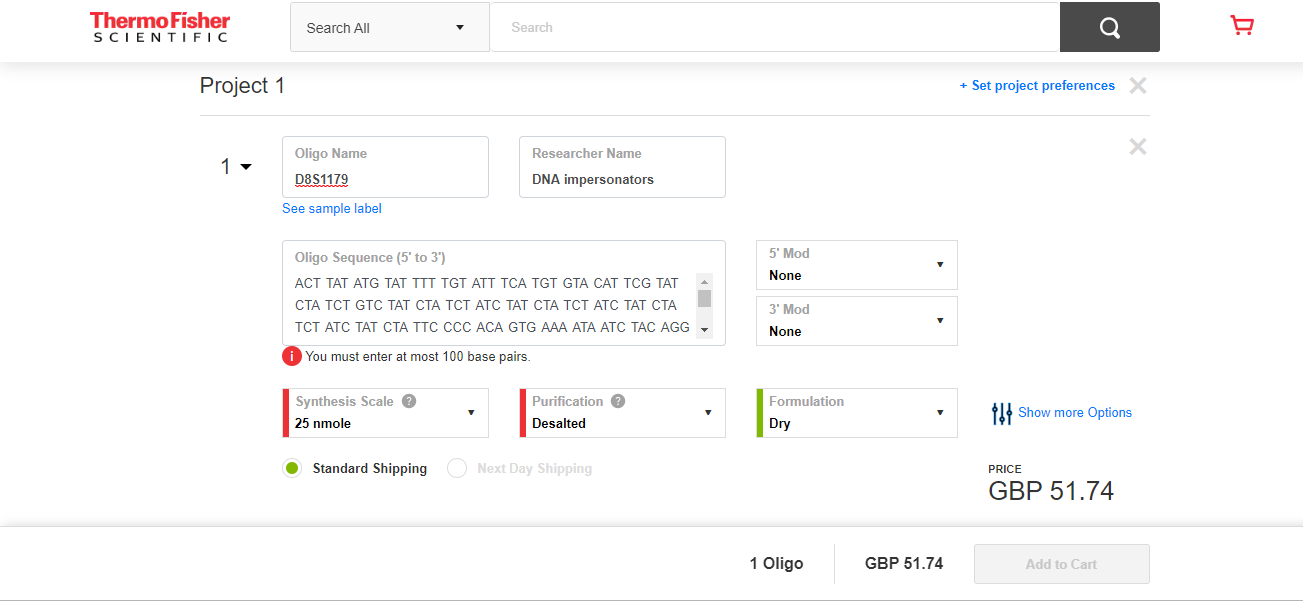
There was not enough time to obtain sequences for the other 16-loci, and get quotes for them. Information on the 17-loci used for DNA matching is available in research papers; a summer job for a PhD student to sort out the details.
The concentrate from the 17-loci dilutes to 60-liters. Say each spray-on bottle contains 100ml, then an investment of £800 (plus researcher time) generates enough liquid for 600-bottles of Pinker No. 5.
What is the pricing model? Is there a mass market (e.g., Hong Kong protesters wanting to be anonymous), or would it be more profitable to target a few select clients? Perhaps Steven Pinker always wanted to try his hand at safe-cracking in his spare time, but was worried about leaving DNA evidence behind; he might be willing to pay to have the market flooded, so Pinker No. 5 residue becomes a common occurrence at crime scenes (allowing him to plausible claim that any crime scene DNA matches were left behind by other people).
Some of the police officers at the hack volunteered that they knew lots of potential customers; the forensics officer present was horrified.
Before the 1980s, DNA profiling was not available. Will the 2020s be the decade in which DNA profiling ceases being a viable tool for catching competent criminals?
High quality photocopiers manufacturers are required to implement features that make it difficult for people to create good quality copies of paper currency.
What might law enforcement do about this threat to the viability of DNA profiling?
Ideas include:
- Requiring companies in the bespoke DNA business to report suspicious orders. What is a suspicious order? Are enough companies in business to make it possible to order each of the 17-loci from a different company (we think so)?
- Introducing laws making it illegal to be in possession of diluted forms of other people’s DNA (with provisions for legitimate uses).
- Attacking the economics of the Pinker No. 5 business model by having more than 17-loci available for use in DNA matching. Perhaps 1,000 loci could be selected as potential match sites, with individual DNA testing kits randomly testing 17 (or more) from this set.
Natural elimination, or the survival of the good enough
Thanks to Darwin, the world is full of people who think that evolution, in nature, works by: natural selection, or the survival of the fittest. I thought this until I read “Good Enough: The Tolerance for Mediocrity in Nature and Society” by Daniel Milo.
Milo makes a very convincing case that nature actually works by: natural elimination, or the survival of the good enough.
Why might Darwin have gone with natural selection in his book, On the Origin of Species? Milo makes the point that the only real evidence that Darwin had to work with was artificial selection, that is the breeding of farm animals and domestic pets to select for traits that humans found desirable. Darwin’s visit to the Galápagos islands triggered a way of thinking, it did not provide him with the evidence he needed; Darwin’s Finches have become a commonly cited example of natural selection at work, but while Darwin made the observations it was not until 80 years later that somebody else spotted their relevance.
The Origin of Species, or to use its full title: “On the Origin of Species by means of natural selection, or the preservation of favored races in the struggle for life.” is full of examples and terminology relating to artificial selection.
Natural selection, or natural elimination, isn’t the result the same?
Natural selection implies an optimization process, e.g., breeders selecting for a strain of cows that produce the most milk.
Natural elimination is a good enough process, i.e., a creature needs a collection of traits that are good enough for them to create the next generation.
A long-standing problem with natural selection is that it fails to explain the diversity present in a natural population of some breed of animal (there is very little diversity in each breed of farm animal, they have been optimized for consistency). Diversity is not a problem for natural elimination, which does not reduce differences in its search for fitness.
The diversity produced as a consequence of natural elimination creates a population containing many neutral traits (i.e., characteristics that have no positive or negative impact on continuing survival). When a significant change in the environment occurs, one or more of the neutral traits may suddenly have positive or negative survival consequences; the creatures with the positive traits have opportunity time to adapt to the changed environment. A population whose members possess a diverse range of neutral traits has a higher chance of long-term survival than a population where diversity has been squeezed in the quest for the fittest.
I think that natural elimination also applies within software ecosystems. Commercial products survive if enough customers buy them, software developers need good enough know-how to get the job done.
I’m sure customers would prefer software ecosystems to operate on the principle of survival of the fittest (it reduces their costs). Over the long term is society best served by diverse software ecosystems or softwaremonocultures? Diversity is a way of encouraging competition, but over time there is diminishing returns on the improvements.
Ecosystems chapter of “evidence-based software engineering” reworked
The Ecosystems chapter of my evidence-based software engineering book has been reworked (I have given up on the idea that this second pass is also where the polishing happens; polishing still needs to happen, and there might be more material migration between chapters); download here.
I have been reading books on biological ecosystems, and a few on social ecosystems. These contain lots of interesting ideas, but the problem is, software ecosystems are just very different, e.g., replication costs are effectively zero, source code does not replicate itself (and is not self-evolving; evolution happens because people change it), and resources are exchanged rather than flowing (e.g., people make deals, they don’t get eaten for lunch). Lots of caution is needed when applying ecosystem related theories from biology, the underlying assumptions probably don’t hold.
There is a surprising amount of discussion on the computing world as it was many decades ago. This is because ecosystem evolution is path dependent; understanding where we are today requires knowing something about what things were like in the past. Computer memory capacity used to be a big thing (because it was often measured in kilobytes); memory does not get much publicity because the major cpu vendor (Intel) spends a small fortune on telling people that the processor is the most important component inside a computer.
There are a huge variety of software ecosystems, but you would not know this after reading the ecosystems chapter. This is because the work of most researchers has been focused on what used to be called the desktop market, which over the last few years the focus has been shifting to mobile. There is not much software engineering research focusing on embedded systems (a vast market), or supercomputers (a small market, with lots of money), or mainframes (yes, this market is still going strong). As the author of an evidence-based book, I have to go where the data takes me; no data, then I don’t have anything to say.
Empirical research (as it’s known in academia) needs data, and the ‘easy’ to get data is what most researchers use. For instance, researchers analyzing invention and innovation invariably use data on patents granted, because this data is readily available (plus everybody else uses it). For empirical research on software ecosystems, the readily available data are package repositories and the Google/Apple Apps stores (which is what everybody uses).
The major software ecosystems barely mentioned by researchers are the customer ecosystem (the people who pay for everything), the vendors (the companies in the software business) and the developer ecosystem (the people who do the work).
Next, the Projects chapter.
Compiler validation used to be a big thing
Compiler validation used to be a big thing; a NIST quarterly validated products list could run to nearly 150 pages, and approaching 1,000 products (not all were compilers).
Why did compiler validation stop being a thing?
Running a compiler validation service (NIST was also involved with POSIX, graphics, and computer security protocols validation) costs money. If there are enough people willing to pay (NIST charged for the validation service), the service pays for itself.
The 1990s was a period of consolidation, lots of computer manufacturers went out of business and Micro Focus grew to dominate the Cobol compiler business. The number of companies willing to pay for validation fell below the number needed to maintain the service; the service was terminated in 1998.
The source code of the Cobol, Fortran and SQL + others tests that vendors had to pass (to appear for 12 months in the validated products list) is still available; the C validation suite costs money. But passing these tests, then paying NIST’s fee for somebody to turn up and watch the compiler pass the tests, no longer gets your product’s name in lights (or on the validated products list).
At the time, those involved lamented the demise of compiler validation. However, compiler validation was only needed because many vendors failed to implement parts of the language standard, or implemented them differently. In many ways, reducing the number of vendors is a more effective means of ensuring consistent compiler behavior. Compiler monoculture may spell doom for those in the compiler business (and language standards), but is desirable from the developers’ perspective.
How do we know whether today’s compilers implement the requirements contained in the corresponding ISO language standard? You could argue that this is a pointless question, i.e., gcc and llvm are the language standard; but let’s pretend this is not the case.
Fuzzing is good for testing code generation. Checking language semantics still requires expert human effort, and lots of it. People have to extract the requirements contained in the language specification, and write code that checks whether the required behavior is implemented. As far as I know, there are only commercial groups doing this, i.e., nothing in the open source world; pointers welcome.
Converting lines in an svg image to csv
During a search for data on programming language usage I discovered Stack Overflow Trends, showing an interesting plot of language tags appearing on Stack Overflow questions (see below). Where was the csv file for these numbers? Somebody had asked this question last year, but there were no answers.

The graphic is in svg format; has anybody written an svg to csv conversion tool? I could only find conversion tools for specialist uses, e.g., geographical data processing. The svg file format is all xml, and using a text editor I could see the numbers I was after. How hard could it be (it had to be easier than a png heatmap)?
Extracting the x/y coordinates of the line segments for each language turned out to be straight forward (after some trial and error). The svg generation process made matching language to line trivial; the language name was included as an xml attribute.
Programmatically extracting the x/y axis information exhausted my patience, and I hard coded the numbers (code+data). The process involves walking an xml structure and R’s list processing, two pet hates of mine (the data is for a book that uses R, so I try to do everything data related in R).
I used R’s xml2 package to read the svg files. Perhaps if my mind had a better fit to xml and R lists, I would have been able to do everything using just the functions in this package. My aim was always to get far enough down to convert the subtree to a data frame.
Extracting data from graphs represented in svg files is so easy (says he). Where is the wonderful conversion tool that my search failed to locate? Pointers welcome.
My book’s pdf generation workflow
The process used to generate the pdf of my evidence-based software engineering book has been on my list of things to blog about, for ever. An email arrived this afternoon, asking how I produced various effects using Asciidoc; this post probably contains rather more than N. Psaris wanted to know.
It’s very easy to get sucked into fiddling around with page layout and different effects. So, unless I am about to make a release of a draft, I only generate a pdf once, at the end of each month.
At the end of the month the text is spell checked using aspell, and then grammar checked using Language tool. I have an awk script that checks the text for mistakes I have made in the past; this rarely matches, i.e., I seem to be forever making different mistakes.
The sequencing of tools is: R (Sweave) -> Asciidoc -> docbook -> LaTeX -> pdf; assorted scripts fiddle with the text between outputs and inputs. The scripts and files mention below are available for download.
R generates pdf files (via calls to the Sweave function, I have never gotten around to investigating Knitr; the pdfs are cropped using scripts/pdfcrop.sh) and the ascii package is used to produce a few tables with Asciidoc markup.
Asciidoc is the markup language used for writing the text. A few years after I started writing the book, Stuart Rackham, the creator of Asciidoc, decided to move on from working and supporting it. Unfortunately nobody stepped forward to take over the project; not a problem, Asciidoc just works (somebody did step forward to reimplement the functionality in Ruby; Asciidoctor has an active community, but there is no incentive for me to change). In my case, the output from Asciidoc is xml (it supports a variety of formats).
Docbook appears in the sequence because Asciidoc uses it to produce LaTeX. Docbook takes xml as input, and generates LaTeX as output. Back in the day, Docbook was hailed as the solution to all our publishing needs, and wonderful tools were going to be created to enable people to produce great looking documents.
LaTeX is the obvious tool for anybody wanting to produce lovely looking books and articles; tex/ESEUR.tex is the top-level LaTeX, which includes the generated text. Yes, LaTeX is a markup language, and I could have written the text using it. As a language I find LaTeX too low level. My requirements are not complicated, and I find it easier to write using a markup language like Asciidoc.
The input to Asciidoc and LuaTeX (used to generate pdf from LaTeX) is preprocessed by scripts (written using sed and awk; see scripts/mkpdf). These scripts implement functionality that Asciidoc does not support (or at least I could see how to do it without modifying the Python source). Scripts are a simple way of providing the extra functionality, that does not require me to remember details about the internals of Asciidoc. If Asciidoc was being actively maintained, I would probably have worked to get some of the functionality integrated into a future release.
There are a few techniques for keeping text processing scripts simple. For instance, the cost of a pass over text is tiny, there is little to be gained by trying to do everything in one pass; handling the possibility that markup spans multiple lines can be complicated, a simple solution is to join consecutive lines together if there is a possibility that markup spans these lines (i.e., the actual matching and conversion no longer has to worry about line breaks).
Many simple features are implemented by a script modifying Asciidoc text to include some ‘magic’ sequence of characters, which is subsequently matched and converted in the generated LaTeX, e.g., special characters, and hyperlinks in the pdf.
A more complicated example handles my desire to specify that a figure appear in the margin; the LaTeX sidenotes package supports figures in margins, but Asciidoc has no way of specifying this behavior. The solution was to add the word “Margin”, to the appropriate figure caption option (in the original Asciidoc text, e.g., [caption="Margin ", label=CSD-95-887]), and have a script modify the LaTeX generated by docbook so that figures containing “Margin” in the caption invoked the appropriate macro from the sidenotes package.
There are still formatting issues waiting to be solved. For instance, some tables are narrow enough to fit in the margin, but I have not found a way of embedding this information in the table information that survives through to the generated LaTeX.
My long time pet hate is the formatting used by R’s plot function for exponentiated values as axis labels. My target audience are likely to be casual users of R, so I am sticking with basic plotting (i.e., no calls to ggplot). I do wish the core R team would integrate the code from the magicaxis package, to bring the printing of axis values into the era of laser printers and bit-mapped displays.
Ideas and suggestions welcome.
Growth and survival of gcc options and processor support
Like any actively maintained software, compilers get more complicated over time. Languages are still evolving, and options are added to control the support for features. New code optimizations are added, which don’t always work perfectly, and options are added to enable/disable them. New ways of combining object code and libraries are invented, and new options are added to allow the desired combination to be selected.
The web pages summarizing the options for gcc, for the 96 versions between 2.95.2 and 9.1 have a consistent format; which means they are easily scrapped. The following plot shows the number of options relating to various components of the compiler, for these versions (code+data):
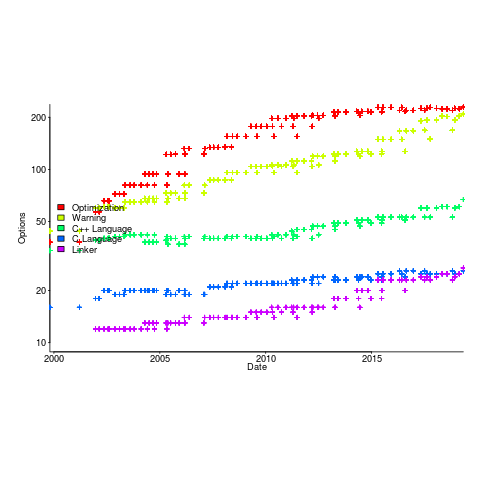
The total number of options grew from 632 to 2,477. The number of new optimizations, or at least the options supporting them, appears to be leveling off, but the number of new warnings continues to increase (ah, the good ol’ days, when -Wall covered everything).
The last phase of a compiler is code generation, and production compilers are generally structured to enable new processors to be supported by plugging in an appropriate code generator; since version 2.95.2, gcc has supported 80 code generators.
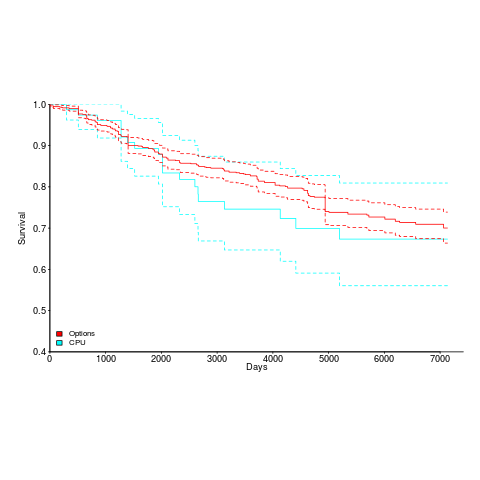
What can be added can be removed. The plot below shows the survival curve of gcc support for processors (80 supported cpus, with support for 20 removed up to release 9.1), and non-processor specific options (there have been 1,091 such options, with 214 removed up to release 9.1); the dotted lines are 95% confidence internals.
First language taught to undergraduates in the 1990s
The average new graduate is likely to do more programming during the first month of a software engineering job, than they did during a year as an undergraduate. Programming courses for undergraduates is really about filtering out those who cannot code.
Long, long ago, when I had some connection to undergraduate hiring, around 70-80% of those interviewed for a programming job could not write a simple 10-20 line program; I’m told that this is still true today. Fluency in any language (computer or human) takes practice, and the typical undergraduate gets very little practice (there is no reason why they should, there are lots of activities on offer to students and programming fluency is not needed to get a degree).
There is lots of academic discussion around which language students should learn first, and what languages they should be exposed to. I have always been baffled by the idea that there was much to be gained by spending time teaching students multiple languages, when most of them barely grasp the primary course language. When I was at school the idea behind the trendy new maths curriculum was to teach concepts, rather than rote learning (such as algebra; yes, rote learning of the rules of algebra); the concept of number-base was considered to be a worthwhile concept and us kids were taught this concept by having the class convert values back and forth, such as base-10 numbers to base-5 (base-2 was rarely used in examples). Those of us who were good at maths instantly figured it out, while everybody else was completely confused (including some teachers).
My view is that there is no major teaching/learning impact on the choice of first language; it is all about academic fashion and marketing to students. Those who have the ability to program will just pick it up, and everybody else will flounder and do their best to stay away from it.
Richard Reid was interested in knowing which languages were being used to teach introductory programming to computer science and information systems majors. Starting in 1992, he contacted universities roughly twice a year, asking about the language(s) used to teach introductory programming. The Reid list (as it became known), was regularly updated until Reid retired in 1999 (the average number of universities included in the list was over 400); one of Reid’s ex-students, Frances VanScoy, took over until 2006.
The plot below is from 1992 to 2002, and shows languages in the top with more than 3% usage in any year (code+data):
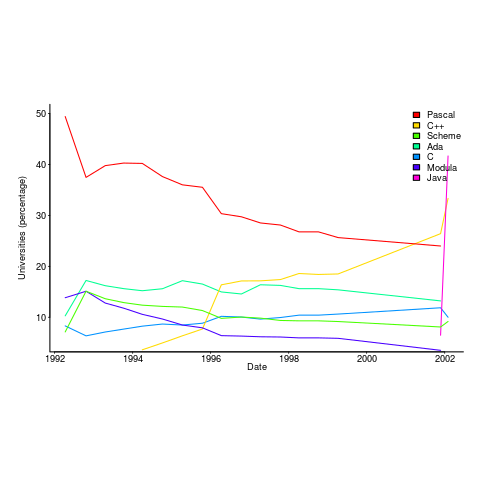
Looking at the list again reminded me how widespread Pascal was as a teaching language. Modula-2 was the language that Niklaus Wirth designed as the successor of Pascal, and Ada was intended to be the grown up Pascal.
While there is plenty of discussion about which language to teach first, doing this teaching is a low status activity (there is more fun to be had with the material taught to the final year students). One consequence is lack of any real incentive for spending time changing the course (e.g., using a new language). The Open University continued teaching Pascal for years, because material had been printed and had to be used up.
C++ took a while to take-off because of its association with C (which was very out of fashion in academia), and Java was still too new to risk exposing to impressionable first-years.
A count of the total number of languages listed, between 1992 and 2002, contains a few that might not be familiar to readers.
Ada Ada/Pascal Beta Blue C
1087 1 10 3 667
C/Java C/Scheme C++ C++/Pascal Eiffel
1 1 910 1 29
Fortran Haskell HyperTalk ISETL ISETL/C
133 12 2 30 1
Java Java/Haskell Miranda ML ML/Java
107 1 48 16 1
Modula-2 Modula-3 Oberon Oberon-2 ObjPascal
727 24 26 7 22
Orwell Pascal Pascal/C Prolog Scheme
12 2269 1 12 752
Scheme/ML Scheme/Turing Simula Smalltalk SML
1 1 14 33 88
Turing Visual-Basic
71 3 |
I had never heard of Orwell, a vanity language foisted on Oxford Mathematics and Computation students. It used to be common for someone in computing departments to foist their vanity language on students; it enabled them to claim the language was being used and stoked their ego. Is there some law that enables students to sue for damages?
The 1990s was still in the shadow of the 1980s fashion for functional programming (which came back into fashion a few years ago). Miranda was an attempt to commercialize a functional language compiler, with Haskell being an open source reaction.
I was surprised that Turing was so widely taught. More to do with the stature of where it came from (university of Toronto), than anything else.
Fortran was my first language, and is still widely used where high performance floating-point is required.
ISETL is a very interesting language from the 1960s that never really attracted much attention outside of New York. I suspect that Blue is BlueJ, a Java IDE targeting novices.
Want to be the coauthor of a prestigious book? Send me your bid
The corruption that pervades the academic publishing system has become more public.
There is now a website that makes use of an ingenious technique for helping people increase their paper count (as might be expected, the competitive China thought of it first). Want to be listed as the first author of a paper? Fees start at $500. The beauty of the scheme is that the papers have already been accepted by a journal for publication, so the buyer knows exactly what they are getting. Paying to be included as an author before the paper is accepted incurs the risk that the paper might not be accepted.
Measurement of academic performance is based on number of papers published, weighted by the impact factor of the journal in which they are published. Individuals seeking promotion and research funding need an appropriately high publication score; the ranking of university departments is based on the publications of its members. The phrase publish or perish aptly describes the process. As expected, with individual careers and departmental funding on the line, the system has become corrupt in all kinds of ways.
There are organizations who will publish your paper for a fee, 100% guaranteed, and you can even attend a scam conference (that’s not how the organizers describe them). Problem is, word gets around and the weighting given to publishing in such journals is very low (or it should be, not all of them get caught).
The horror being expressed at this practice is driven by the fact that money is changing hands. Adding a colleague as an author (on the basis that they will return the favor later) is accepted practice; tacking your supervisors name on to the end of the list of authors is standard practice, irrespective of any contribution that might have made (how else would a professor accumulate 100+ published papers).
I regularly receive emails from academics telling me they would like to work on this or that with me. If they look like proper researchers, I am respectful; if they look like an academic paper mill, my reply points out (subtly or otherwise) that their work is not of high enough standard to be relevant to industry. Perhaps I should send them a quote for having their name appear on a paper written by me (I don’t publish in academic journals, so such a paper is unlikely to have much value in the system they operate within); it sounds worth doing just for the shocked response.
I read lots of papers, and usually ignore the list of authors. If it looks like there is some interesting data associated with the work, I email the first author, and will only include the other authors in the email if I am looking to do a bit of marketing for my book or the paper is many years old (so the first author is less likely to have the data).
I continue to be amazed at the number of people who continue to strive to do proper research in this academic environment.
I wonder how much I might get by auctioning off the coauthoship of my software engineering book?
Recent Comments