2019 in the programming language standards’ world
Last Tuesday I was at the British Standards Institute for a meeting of IST/5, the committee responsible for programming language standards in the UK.
There has been progress on a few issues discussed last year, and one interesting point came up.
It is starting to look as if there might be another iteration of the Cobol Standard. A handful of people, in various countries, have started to nibble around the edges of various new (in the Cobol sense) features. No, the INCITS Cobol committee (the people who used to do all the heavy lifting) has not been reformed; the work now appears to be driven by people who cannot let go of their involvement in Cobol standards.
ISO/IEC 23360-1:2006, the ISO version of the Linux Base Standard, has been updated and we were asked for a UK position on the document being published. Abstain seemed to be the only sensible option.
Our WG20 representative reported that the ongoing debate over pile of poo emoji has crossed the chasm (he did not exactly phrase it like that). Vendors want to have the freedom to specify code-points for use with their own emoji, e.g., pineapple emoji. The heady days, of a few short years ago, when an encoding for all the world’s character symbols seemed possible, have become a distant memory (the number of unhandled logographs on ancient pots and clay tablets was declining rapidly). Who could have predicted that the dream of a complete encoding of the symbols used by all the world’s languages would be dashed by pile of poo emoji?
The interesting news is from WG9. The document intended to become the Ada20 standard was due to enter the voting process in June, i.e., the committee considered it done. At the end of April the main Ada compiler vendor asked for the schedule to be slipped by a year or two, to enable them to get some implementation experience with the new features; oops. I have been predicting that in the future language ‘standards’ will be decided by the main compiler vendors, and the future is finally starting to arrive. What is the incentive for the GNAT compiler people to pay any attention to proposals written by a bunch of non-customers (ok, some of them might work for customers)? One answer is that Ada users tend to be large bureaucratic organizations (e.g., the DOD), who like to follow standards, and might fund GNAT to implement the new document (perhaps this delay by GNAT is all about funding, or lack thereof).
Right on cue, C++ users have started to notice that C++20’s added support for a system header with the name version, which conflicts with much existing practice of using a file called version to contain versioning information; a problem if the header search path used the compiler includes a project’s top-level directory (which is where the versioning file version often sits). So the WG21 committee decides on what it thinks is a good idea, implementors implement it, and users complain; implementors now have a good reason to not follow a requirement in the standard, to keep users happy. Will WG21 be apologetic, or get all high and mighty; we will have to wait and see.
Complexity is a source of income in open source ecosystems
I am someone who regularly uses R, and my interest in programming languages means that on a semi-regular basis spend time reading blog posts about the language. Over the last year, or so, I had noticed several patterns of behavior, and after reading a recent blog post things started to make sense (the blog post gets a lot of things wrong, but more of that later).
What are the patterns that have caught my attention?
Some background: Hadley Wickham is the guy behind some very useful R packages. Hadley was an academic, and is now the chief scientist at RStudio, the company behind the R language specific IDE of the same name. As Hadley’s thinking about how to manipulate data has evolved, he has created new packages, and has been very prolific. The term Hadley-verse was coined to describe an approach to data manipulation and program structuring, based around use of packages written by the man.
For the last nine-months I have noticed that the term Tidyverse is being used more regularly to describe what had been the Hadley-verse. And???
Another thing that has become very noticeable, over the last six-months, is the extent to which a wide range of packages now have dependencies on packages in the HadleyTidyverse. And???
A recent post by Norman Matloff complains about the Tidyverse’s complexity (and about the consistency between its packages; which I had always thought was a good design principle), and how RStudio’s promotion of the Tidyverse could result in it becoming the dominant R world view. Matloff has an academic world view and misses what is going on.
RStudio, the company, need to sell their services (their IDE is clunky and will be wiped out if a top of the range product, such as Jetbrains, adds support for R). If R were simple to use, companies would have less need to hire external experts. A widely used complicated library of packages is a god-send for a company looking to sell R services.
I don’t think Hadley Wickam intentionally made things complicated, any more than the creators of the Microsoft server protocols added interdependencies to make life difficult for competitors.
A complex package ecosystem was probably not part of RStudio’s product vision, at least for many years. But sooner or later, RStudio management will have realised that simplicity and ease of use is not in their interest.
Once a collection of complicated packages exist, it is in RStudio’s interest to get as many other packages using them, as quickly as possible. Infect the host quickly, before anybody notices; all the while telling people how much the company is investing in the community that it cares about (making lots of money from).
Having this package ecosystem known as the Hadley-verse gives too much influence to one person, and makes it difficult to fire him later. Rebranding as the Tidyverse solves these problems.
Matloff accuses RStudio of monopoly behavior, I would have said they are fighting for survival (i.e., creating an environment capable of generating the kind of income a VC funded company is expected to make). Having worked in language environments where multiple, and incompatible, package ecosystems existed, I can see advantages in there being a monopoly. Matloff is also upset about a commercial company swooping in to steal their precious, a common academic complaint (academics swooping in to steal ideas from commercially developed software is, of course, perfectly respectable). Matloff also makes claims about teachability of programming that are not derived from any experimental evidence, but then everybody makes claims about programming languages without there being any experimental evidence.
RStudio management rode in on the data science wave, raising money from VCs. The wave is subsiding and they now need to appear to have a viable business (so they can be sold to a bigger fish), which means there has to be a visible market they can sell into. One way to sell in an open source environment is for things to be so complicated, that large companies will pay somebody to handle the complexity.
How much is a 1-hour investment today worth a year from now?
Today, I am thinking of investing 1-hour of effort adding more comments to my code; how much time must this investment save me X-months from now, for today’s 1-hour investment to be worthwhile?
Obviously, I must save at least 1-hour. But, the purpose of making an investment is to receive a greater amount at a later time; ‘paying’ 1-hour to get back 1-hour is a poor investment (unless I have nothing else to do today, and I’m likely to be busy in the coming months).
The usual economic’s based answer is based on compound interest, the technique your bank uses to calculate how much you owe them (or perhaps they owe you), i.e., the expected future value grows exponentially at some interest rate.
Psychologists were surprised to find that people don’t estimate future value the way economists do. Hyperbolic discounting provides a good match to the data from experiments that asked subjects to value future payoffs. The form of the equation used by economists is:  , while hyperbolic discounting has the form
, while hyperbolic discounting has the form  , where:
, where:  is a constant, and
is a constant, and  the period of time.
the period of time.
The simple economic approach does not explicitly include the risk that one of the parties involved may cease to exist. Including risk is non-trivial, banks handle the risk that you might disappear by asking for collateral, or adding something to the interest rate charged.
The fact that humans, and some other animals, have been found to use hyperbolic discounting suggests that evolution has found this approach, to discounting time, increases the likelihood of genes being passed on to the next generation. A bird in the hand is worth two in the bush.
How do software developers discount investment in software engineering projects?
The paper Temporal Discounting in Technical Debt: How do Software Practitioners Discount the Future? describes a study that specifies a decision that has to be made and two options, as follows:
“You are managing an N-years project. You are ahead of schedule in the current iteration. You have to decide between two options on how to spend our upcoming week. Fill in the blank to indicate the least amount of time that would make you prefer Option 2 over Option 1.
- Option 1: Implement a feature that is in the project backlog, scheduled for the next iteration. (five person days of effort).
- Option 2: Integrate a new library (five person days effort) that adds no new functionality but has a 60% chance of saving you person days of effort over the duration of the project (with a 40% chance that the library will not result in those savings).
”
Subjects are then asked six questions, each having the following form (for various time frames):
“For a project time frame of 1 year, what is the smallest number of days that would make you prefer Option 2? ___”
The experiment is run twice, using professional developers from two companies, C1 and C2 (23 and 10 subjects, respectively), and the data is available for download 🙂
The following plot shows normalised values given by some of the subjects from company C1, for the various time periods used (y-axis shows  ). On a log scale, values estimated using the economists exponential approach would form a straight line (e.g., close to the first five points of subject M, bottom right), and values estimated using the hyperbolic approach would have the concave form seen for subject C (top middle) (code+data).
). On a log scale, values estimated using the economists exponential approach would form a straight line (e.g., close to the first five points of subject M, bottom right), and values estimated using the hyperbolic approach would have the concave form seen for subject C (top middle) (code+data).
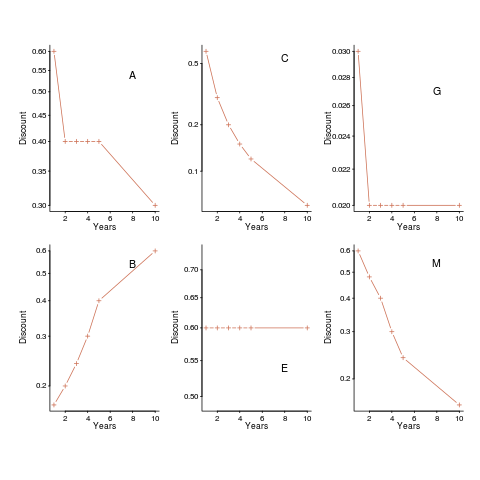
Subject B is asking for less, not more, over a longer time period (several other subjects have the same pattern of response). Why did Subject E (and most of subject G’s responses) not vary with time? Perhaps they were tired and were not willing to think hard about the problem, or perhaps they did not think the answer made much difference. The subjects from company C2 showed a greater amount of variety. Company C1 had some involvement with financial applications, while company C2 was involved in simulations. Did this domain knowledge spill over into company C1’s developers being more likely to give roughly consistent answers?
The experiment was run online, rather than an experimenter being in the room with subjects. It is possible that subjects would have invested more effort if a more formal setting, with an experimenter who had made the effort to be present. Also, if an experimenter had been present, it would have been possible to ask question to clarify any issues.
Both exponential and hyperbolic equations can be fitted to the data, but given the diversity of answers, it is difficult to put any weight in either regression model. Some subjects clearly gave responses fitting a hyperbolic equation, while others gave responses fitted approximately well by either approach, and other subjects used. It was possible to fit the combined data from all of company C1 subjects to a single hyperbolic equation model (the most significant between subject variation was the value of the intercept); no such luck with the data from company C2.
I’m very please to see there has been a replication of this study, but the current version of the paper is a jumble of ideas, and is thin on experimental procedure. I’m sure it will improve.
What do we learn from this study? Perhaps that developers need to learn something about calculating expected future payoffs.
Medieval guilds: a tax collection bureaucracy
The medieval guild is sometimes held up as the template for an institution dedicated to maintaining high standards, and training the next generation of craftsmen.
“The European Guilds: An economic analysis” by Sheilagh Ogilvie takes a chainsaw (i.e., lots of data) to all the positive things that have been said about medieval guilds (apart from them being a money making machine for those on the inside).
Guilds manipulated markets (e.g., drove down the cost of input items they needed, and kept the prices they charged high), had little or no interest in quality, charged apprentices for what little training they received, restricted entry to their profession (based on the number of guild masters the local population could support in a manner expected by masters), and did not hesitate to use force to enforce the rules of the guild (should a member appear to threaten the livelihood of other guild members).
Guild wars is not the fiction of an online game, guilds did go to war with each other.
Given their focus on maximizing income, rather than providing customer benefits, why did guilds survive for so many centuries? Guilds paid out significant sums to influence those in power, i.e., bribes. Guilds paid annual sums for the exclusive rights to ply their trade in geographical areas; it’s all down on Vellum.
Guilds provided the bureaucracy needed to collect money from the populace, i.e., they were effectively tax collectors. Medieval rulers had a high turn-over, and most were not around long enough to establish a civil service. In later centuries, the growth of a country’s population led to the creation of government departments, that were stable enough to perform tax collecting duties more efficiently that guilds; it was the spread of governments capable of doing their own tax collecting that killed off guilds.
A zero-knowledge proofs workshop
I was at the Zero-Knowledge proofs workshop run by BinaryDistict on Monday and Tuesday. The workshop runs all week, but is mostly hacking for the remaining days (hacking would be interesting if I had a problem to code, more about this at the end).
Zero-knowledge proofs allow person A to convince person B, that A knows the value of x, without revealing the value of x. There are two kinds of zero-knowledge proofs: an interacting proof system involves a sequence of messages being exchanged between the two parties, and in non-interactive systems (the primary focus of the workshop), there is no interaction.
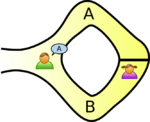
The example usually given, of a zero-knowledge proof, involves Peggy and Victor. Peggy wants to convince Victor that she knows how to unlock the door dividing a looping path through a tunnel in a cave.
The ‘proof’ involves Peggy walking, unseen by Victor, down path A or B (see diagram below; image from Wikipedia). Once Peggy is out of view, Victor randomly shouts out A or B; Peggy then has to walk out of the tunnel using the path Victor shouted; there is a 50% chance that Peggy happened to choose the path selected by Victor. The proof is iterative; at the end of each iteration, Victor’s uncertainty of Peggy’s claim of being able to open the door is reduced by 50%. Victor has to iterate until he is sufficiently satisfied that Peggy knows how to open the door.
As the name suggests, non-interactive proofs do not involve any message passing; in the common reference string model, a string of symbols, generated by person making the claim of knowledge, is encoded in such a way that it can be used by third-parties to verify the claim of knowledge. At the workshop we got an overview of zk-SNARKs (zero-knowledge succinct non-interactive argument of knowledge).
The ‘succinct’ component of zk-SNARK is what has made this approach practical. When non-interactive proofs were first proposed, the arguments of knowledge contained around one-terabyte of data; these days common reference strings are around a kilobyte.
The fact that zero-knowledge ‘proof’s are possible is very interesting, but do they have practical uses?
The hackathon aspect of the workshop was designed to address the practical use issue. The existing zero-knowledge proofs tend to involve the use of prime numbers, or the factors of very large numbers (as might be expected of a proof system that is heavily based on cryptographic techniques). Making use of zero-knowledge proofs requires mapping the problem to a form that has a known solution; this is very hard. Existing applications involve cryptography and block-chains (Zcash is a cryptocurrency that has an option that provides privacy via zero-knowledge proofs), both heavy users of number theory.
The workshop introduced us to two languages, which could be used for writing zero-knowledge applications; ZoKrates and snarky. The weekend before the workshop, I tried to install both languages: ZoKrates installed quickly and painlessly, while I could not get snarky installed (I was told that the first two hours of the snarky workshop were spent getting installs to work); I also noticed that ZoKrates had greater presence than snarky on the web, in the form of pages discussing the language. It seemed to me that ZoKrates was the market leader. The workshop presenters included people involved with both languages; Jacob Eberhardt (one of the people behind ZoKrates) gave a great presentation, and had good slides. Team ZoKrates is clearly the one to watch.
As an experienced hack attendee, I was ready with an interesting problem to solve. After I explained the problem to those opting to use ZoKrates, somebody suggested that oblivious transfer could be used to solve my problem (and indeed, 1-out-of-n oblivious transfer does offer the required functionality).
My problem was: Let’s say I have three software products, the customer has a copy of all three products, and is willing to pay the license fee to use one of these products. However, the customer does not want me to know which of the three products they are using. How can I send them a product specific license key, without knowing which product they are going to use? Oblivious transfer involves a sequence of message exchanges (each exchange involves three messages, one for each product) with the final exchange requiring that I send three messages, each containing a separate product key (one for each product); the customer can only successfully decode the product-specific message they had selected earlier in the process (decoding the other two messages produces random characters, i.e., no product key).
Like most hackathons, problem ideas were somewhat contrived (a few people wanted to delve further into the technical details). I could not find an interesting team to join, and left them to it for the rest of the week.
There were 50-60 people on the first day, and 30-40 on the second. Many of the people I spoke to were recent graduates, and half of the speakers were doing or had just completed PhDs; the field is completely new. If zero-knowledge proofs take off, decisions made over the next year or two by the people at this workshop will impact the path the field follows. Otherwise, nothing happens, and a bunch of people will have interesting memories about stuff they dabbled in, when young.
Lehman ‘laws’ of software evolution
The so called Lehman laws of software evolution originated in a 1968 study, and evolved during the 1970s; the book “Program Evolution: processes of software change” by Lehman and Belady was published in 1985.
The original work was based on measurements of OS/360, IBM’s flagship operating system for the computer industries flagship computer. IBM dominated the computer industry from the 1950s, through to the early 1980s; OS/360 was the Microsoft Windows, Android, and iOS of its day (in fact, it had more developer mind share than any of these operating systems).
In its day, the Lehman dataset not only bathed in reflected OS/360 developer mind-share, it was the only public dataset of its kind. But today, this dataset wouldn’t get a second look. Why? Because it contains just 19 measurement points, specifying: release date, number of modules, fraction of modules changed since the last release, number of statements, and number of components (I’m guessing these are high level programs or interfaces). Some of the OS/360 data is plotted in graphs appearing in early papers, and can be extracted; some of the graphs contain 18, rather than 19, points, and some of the values are not consistent between plots (extracted data); in later papers Lehman does point out that no statistical analysis of the data appears in his work (the purpose of the plots appears to be decorative, some papers don’t contain them).
One of Lehman’s early papers says that “… conclusions are based, comes from systems ranging in age from 3 to 10 years and having been made available to users in from ten to over fifty releases.“, but no other details are given. A 1997 paper lists module sizes for 21 releases of a financial transaction system.
Lehman’s ‘laws’ started out as a handful of observations about one very large software development project. Over time ‘laws’ have been added, deleted and modified; the Wikipedia page lists the ‘laws’ from the 1997 paper, Lehman retired from research in 2002.
The Lehman ‘laws’ of software evolution are still widely cited by academic researchers, almost 50-years later. Why is this? The two main reasons are: the ‘laws’ are sufficiently vague that it’s difficult to prove them wrong, and Lehman made a large investment in marketing these ‘laws’ (e.g., publishing lots of papers discussing these ‘laws’, and supervising PhD students who researched software evolution).
The Lehman ‘laws’ are not useful, in the sense that they cannot be used to make predictions; they apply to large systems that grow steadily (i.e., the kind of systems originally studied), and so don’t apply to some systems, that are completely rewritten. These ‘laws’ are really an indication that software engineering research has been in a state of limbo for many decades.
PCTE: a vestige of a bygone era of ISO standards
The letters PCTE (Portable Common Tool Environment) might stir vague memories, for some readers. Don’t bother checking Wikipedia, there is no article covering this PCTE (although it is listed on the PCTE acronym page).
The ISO/IEC Standard 13719 Information technology — Portable common tool environment (PCTE) —, along with its three parts, has reached its 5-yearly renewal time.
The PCTE standard, in itself, is not interesting; as far as I know it was dead on arrival. What is interesting is the mindset, from a bygone era, that thought such a standard was a good idea; and, the continuing survival of a dead on arrival standard sheds an interesting light on ISO standards in the 21st century.
PCTE came out of the European Union’s first ESPRIT project, which ran from 1984 to 1989. Dedicated workstations for software developers were all the rage (no, not those toy microprocessor-based thingies, but big beefy machines with 15 inch displays, and over a megabyte of memory), and computer-aided software engineering (CASE) tools were going to provide a huge productivity boost.
PCTE is a specification for a tool interface, i.e., an interface whereby competing CASE tools could provide data interoperability. The promise of CASE tools never materialized, and they faded away, removing the need for an interface standard.
CASE tools and PCTE are from an era where lots of managers still thought that factory production methods could be applied to software development.
PCTE was a European-funded project coordinated by a (at the time) mainframe manufacturer. Big is beautiful, and specifications with clout are ISO standards (ECMA was used to fast track the document).
At the time Ada was the language that everybody was going to be writing in the future; so, of course, there is an Ada binding (there is also a C one, cannot ignore reality too much).
Why is there still an ISO standard for PCTE? All standards are reviewed every 5-years, countries have to vote to keep them, or not, or abstain. How has this standard managed to ‘live’ so long?
One explanation is that by being dead on arrival, PCTE never got the chance to annoy anybody, and nobody got to know anything about it. Standard’s committees tend to be content to leave things as they are; it would be impolite to vote to remove a document from the list of approved standards, without knowing anything about the subject area covered.
The members of IST/5, the British Standards committee responsible (yes, it falls within programming languages), know they know nothing about PCTE (and that its usage is likely to be rare to non-existent) could vote ABSTAIN. However, some member countries of SC22 might vote YES, because while they know they know nothing about PCTE, they probably know nothing about most of the documents, and a YES vote does not require any explanation (no, I am not suggesting some countries have joined SC22 to create a reason for flunkies to spend government money on international travel).
Prior to the Internet, ISO standards were only available in printed form. National standards bodies were required to hold printed copies of ISO standards, ready for when an order to arrive. When a standard having zero sales in the last 5-years, came up for review a pleasant person might show up at the IST/5 meeting (or have a quiet word with the chairman beforehand); did we really want to vote to keep this document as a standard? Just think of the shelf space (I never heard them mention the children dead trees). Now they have pdfs occupying rotating rust.
Cognitive capitalism chapter reworked
The Cognitive capitalism chapter of my evidence-based software engineering book took longer than expected to polish; in fact it got reworked, rather than polished (which still needs to happen, and there might be more text moving from other chapters).
Changing the chapter title, from Economics to Cognitive capitalism, helped clarify lots of decisions about the subject matter it ought to contain (the growth in chapter page count is more down to material moving from other chapters, than lots of new words from me).
I over-spent time down some interesting rabbit holes (e.g., real options), before realising that no public data was available, and unlikely to be available any time soon. Without data, there is not a lot that can be said in a data driven book.
Social learning is a criminally under researched topic in software engineering. Some very interesting work has been done by biologists (e.g., Joseph Henrich, and Kevin Laland), in the last 15 years; the field has taken off. There is a huge amount of social learning going on in software engineering, and virtually nobody is investigating it.
As always, if you know of any interesting software engineering data, please let me know.
Next, the Ecosystems chapter.
Evidence on the distribution and diversity of Christianity: 1900-2000
I recently read an article saying that Christianity had 33,830 denominations, with 150 having more than 1 million followers. Checking the references, World Christian Encyclopedia was cited as the source; David Barrett had spent 12 years traveling the world, talking to people to collect the data. An evidence-based man, after my own heart.
Checking the second-hand book sites, I found a copy of the 1982 edition available for a few pounds, and placed an order (this edition lists 20,800 denominations; how many more are there to be ‘discovered’).
The book that arrived was a bit larger than I had anticipated. This photograph shows just how large this book is, compared to other dead-tree data sources in my collection (on top, in red, is your regular 400 page book):

My interest in a data-driven discussion of the spread and diversity of religions, was driven by wanting ideas for measuring the spread and diversity of programming languages. Bill Kinnersley’s language list contains information on 2,500 programming languages, and there are probably an order of magnitude more languages waiting to be written about.
The data is available to researchers, but is not public 🙁
The World Christian Encyclopedia is way too detailed for my needs. I usually leave unwanted books on the book table of my local train station’s Coffee shop. I have left some unusual books there in the past, but this one feels like it needs a careful owner; I will see whether the local charity shop will take it in.
Background checks on pointer values being considered for C
DR 260 is a defect report submitted to WG14, the C Standards’ committee, in 2001 that was never resolved, then generally ignored for 10-years, then caught the attention of a research group a few years ago, and is now back on WG14’s agenda. The following discussion covers two of the three questions raised in the DR.
Consider the following fragment of code:
int *p, *q; p = malloc (sizeof (int)); assert (p != NULL); // Line A (free)(p); // Line B // more code q = malloc (sizeof (int)); assert (q != NULL); // Line C if (memcmp (&p, &q, sizeof p) == 0) // Line D {*p = 42; // Line E *q = 43;} // Line F |
Section 6.2.4p2 of the C Standard says:
“The value of a pointer becomes indeterminate when the object it points to (or just past) reaches the end of its lifetime.”
The call to free, on line B, ends the lifetime of the storage (allocated on line A) pointed to by p.
There are two proposed interpretations of the sentence, in 6.2.4p2.
- “becomes indeterminate” is treated as effectively storing a value in the pointer, i.e., some bit pattern denoting an indeterminate value. This interpretation requires that any other variables that had been assigned
p‘s value, prior to thefree, also have an indeterminate value stored into them, - the value held in the pointer is to be treated as an indeterminate value (for instance, a memory management unit may prevent any access to the corresponding storage).
What are the practical implications of the two options?
The call to malloc, on line C, could return a pointer to a location that is identical to the pointer returned by the first call to malloc, i.e., the second call might immediately reuse the free‘ed storage.
Effectively storing a value in the pointer, in response to the call to free means the subsequent call to memcmp would always return a non-zero value, and the questions raised below do not apply; it would be a nightmare to implement, especially in a multi-process environment.
If the sentence in section 6.2.4p2 is interpreted as treating the pointer value as indeterminate, then the definition of malloc needs to be updated to specify that all returned values are determinate, i.e., any indeterminacy that may exist gets removed before a value is returned (the memory management unit must allow read/write access to the storage).
The memcmp, on line D, does a byte-wise compare of the pointer values (a byte-wise compare side-steps indeterminate value issues). If the comparison is exact, an assignment is made via p, line E, and via q, line F.
Does the assignment via p result in undefined behavior, or is the conformance status of the code unaffected by its presence?
Nobody is impuning the conformance status of the assignment via q, on line F.
There are people who think that the assignment via p, on line E, should be treated as undefined behavior, despite the fact that the values of p and q are byte-wise identical. When this issue was first raised (by those trouble makers in the UK ;-), yours truly was less than enthusiastic, but there were enough knowledgeable people in the opposing camp to keep the ball rolling for a while.
The underlying issue some people have with some subsequent uses of p is its provenance, the activities it has previously been associated with.
Provenance can be included in the analysis process by associating a unique number with the address of every object, at the start of its lifetime; these p-numbers are not reused.
The value returned by the call to malloc, on line A, would include a pointer to the allocated storage, plus an associated p-number; the call on line C could return a pointer having the same value, but its p-number is required to be different. Implementations are not required to allocate any storage for p-numbers, treating them purely as conceptual quantities. Your author knows of two implementations that do allocate storage for p-numbers (in a private area), and track usage of p-numbers; the Model Implementation C Checker was validated as handling all of C90, and Cerberus which handles a substantial subset of C11, and I don’t believe that the other tools that check array bounds and use after free are based on provenance (corrections welcome).
If provenance is included as part of a pointer’s value, the behavior of operators needs to be expanded to handle the p-number (conceptual or not) component of a pointer.
The rules might specify that p-numbers are conceptually compared by the call to memcmp, on line C; hence p and q are considered to never compare equal. There is an existing practice of regarding byte compares as just that, i.e., no magic ever occurs when comparing bytes (otherwise known as objects having type unsigned char).
Having p-numbers be invisible to memcmp would be consistent with existing practice. The pointer indirection operation on line E (generating undefined behavior) is where p-numbers get involved and cause the undefined behavior to occur.
There are other situations where pointer values, that were once indeterminate, can appear to become ‘respectable’.
For a variable, defined in a function, “… its lifetime extends from entry into the block with which it is associated until execution of that block ends in any way.”; section 6.2.4p3.
In the following code:
int x; static int *p=&x; void f(int n) { int *q = &n; if (memcmp (&p, &q, sizeof p) == 0) *p = 0; p = &n; // assign an address that will soon cease to exist. } // Lifetime of pointed to object, n, terminates here int main(void) { f(1); // after this call, p has an indeterminate value f(2); } |
the pointer p has an indeterminate value after any call to f returns.
In many implementations, the second call to f will result in n having the same address it had on the first call, and memcmp will return zero.
Again, there are people who have an issue with the assignment involving p, because of its provenance.
One proposal to include provenance contains substantial changes to existing word in the C Standard. The rationale for is proposals looks more like a desire to change wording to make things clearer for those making the change, than a desire to address DR 260. Everybody thinks their proposed changes make the wording clearer (including yours truly), such claims are just marketing puff (and self-delusion); confirmation from the results of an A/B test would add substance to such claims.
It is probably possible to explicitly include support for provenance by making a small number of changes to existing wording.
Is the cost of supporting provenance (i.e., changing existing wording may introduce defects into the standard, the greater the amount of change the greater the likelihood of introducing defects), worth the benefits?
What are the benefits of introducing provenance?
Provenance makes it possible to easily specify that the uses of p, in the two previous examples (and a third given in DR 260), are undefined behavior (if that is WG14’s final decision).
Provenance also provides a model that might make it easier to reason about programs; it’s difficult to say one way or the other, without knowing what the model is.
Supporters claim that provenance would enable tool vendors to flag various snippets of code as suspicious. Tool vendors can already do this, they don’t need permission from the C Standard to flag anything they fancy.
The C Standard requires a conforming implementation to diagnose certain constructs. A conforming implementation can issue as many messages as it likes, for any other construct, e.g., for line A in the first example, a compiler might print “This is the 1,000,000’th call to malloc I have translated, ring this number to claim your prize!”
Before any changes are made to wording in the C Standard, WG14 needs to decide what the behavior should be for these examples; it could decide to continue ignoring them for another 20-years.
Once a decision is made, the next question is how to update wording in the standard to specify the behavior that has been decided on.
While provenance is an interesting idea, the benefits it provides appear to be not worth the cost of changing the C Standard.
Recent Comments