No replies to 135 research data requests: paper titles+author emails
I regularly email researchers referring to a paper of theirs I have read, and asking for a copy of the data to use as an example in my evidence-based software engineering book; of course their work is cited as the source.
Around a third of emails don’t receive any reply (a small number ask why they should spend time sorting out the data for me, and I wrote a post to answer this question). If there is no reply after roughly 6-months, I follow up with a reminder, saying that I am still interested in their data (maybe 15% respond). If the data looks really interesting, I might email again after 6-12 months (I have outstanding requests going back to 2013).
I put some effort into checking that a current email address is being used. Sometimes the work was done by somebody who has moved into industry, and if I cannot find what looks like a current address I might email their supervisor.
I have had replies to later email, apologizing, saying that the first email was caught by their spam filter (the number of links in the email template was reduced to make it look less like spam). Sometimes the original email never percolated to the top of their todo list.
There are were originally around 135 unreplied email requests (the data was automatically extracted from my email archive and is not perfect); the list of papers is below (the title is sometimes truncated because of the extraction process).
Given that I have collected around 620 software engineering datasets (there are several ways of counting a dataset), another 135 would make a noticeable difference. I suspect that much of the data is now lost, but even 10 more datasets would be nice to have.
After the following list of titles is a list of the 254 author last known email addresses. If you know any of these people, please ask them to get in touch.
If you are an author of one of these papers: ideally send me the data, otherwise email to tell me the status of the data (I’m summarising responses, so others can get some idea of what to expect).
50 CVEs in 50 Days: Fuzzing Adobe Reader A Change-Aware Per-File Analysis to Compile Configurable Systems A Design Structure Matrix Approach for Measuring Co-Change-Modularity A Foundation for the Accurate Prediction of the Soft Error AGENT-BASED SIMULATION OF THE SOFTWARE DEVELOPMENT PROCESS: A CASE STUDY A Large Scale Evaluation of Automated Unit Test Generation Using A large-scale study of the time required to compromise A Large-Scale Study On Repetitiveness, Containment, and Analysing Humanly Generated Random Number Sequences: A Pattern-Based Analysis of Software Aging in a Web Server Analyzing and predicting effort associated with finding & fixing Analyzing CAD competence with univariate and multivariate Analyzing Differences in Risk Perceptions between Developers Analyzing the Decision Criteria of Software Developers Based on An analysis of the effect of environmental and systems complexity on An Empirical Analysis of Software-as-a-Service Development An Empirical Comparison of Forgetting Models An empirical study of the textual similarity between An error model for pointing based on Fitts' law An Evolutionary Study of Linux Memory Management for Fun and Profit An examination of some software development effort and An Experimental Survey of Energy Management Across the Stack Anomaly Trends for Missions to Mars: Mars Global Surveyor A Quantitative Evaluation of the RAPL Power Control System Are Information Security Professionals Expected Value Maximisers?: A replicated and refined empirical study of the use of friends in A Study of Repetitiveness of Code Changes in Software Evolution A Study on the Interactive Effects among Software Project Duration, Risk Bias in Proportion Judgments: The Cyclical Power Model Capitalization of software development costs Configuration-aware regression testing: an empirical study of sampling Cost-Benefit Analysis of Technical Software Documentation Decomposing the problem-size effect: A comparison of response Determinants of vendor profitability in two contractual regimes: Diagnosing organizational risks in software projects: Early estimation of users’ perception of Software Quality MEASURING USER’S PERCEPTION AND OPINION OF SOFTWARE QUALITY Empirical Analysis of Factors Affecting Confirmation Estimating Agile Software Project Effort: An Empirical Study Estimating computer depreciation using online auction data Estimation fulfillment in software development projects Ethical considerations in internet code reuse: A Evaluating. Heuristics for Planning Effective and Explaining Multisourcing Decisions in Application Outsourcing Exploring defect correlations in a major. Fortran numerical library Extended Comprehensive Study of Association Measures for Eye gaze reveals a fast, parallel extraction of the syntax of Factorial design analysis applied to the performance of Frequent Value Locality and Its Applications Historical and Impact Analysis of API Breaking Changes: How do i know whether to trust a research result? How do OSS projects change in number and size? How much is “about” ? Fuzzy interpretation of approximate Humans have evolved specialized skills of Identifying and Classifying Ambiguity for Regulatory Requirements Identifying Technical Competences of IT Professionals. The Case of Impact of Programming and Application-Specific Knowledge Individual-Level Loss Aversion in Riskless and Risky Choices Industry Shakeouts and Technological Change Inherent Diversity in Replicated Architectures Initial Coin Offerings and Agile Practices Interpreting Gradable Adjectives in Context: Domain Is Branch Coverage a Good Measure of Testing Effectiveness? JavaScript Developer Survey Results Knowledge Acquisition Activity in Software Development Language matters Learning from Evolution History to Predict Future Requirement Changes Learning from Experience in Software Development: Learning from Prior Experience: An Empirical Study of Links Between the Personalities, Views and Attitudes of Software Engineers Making root cause analysis feasible for large code bases: Making-Sense of the Impact and Importance of Outliers in Project Management Aspects of Software Clone Detection and Analysis Managing knowledge sharing in distributed innovation from the Many-Core Compiler Fuzzing Measuring Agility Mining for Computing Jobs Mining the Archive of Formal Proofs. Modeling Readability to Improve Unit Tests Modeling the Occurrence of Defects and Change Modelling and Evaluating Software Project Risks with Quantitative Moore’s Law and the Semiconductor Industry: A Vintage Model Motivations for self-assembling into project teams Networks, social influence and the choice among competing innovations: Nonliteral understanding of number words Nonstationarity and the measurement of psychophysical response in Occupations in Information Technology On information systems project abandonment On the Positive Effect of Reactive Programming on Software ON THE USE OF REPLACEMENT MESSAGES IN API DEPRECATION: On Vendor Preferences for Contract Types in Offshore Software Projects: Peer Review on Open Source Software Projects: Parameter-based refactoring and the relationship with fan-in/fan-out Participation in Open Knowledge Communities and Job-Hopping: Pipeline management for the acquisition of industrial projects Predicting the Reliability of Mass-Market Software in the Marketplace Prototyping A Process Monitoring Experiment Quality vs risk: An investigation of their relationship in Quantitative empirical trends in technical performance Reported project management effort, project size, and contract type. Reproducible Research in the Mathematical Sciences Semantic Versioning versus Breaking Changes Software Aging Analysis of the Linux Operating System Software reliability as a function of user execution patterns Software Start-up failure An exploratory study on the Spatial estimation: a non-Bayesian alternative System Life Expectancy and the Maintenance Effort: Exploring Testing as an Investment The enigma of evaluation: benefits, costs and risks of IT in THE IMPACT OF PLANNING AND OTHER ORGANIZATIONAL FACTORS The impact of size and volatility on IT project performance The Influence of Size and Coverage on Test Suite The Marginal Value of Increased Testing: An Empirical Analysis The nature of the times to flight software failure during space missions Theoretical and Practical Aspects of Programming Contest Ratings The Performance of the N-Fold Requirement Inspection Method The Reaction of Open-Source Projects to New Language Features: The Role of Contracts on Quality and Returns to Quality in Offshore The Stagnating Job Market for Young Scientists Turnover of Information Technology Professionals: Unconventional applications of compiler analysis Unifying DVFS and offlining in mobile multicores Use of Structural Equation Modeling to Empirically Study the Turnover Use Two-Level Rejuvenation to Combat Software Aging and Using Function Points in Agile Projects Using Learning Curves to Mine Student Models Virtual Integration for Improved System Design Which reduces IT turnover intention the most: Workplace characteristics Why Did Your Project Fail? Within-Die Variation-Aware Dynamic-Voltage-Frequency |
Author emails (automatically extracted and manually checked to remove people who have replied on other issues; I hope I have caught them all).
Aaron.Carroll@nicta.com.au abaker@ucar.edu abd_elzamly@yahoo.com actjn@siu.edu agopal@rhsmith.umd.edu akbar.namin@ttu.edu aken@nsuok.edu akmassey@umbc.edu alessandro.murgia@uantwerpen.be alexander.budzier@sbs.ox.ac.uk alinebrito@dcc.ufmg.br Allen.P.Nikora@jpl.nasa.gov Altaf.Ahmad@asu.edu Ana.Aizcorbe@bea.gov angel.garcia@uc3m.es anhnt@iastate.edu a.pinna@diee.unica.it arho.suominen@vtt.fi arie.vandeursen@tudelft.nl asang@ntu.edu.sg awfboh@ntu.edu.sg bent.flyvbjerg@sbs.ox.ac.uk bf@ul.ie bjg@empiricalreality.com bojan.spasic@avl.com bramesh@gsu.edu brent.martin@canterbury.ac.nz briand@simula.no brian.fitzgerald@lero.ie bronevetsky1@llnl.gov burairah@utem.edu.my calikli@chalmers.se canton@mnec.gr cc05@vokac.org celio.santana@gmail.com cguo13@hawk.iit.edu charngda@ccr.buffalo.edu charngdalu@yahoo.com chenyy@comp.nus.edu.sg chris.sauer@sbs.ox.ac.uk christian.korunka@univie.ac.at christopher.lidbury10@imperial.ac.uk clitecky@business.siu.edu cmagee@mit.edu corey.phelps@mcgill.ca cotroneo@unina.it cthompson@cs.berkeley.edu daniela.munteanu@univ-provence.fr daniel.milroy@colorado.edu dan@silverthreadinc.com david@merobe.com david.nembhard@oregonstate.edu der.herr@hofr.at dgrtwo@princeton.edu dhkim@astate.edu director@scit.edu discy@nus.edu.sg djl68@pitt.edu dlautner@hawk.iit.edu dport@hawaii.edu dprtchan@nus.edu.sg dredman@avsi.aero drobinson@stackoverflow.com dskusumo.itt@gmail.com dwheeler@ida.org eherrman@eva.mpg.de Enrique.Dans@ie.edu ermira.daka@sheffield.ac.uk etovar@fi.upm.es fjshull@sei.cmu.edu foreverheart9@gmail.com founders@triplebyte.com fschweitzer@ethz.ch ghs2@psu.edu gleison.brito@dcc.ufmg.br glpkm@hotmail.com gordon.fraser@uni-passau.de greg@bronevetsky.com gul.calikli@gu.se guschroko@student.gu.se hankhoffmann@cs.uchicago.edu hannes.holm@foi.se hata@is.naist.jp hbarth@wesleyan.edu hello@ponyfoo.com hiroshi.igaki@oit.ac.jp hirtle@pitt.edu hoan@iastate.edu hora@dcc.ufmg.br hrideshg@iastate.edu huang@umd.edu huazhe@cs.uchicago.edu hwu28@hawk.iit.edu ichischneider@gmail.com I.Deary@ed.ac.uk ilaria.lunesu@diee.unica.it info@targetprocess.com james@jpallister.com jarmo.ahonen@uef.fi jasmin.blanchette@mpi-inf.mpg.de jasonweiyi@gmail.com javier.alonso@duke.edu jean-luc.autran@univ-provence.fr jfmendes@ua.pt jgo@ua.pt jianh@illinois.edu jimbo@business.siu.edu jmunson@uidaho.edu jo-anne.lefevre@carleton.ca john.krogstie@ntnu.no john.zhang@business.uconn.edu jordan.weissmann@slate.com jose.campos@sheffield.ac.uk josephborel@aol.com jselby@maplesoft.com June.Verner@gmail.com junyang@engr.pitt.edu justinek@alumni.stanford.edu justin.hollands@drdc-rddc.gc.ca j.visser@sig.eu kaisa.still@vtt.fi kantor@cs.technion.ac.il kevin.mcdaid@dkit.ie kewusi@lmu.edu K.Markantonakis@rhul.ac.uk konstantinos.chronis@gmail.com ktrivedi@duke.edu laertexavier@dcc.ufmg.br larissanadja@copin.ufcg.edu.br lcao@odu.edu leo@susaventures.com lionel.briand@uni.lu lsarigia@pme.duth.gr lucia.2009@smu.edu.sg magnus@magnusdettmar.com mail@kaidence.org ma.khan@uleth.ca manuel.oriol@ch.abb.com marc.schulz@rwth-aachen.de Marek@gryting.biz marie-jeanne.lesot@lip6.fr mariusz.musial@ericpol.com maruyama@atr.jp matthias.biggeleben@open-xchange.com matthias.stuermer@iwi.unibe.ch mcknight@bus.msu.edu mdettmar@deloitte.com mdettmar@deloitte.se melanie@cs.columbia.edu Michael.english@lero.ie michael.english@ul.ie michael.grottke@fau.de Michael.Grottke@wiso.uni-erlangen.de Michael@targetprocess.com mingshu@iscas.ac.cn mischael.schill@inf.ethz.ch misof@ksp.sk mjaber@ryerson.ca monica.pais@ifgoiano.edu.br monicaspais@gmail.com mschermann@scu.edu mtov@dcc.ufmg.br mzhu@ets.org ncerpa@utalca.cl Neil.Stewart@warwick.ac.uk Nelson.W.Green@jpl.nasa.gov nick.wells@jobstats.co.uk o.alexy@tum.de oliver.krancher@iwi.unibe.ch Oliver.Laitenberger@horn-company.de olivier.gendreau@polymtl.ca paula.j.savolainen@uef.fi paulmcb@seas.upenn.edu paul@strassmann.com pchatzog@pme.duth.gr perry@mail.utexas.edu philippe.roche@st.com phoonakker@cqpi.engr.wisc.edu pierre.robillard@polymtl.ca ploaiza@lsm.in2p3.fr P.Love@curtin.edu.au pokech@uonbi.ac.ke psidhu@cmu.edu pyzychen@gmail.com ren@iit.edu rh13@aub.edu.lb ricardo.colomo@uc3m.es rkiyer@illinois.edu robert.benkoczi@uleth.ca roberto.natella@unina.it roberto.pietrantuono@unina.it salvaneschi@cs.tu-darmstadt.de saurabh.dighe@intel.com sdorogov@ua.pt sebastien.lefort@lip6.fr sebastien.sauze@l2mp.fr shaji@scit.edu shilin@itechs.iscas.ac.cn show@um.edu.my siegfrie@adelphi.edu simona.ibba@diee.unica.it simon.gaechter@nottingham.ac.uk simonk@rpi.edu simvrh@gmail.com sl@monochromata.de soenke.albers@the-klu.org songxue@microsoft.com s.raemaekers@sig.eu sriram.vangal@intel.com ssg@engr.uconn.edu stavrino@eap.gr stavrino@gmail.com stefan@garage-coding.com sterusso@unina.it steve.a.shogren@gmail.com svkbharathi@scit.edu swilson@tcd.ie tamada@cse.kyoto-su.ac.jp tien@iastate.edu tien.n.nguyen@utdallas.edu tjleffel@gmail.com tkabdelh@nps.edu tsunoda@info.kindai.ac.jp tung@iastate.edu victoria@stodden.net wangyi@us.ibm.com William.L.Taber@jpl.nasa.gov wmhan@takming.edu.tw wobbrock@uw.edu wq@itechs.iscas.ac.cn xenos@eap.gr xhua@hawk.iit.edu xiao.qu@us.abb.com yanglusi@comp.nus.edu.sg ychen200@cba.ua.edu yi.wang@rit.edu yiw@ics.uci.edu yoaval@checkpoint.com zhangx@nku.edu zhij@cs.toronto.edu Zhongju.Zhang@asu.edu zibran@cs.uno.edu |
Update:
Have received a response relating to 6 papers (corresponding paper/author entries in above list deleted).
Algorithms are now commodities
When I first started writing software, developers had to implement most of the algorithms they used; yes, hardware vendors provided libraries, but the culture was one of self-reliance (except for maths functions, which were technical and complicated).
Developers read Donald Knuth’s The Art of Computer Programming, it was the reliable source for step-by-step algorithms. I vividly remember seeing a library copy of one volume, where somebody had carefully hand-written, in very tiny letters, an update to one algorithm, and glued it to the page over the previous text.
Algorithms were important because computers were not yet fast enough to solve common problems at an acceptable rate; developers knew the time taken to execute common instructions and instruction timings were a topic of social chit-chat amongst developers (along with the number of registers available on a given cpu). Memory capacity was often measured in kilobytes, every byte counted.
This was the age of the algorithm.
Open source commoditized algorithms, and computers got a lot faster with memory measured in megabytes and then gigabytes.
When it comes to algorithm implementation, developers are now spoilt for choice; why waste time implementing the ‘low’ level stuff when there were plenty of other problems waiting to be implemented.
Algorithms are now like the bolts in a bridge: very important, but nobody talks about them. Today developers talk about story points, features, business logic, etc. Given a well-defined problem, many are now likely to search for an existing package, rather than write code from scratch (I certainly work this way).
New algorithms are still being invented, and researchers continue to look for improvements to existing algorithms. This is a niche activity.
There are companies where algorithms are not commodities. Google operates on a scale where what appears to others as small improvements, can save the company millions (purely because a small percentage of a huge amount can be a lot). Some company’s core competency may include an algorithmic component (whose non-commodity nature gives the company its edge over the competition), with the non-core competency treating algorithms as a commodity.
Knuth’s The Art of Computer Programming played an important role in making viable algorithms generally available; while the volumes are frequently cited, I suspect they are rarely read (I have not taken any of my three volumes off the shelf, to read, for years).
A few years ago, I suddenly realised that I was working on a book about software engineering that not only did not contain an algorithms chapter, and the 103 uses of the word algorithm all refer to it as a concept.
Today, we are in the age of the ecosystem.
Algorithms have not yet completed their journey to obscurity, which has to wait until people can tell computers what they want and not be concerned about the implementation details (or genetic algorithm programming gets a lot better).
beta: Evidence-based Software Engineering – book
My book, Evidence-based software engineering: based on the publicly available data is now out on beta final release (pdf, and code+data). The plan is for a three-month review, with the final version available in the shops in time for Christmas (I plan to get a few hundred printed, and made available on Amazon).
The next few months will be spent responding to reader comments, and adding material from the remaining 20 odd datasets I have waiting to be analysed.
You can either email me with any comments, or add an issue to the book’s Github page.
While the content is very different from my original thoughts, 10-years ago, the original aim of discussing all the publicly available software engineering data has been carried through (in some cases more detailed data, in greater quantity, has supplanted earlier less detailed/smaller datasets).
The aim of only discussing a topic if public data is available, has been slightly bent in places (because I thought data would turn up, and it didn’t, or I wanted to connect two datasets, or I have not yet deleted what has been written).
The outcome of these two aims is that the flow of discussion is very disjoint, even disconnected. Another reason might be that I have not yet figured out how to connect the material in a sensible way. I’m the first person to go through this exercise, so I have no idea where it’s going.
The roughly 620+ datasets is three to four times larger than I thought was publicly available. More data is good news, but required more time to analyse and discuss.
Depending on the quantity of issues raised, updates of the beta release will happen.
As always, if you know of any interesting software engineering data, please tell me.
How should involved if-statement conditionals be structured?
Which of the following two if-statements do you think will be processed by readers in less time, and with fewer errors, when given the value of x, and asked to specify the output?
// First - sequence of subexpressions if (x > 0 && x < 10 || x > 20 && x < 30) print("a"); else print "b"); // Second - nested ifs if (x > 0 && x < 10) print("c"); else if (x > 20 && x < 30) print("d"); else print("e"); |
Ok, the behavior is not identical, in that the else if-arm produces different output than the preceding if-arm.
The paper Syntax, Predicates, Idioms — What Really Affects Code Complexity? analyses the results of an experiment that asked this question, including more deeply nested if-statements, the use of negation, and some for-statement questions (this post only considers the number of conditions/depth of nesting components). A total of 1,583 questions were answered by 220 professional developers, with 415 incorrect answers.
Based on the coefficients of regression models fitted to the results, subjects processed the nested form both faster and with fewer incorrect answers (code+data). As expected performance got slower, and more incorrect answers given, as the number of intervals in the if-condition increased (up to four in this experiment).
I think short-term memory is involved in this difference in performance; or at least I can concoct a theory that involves a capacity limited memory. Comprehending an expression (such as the conditional in an if-statement) requires maintaining information about the various components of the expression in working memory. When the first subexpression of x > 0 && x < 10 || x > 20 && x < 30 is false, and the subexpression after the || is processed, there is no now forget-what-went-before point like there is for the nested if-statements. I think that the single expression form is consuming more working memory than the nested form.
Does the result of this experiment (assuming it is replicated) mean that developers should be recommended to write sequences of conditions (e.g., the first if-statement example) about as:
if (x > 0 && x < 10) print("a"); else if (x > 20 && x < 30) print("a"); else print("b"); |
Duplicating code is not good, because both arms have to be kept in sync; ok, a function could be created, but this is extra effort. As other factors are taken into account, the costs of the nested form start to build up, is the benefit really worth the cost?
Answering this question is likely to need a lot of work, and it would be a more efficient use of resources to address questions about more commonly occurring conditions first.
A commonly occurring use is testing a single range; some of the ways of writing the range test include:
if (x > 0 && x < 10) ... if (0 < x && x < 10) ... if (10 > x && x > 0) ... if (x > 0 && 10 > x) ... |
Does one way of testing the range require less effort for readers to comprehend, and be more likely to be interpreted correctly?
There have been some experiments showing that people are more likely to give correct answers to questions involving information expressed as linear syllogisms, if the extremes are at the start/end of the sequence, such as in the following:
A is better than B
B is better than C |
and not the following (which got the lowest percentage of correct answers):
B is better than C
B is worse than A |
Your author ran an experiment to find out whether developers were more likely to give correct answers for particular forms of range tests in if-conditions.
Out of a total of 844 answers, 40 were answered incorrectly (roughly one per subject; it was a paper and pencil experiment, so no timings). It's good to see that the subjects were so competent, but with so few mistakes made the error bars are very wide, i.e., too few mistakes were made to be able to say that one representation was less mistake-prone than another.
I hope this post has got other researchers interested in understanding developer performance, when processing if-statements, and that they will be running more experiments help shed light on the processes involved.
An experiment involving matching regular expressions
Recommendations for/against particular programming constructs have one thing in common: there is no evidence backing up any of the recommendations. Running experiments to measure the impact of particular language features on developer performance is not something that researchers do (there have been a handful of experiments looking at the impact of strong typing on developer performance; the effect measured was tiny).
In February I discovered two groups researching regular expressions. In the first post on duplicate regexs, I promised to say something about the second group. This post discusses an experiment comparing developer comprehension of various regular expressions; the paper is: Exploring Regular Expression Comprehension.
The experiment involved 180 workers on Mechanical Turk (to be accepted, workers had to correctly answer four or five questions about regular expressions). Workers/subjects performed two different tasks, matching and composition.
- In the matching task workers saw a regex and a list of five strings, and had to specify whether the regex matched (or not) each string (there was also an unsure response).
- In the composition task workers saw a regular expression, and had to create a string matched by this regex. Each worker saw 10 different regexs, which were randomly drawn from a set of 60 regexs (which had been created to be representative of various regex characteristics). I have not analysed this data yet.
What were the results?
For the matching task: given each of the pairs of regexs below, which one (of each pair) would you say workers were most likely to get correct?
R1 R2 1. tri[a-f]3 tri[abcdef]3 2. no[w-z]5 no[wxyz]5 3. no[w-z]5 no(w|x|y|z)5 4. [ˆ0-9] [\D] |
The percentages correct for (1) were essentially the same, at 94.0 and 93.2 respectively. The percentages for (2) were 93.3 and 87.2, which is odd given that the regex is essentially the same as (1). Is this amount of variability in subject response to be expected? Is the difference caused by letters being much less common in text, so people have had less practice using them (sounds a bit far-fetched, but its all I could think of). The percentages for (3) are virtually identical, at 93.3 and 93.7.
The percentages for (4) were 58 and 73.3, which surprised me. But then I have been using regexs since before \D support was generally available. The MTurk generation have it easy not having to use the ‘hard stuff’ 😉
See Table III in the paper for more results.
This matching data might be analysed using Item Response theory, which can take into account differences in question difficulty and worker/subject ability. The plot below looks complicated, but only because there are so many lines. Each numbered colored line is a different regex, worker ability is on the x-axis (greater ability on the right), and the y-axis is the probability of giving a correct answer (code+data; thanks to Peipei Wang for fixing the bugs in my code):
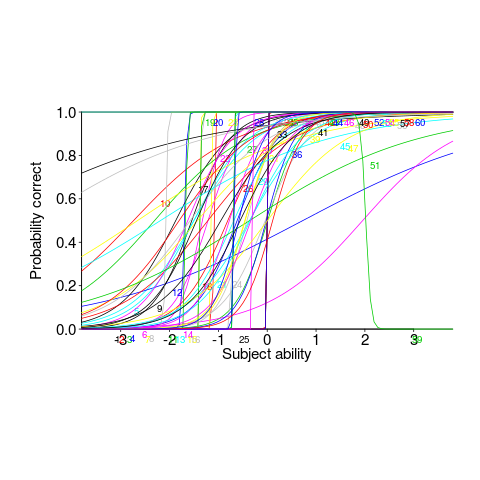
Yes, for question 51 the probability of a correct answer decreases with worker ability. Heads are being scratched about this.
There might be some patterns buried in amongst all those lines, e.g., particular kinds of patterns require a given level of ability to handle, or correct response to some patterns varying over the whole range of abilities. These are research questions, and this is a blog article: answers in the comments 🙂
This is the first experiment of its kind, so it is bound to throw up more questions than answers. Are more incorrect responses given for longer regexs, particularly if they cannot be completely held in short-term memory? It is convenient for the author to use a short-hand for a range of characters (e.g., a-f), and I was expecting a difference in performance when all the letters were enumerated (e.g., abcdef); I had theories for either one being less error-prone (I obviously need to get out more).
C++ template usage
Generics are a programming construct that allow an algorithm to be coded without specifying the types of some variables, which are supplied later when a specific instance (for some type(s)) is instantiated. Generics sound like a great idea; who hasn’t had to write the same function twice, with the only difference being the types of the parameters.
All of today’s major programming languages support some form of generic construct, and developers have had the opportunity to use them for many years. So, how often generics are used in practice?
In C++, templates are the language feature supporting generics.
The paper: How C++ Templates Are Used for Generic Programming: An Empirical Study on 50 Open Source Systems contains lots of interesting data 🙂 The following analysis applies to the five largest projects analysed: Chromium, Haiku, Blender, LibreOffice and Monero.
As its name suggests, the Standard Template Library (STL) is a collection of templates implementing commonly used algorithms+other stuff (some algorithms were commonly used before the STL was created, and perhaps some are now commonly used because they are in the STL).
It is to be expected that most uses of templates will involve those defined in the STL, because these implement commonly used functionality, are documented and generally known about (code can only be reused when its existence is known about, and it has been written with reuse in mind).
The template instantiation measurements show a 17:1 ratio for STL vs. developer-defined templates (i.e., 149,591 vs. 8,887).
What are the usage characteristics of developer defined templates?
Around 25% of developer defined function templates are only instantiated once, while 15% of class templates are instantiated once.
Most templates are defined by a small number of developers. This is not surprising given that most of the code on a project is written by a small number of developers.
The plot below shows the percentage instantiations (of all developer defined function templates) of each developer defined function template, in rank order (code+data):
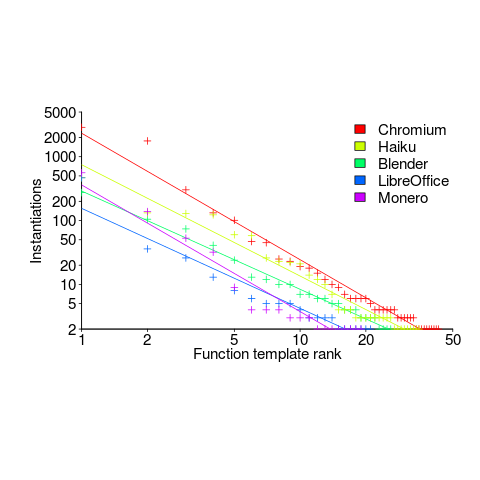
Lines are each a fitted power law, whose exponents vary between -1.5 and -2. Is it just me, or are these exponents surprising close?
The following is for developer defined class templates. Lines are fitted power law, whose exponents vary between -1.3 and -2.6. Not so close here.
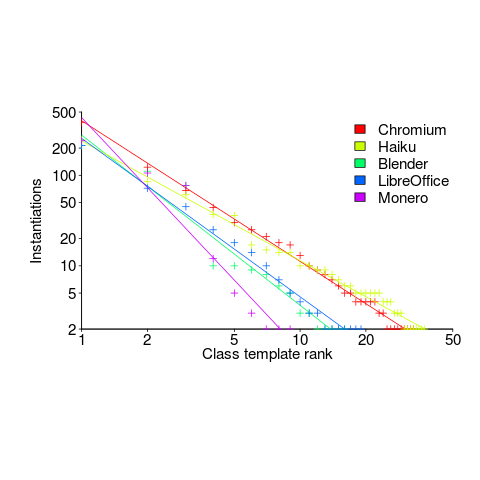
What processes are driving use of developer defined templates?
Every project has its own specific few templates that get used everywhere, by all developers. I imagine these are tailored to the project, and are widely advertised to developers who work on the project.
Perhaps some developers don’t define templates, because that’s not what they do. Is this because they work on stuff where templates don’t offer much benefit, or is it because these developers are stuck in their ways (if so, is it really worth trying to change them?)
Estimating in round numbers
People tend to use round numbers. When asked the time, the response is often rounded to the nearest 5-minute or 15-minute value, even when using a digital watch; the speaker is using what they consider to be a relevant level of accuracy.
When estimating how long it will take to perform a task, developers tend to use round numbers (based on three datasets). Giving what appears to be an overly precise value could be taken as communicating extra information, e.g., an estimate of 1-hr 3-minutes communicates a high degree of certainty (or incompetence, or making a joke). If the consumer of the estimate is working in round numbers, it makes sense to give a round number estimate.
Three large software related effort estimation datasets are now available: the SiP data contains estimates made by many people, the Renzo Pomodoro data is one person’s estimates, and now we have the Brightsquid data (via the paper “Utilizing product usage data for requirements evaluation” by Hemmati, Didar Al Alam and Carlson; I cannot find an online pdf at the moment).
The plot below shows the total number of tasks (out of the 1,945 tasks in the Brightsquid data) for which a given estimate value was recorded; peak values shown in red (code+data):
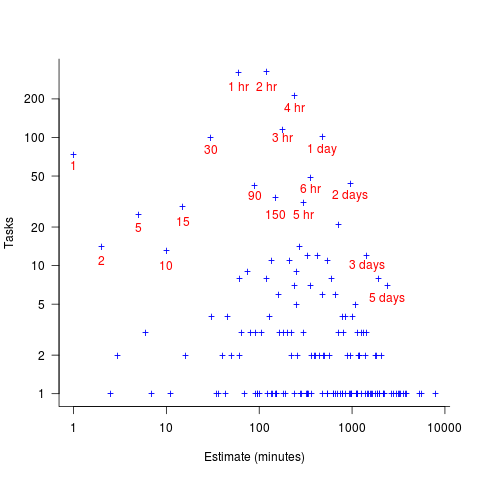
Why are there estimates for tasks taking less than 30 minutes? What are those 1 minute tasks (are they typos, where the second digit was omitted and the person involved simply create a new estimate without deleting the original)? How many of those estimate values appearing once are really typos, e.g., 39 instead of 30? Does the task logging system used require an estimate before anything can be done? Unfortunately I don’t have access to the people involved. It does look like this data needs some cleaning.
There are relatively few 7-hour estimates, but lots for 8-hours. I’m assuming the company works an 8-hour day (the peak at 4-hours, rather than three, adds weight to this assumption).
New users generate more exceptions than existing users (in one dataset)
Application usage data is one of the rarest kinds of public software engineering data.
Even data that might be used to approximate application usage is rare. Server logs might be used as a proxy for browser usage or operating system usage, and number of Debian package downloads as a proxy for usage of packages.
Usage data is an important component of fault prediction models, and the failure to incorporate such data is one reason why existing fault models are almost completely worthless.
The paper Deriving a Usage-Independent Software Quality Metric appeared a few months ago (it’s a bit of a kitchen sink of a paper), and included lots of usage data! As far as I know, this is a first.
The data relates to a mobile based communications App that used Google analytics to log basic usage information, i.e., daily totals of: App usage time, uses by existing users, uses by new users, operating system+version used by the mobile device, and number of exceptions raised by the App.
Working with daily totals means there is likely to be a non-trivial correlation between usage time and number of uses. Given that this is the only public data of its kind, it has to be handled (in my case, ignored for the time being).
I’m expecting to see a relationship between number of exceptions raised and daily usage (the data includes a count of fatal exceptions, which are less common; because lots of data is needed to build a good model, I went with the more common kind). So a’fishing I went.
On most days no exception occurred (zero is the ideal case for the vendor, but I want lots of exception to build a good model). Daily exception counts are likely to be small integers, which suggests a Poisson error model.
It is likely that the same set of exceptions were experienced by many users, rather like the behavior that occurs when fuzzing a program.
Applications often have an initial beta testing period, intended to check that everything works. Lucky for me the beta testing data is included (i.e., more exceptions are likely to occur during beta testing, which get sorted out prior to official release). This is the data I concentrated my modeling.
The model I finally settled on has the form (code+data):

Yes,  had a much bigger impact than
had a much bigger impact than  . This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two.
. This was true for all the models I built using data for all Android/iOS Apps, and the exponent difference was always greater than two.
Why square-root, rather than log? The model fit was much better for square-root; too much better for me to be willing to go with a model which had  as a power-law.
as a power-law.
The impact of  varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).
varied by several orders of magnitude (which won’t come as a surprise to developers using earlier versions of Android).
There were not nearly as many exceptions once the App became generally available, and there were a lot fewer exceptions for the iOS version.
The outsized impact of new users on exceptions experienced is easily explained by developers failing to check for users doing nonsensical things (which users new to an App are prone to do). Existing users have a better idea of how to drive an App, and tend to do the kind of things that developers expect them to do.
As always, if you know of any interesting software engineering data, please let me know.
Happy 60th birthday: Algol 60
Report on the Algorithmic Language ALGOL 60 is the title of a 16-page paper appearing in the May 1960 issue of the Communication of the ACM. Probably one of the most influential programming languages, and a language that readers may never have heard of.
During the 1960s there were three well known, widely used, programming languages: Algol 60, Cobol, and Fortran.
When somebody created a new programming languages Algol 60 tended to be their role-model. A few of the authors of the Algol 60 report cited beauty as one of their aims, a romantic notion that captured some users imaginations. Also, the language was full of quirky, out-there, features; plenty of scope for pin-head discussions.
Cobol appears visually clunky, is used by business people and focuses on data formatting (a deadly dull, but very important issue).
Fortran spent 20 years catching up with features supported by Algol 60.
Cobol and Fortran are still with us because they never had any serious competition within their target markets.
Algol 60 had lots of competition and its successor language, Algol 68, was groundbreaking within its academic niche, i.e., not in a developer useful way.
Language family trees ought to have Algol 60 at, or close to their root. But the Algol 60 descendants have been so successful, that the creators of these family trees have rarely heard of it.
In the US the ‘military’ language was Jovial, and in the UK it was Coral 66, both derived from Algol 60 (Coral 66 was the first language I used in industry after graduating). I used to hear people saying that Jovial was derived from Fortran; another example of people citing the language the popular language know.
Algol compiler implementers documented their techniques (probably because they were often academics); ALGOL 60 Implementation is a real gem of a book, and still worth a read today (as an introduction to compiling).
Algol 60 was ahead of its time in supporting undefined behaviors 😉 Such as: “The effect, of a go to statement, outside a for statement, which refers to a label within the for statement, is undefined.”
One feature of Algol 60 rarely adopted by other languages is its parameter passing mechanism, call-by-name (now that lambda expressions are starting to appear in widely used languages, call-by-name has a kind-of comeback). Call-by-name essentially has the same effect as textual substitution. Given the following procedure (it’s not a function because it does not return a value):
procedure swap (a, b); integer a, b, temp; begin temp := a; a := b; b:= temp end; |
the effect of the call: swap(i, x[i]) is:
temp := i; i := x[i]; x[i] := temp |
which might come as a surprise to some.
Needless to say, programmers came up with ‘clever’ ways of exploiting this behavior; the most famous being Jensen’s device.
The follow example of go to usage appears in: International Standard 1538 Programming languages – ALGOL 60 (the first and only edition appeared in 1984, after most people had stopped using the language):
go to if Ab < c then L17 else g[if w < 0 then 2 else n] |
Orthogonality of language use won out over the goto FUD.
The Software Preservation Group is a great resource for Algol 60 books and papers.
Having all the source code in one file
An early, and supposedly influential, analysis of the Coronavirus outbreak was based on results from a model whose 15,000 line C implementation was contained in a single file. There has been lots of tut-tutting from the peanut gallery, about the code all being in one file rather than distributed over many files. The source on Github has been heavily reworked.
Why do programmers work with all the code in one file, rather than split across multiple files? What are the costs and benefits of having the 15K of source in one file, compared to distributing it across multiple files?
There are two kinds of people who work with code all in one file, novices and really capable developers. Richard Stallman is an example of a very capable developer who worked using files containing huge amounts of code, as anybody who looked at the early sources of gcc will be all to familiar.
The benefit of having all the code in one file is that it is easy to find stuff and make global changes. If the source is scattered over multiple files, then working on the code entails knowing which file to look in to find whatever; there is a learning curve (these days screens have lots of pixels, and editors support multiple windows with a different file in each window; I’m sure lots of readers work like this).
Many years ago, when 64K was a lot of memory, I sometimes had to do developer support: people would come to me complaining that the computer was preventing them writing a larger program. What had happened was they had hit the capacity limit of the editor. The source now had to be spread over multiple files to get over this ‘limitation’. In practice people experienced the benefits of using multiple files, e.g., editor loading files faster (because they were a lot smaller) and reduced program build time (because only the code that changed needed to be recompiled).
These days, 15K of source can be loaded or compiled in a blink of an eye (unless a really cheap laptop is being used). Computing power has significantly reduced these benefits that used to exist.
What costs might be associated with keeping all the source in one file?
Monolithic code makes sharing difficult. I don’t know anything about the development environment within which these researched worked. If there were lots of different programs using the same algorithms, or reading/writing the same file formats, then code reuse often provides a benefit that makes it worthwhile splitting off the common functionality. But then the researchers has to learn how to build a program from multiple source files, which a surprising number are unwilling to do (at least it has always been surprising to me).
Within a research group, sharing across researchers might be a possible (assuming they are making some use of the same algorithms and file formats). Involving multiple people in the ongoing evolution of software creates a need for some coordination. At the individual level it may be more cost-efficient for people to have their own private copies of the source, with savings only occurring at the group level. With software development having a low status in academia, I don’t see any of the senior researchers willingly take on a management role, for this code. Perhaps one of the people working on the code is much better than the others (it often happens), but are they going to volunteer themselves as chief dogs body for the code?
In the world of Open Source, where source code is available, cut-and-paste is rampant (along with wholesale copying of files). Working with a copy of somebody else’s source removes a dependency, and if their code works well enough, then go for it.
A cost often claimed by the peanut gallery is that having all the code in a single file is a signal of buggy code. Given that most of the programmers who do this are novices, rather than really capable developers, such code is likely to contain many mistakes. But splitting the code up into multiple files will not reduce the number of mistakes it contains, just distribute them among the files. Correlation is not causation.
For an individual developer, the main benefit of splitting code across multiple files is that it makes developers think about the structure of their code.
For multi-person projects there are the added potential benefits of reusing code, and reducing the time spent reading other people’s code (it’s no fun having to deal with 10K lines when only a few functions are of interest).
I’m not saying that the original code is good, bad, or indifferent. What I am saying is that the having all the source in one file may, or may not, be the most effective way of working. It’s complicated, and I have no problem going with the flow (and limiting the size of the source files I write), but let’s not criticise others for doing what works for them.
Recent Comments