Functions reduce the need to remember lots of variables
What, if any, are the benefits of adding bureaucracy to a program by organizing a file’s source code into multiple function/method definitions (rather than a single function)?
Having a single copy of a sequence of statements that need to be executed at multiple points in a program reduces implementation effort, and any updates only need to be made once (reducing coding mistakes by removing the need to correctly make duplicate changes). A function/method is the container for this sequence of statements.
Why break code up into separate functions when each is only called once and only likely to ever be called once?
The benefits claimed from splitting code into functions include: making it easier to understand, test, debug, maintain, reuse, and scale development (i.e., multiple developers working on the same program). Our LLM overlords also make these claims, and hallucinate references to published evidence (after three iterations of pointing out the hallucinated references, I gave up asking for evidence; my experience with asking people is that they usually remember once reading something but cannot remember the source).
Regular readers will not be surprised to learn that there is little or no evidence for any of the claimed benefits. I’m not saying that the benefits don’t exist (I think there are some), simply that there have not been any reliable studies attempting to measure the benefits (pointers to such studies welcome).
Having decided to cluster source code into functions, for whatever reason, are there any organizational rules of thumb worth following?
Rules of thumb commonly involve function length (it’s easy to measure) and desirable semantic characteristics of distinct functions (it’s very hard to measure semantic characteristics).
Claims for there being an optimal function length (i.e., lines of code that minimises coding mistakes) turned out to be driven by a mathematical artifact of the axis used when plotting (miniscule) datasets.
Semantic rules of thumb such as: group by purpose, do one thing, and Single-responsibility principle are open to multiple interpretations that often boil down to personal preferences and experience.
One benefit of using functions that is rarely studied is the restricted visibility of local variables defined within them, i.e., only visible within the function body.
When trying to figure out what code does, readers have to keep track of the information contained in all the variables accessed. Having to track more variables not only increases demands on reader memory, it also increases the opportunities for making mistakes.
A study of C source found that within a function, the number of local variables is proportional to the square root of the number of statements (code+data). Assuming the proportionality constant is one, a function containing 100 statements might be expected to define 10 local variables. Splitting this function up into, say, four functions containing 25 statements, each is expected to define 5 local variables. The number of local variables that need to be remembered at the same time, when reading a function definition, has halved, although the total number of local variables that need to be remembered when processing those 100 statements has doubled. Some number of global variables and function parameters need to be added to create an overall total for the number of variables.
The plot below shows the number of locals defined in 36,617 C functions containing a given number of statements, the red line is a fitted regression model having the form:  (code+data):
(code+data):
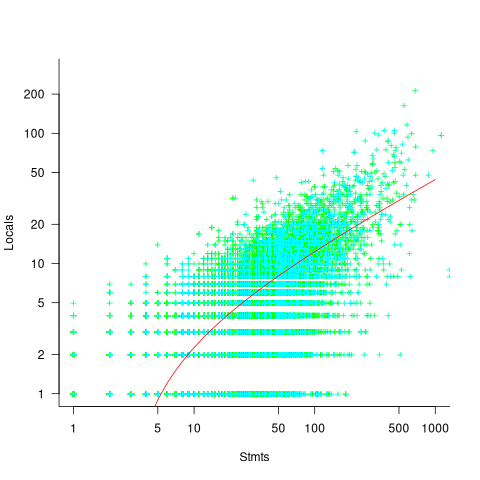
My experience with working with recently self-taught developers, especially very intelligent ones, is that they tend to write monolithic programs, i.e., everything in one function in one file. This minimal bureaucracy approach minimises the friction of a stream of thought development process for adding new code, and changing existing code as the program evolves. Most of these programs are small (i.e., at most a few hundred lines). Assuming that these people continue to code, one of two events teaches them the benefits of function bureaucracy:
- changes to older programs becomes error-prone. This happens because the developer has forgotten details they once knew, e.g., they forget which variables are in use at particular points in the code,
- the size of a program eventually exceeds their ability to remember all of it (very intelligent people can usually remember much larger programs than the rest of us). Coding mistakes occur because they forget which variables are in use at particular points in the code.
Recent Comments