Survival of CVEs in the Linux kernel
Software contained in safety related applications has to have a very low probability of failure.
How is a failure rate for software calculated?
The people who calculate these probabilities, or at least claim that some program has a suitably low probability, don’t publish the details or make their data publicly available.
People have been talking about using Linux in safety critical applications for over a decade (multiple safety levels are available to choose from). Estimating a reliability for the Linux kernel is a huge undertaking. This post is taking a first step via a broad brush analysis of a reliability associated dataset.
Public fault report logs are a very messy data source that needs a lot of cleaning; they don’t just contain problems caused by coding mistakes, around 50% are requests for enhancement (and then there is the issue of multiple reports having the same root cause).
CVE number are a curated collection of a particular kind of fault, i.e., information-security vulnerabilities. Data on 2,860 kernel CVEs is available. The data includes the first released version of the kernel containing the problem, and the version of the fixed release. The plot below shows the survival curve for kernel CVEs, with confidence intervals in blue/green (code+data):
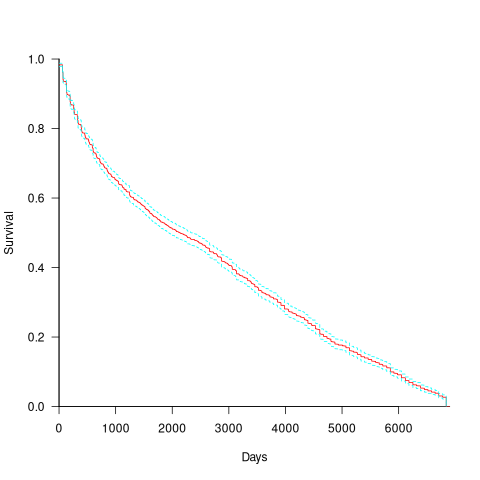
The survival curve appears to have two parts: the steeper decline during the first 1,000 days, followed by a slower, constant decline out to 16+ years.
Some good news is that many of these CVEs are likely to be in components that would not be installed in a safety critical application.
Recent Comments