Quantity of source in a given language
How much source code exists in a particular language?
Traditionally, indicators of the quantity of source in a language is the number of people making a living working on software written in the language. Job adverts are a proxy for the number of people employed to write/support programs implemented in a language (i.e., number of times a language is specified in the text of an advert), another proxy used to be the financial wellbeing of compiler vendors (many years ago, Open source compilers drove most companies out of the business of selling compilers).
Current job adverts are a measure of the code that likely to be worked now and in the near future. While Cobol dominated the job adverts decades ago, it is only occasionally seen today, suggesting that a lot of Cobol source is no longer actively used.
There now exists a huge quantity of Open source, and it has permeated into all the major, and many minor, software ecosystems. As a measure of all existing source code, how representative is Open source?
The Software Heritage’s mission statement “… is to collect, preserve, and share all software that is publicly available in source code form.” With over  files, as of July 2023 it is the largest available collection of Open source, and furthermore the BigCode project has collated this source into 658 constituent languages, known the Stack version 2.
files, as of July 2023 it is the largest available collection of Open source, and furthermore the BigCode project has collated this source into 658 constituent languages, known the Stack version 2.
To be representative of all existing source code, the Stack v2 would need to contain a representative sample of source written in all the languages that have been used to implement a non-trivial quantity of code. The plot below shows the number of source files assumed to be from a given year, storage by the Software Heritage; green lines are fitted exponentials (code+data):
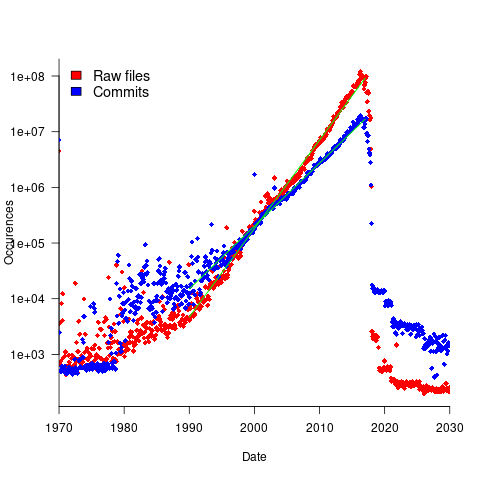
Less Open source was written in years gone by because there were fewer developers writing code, and code tends to get lost.
The Wikipedia list of programming languages currently contains links to articles on 682 languages, although some entries do appear to stretch the definition of programming language, e.g., Geometric Description Language. The Stack v2 contains code in 658 languages. However, even the broadest definition of programming language would not include some of the entries, e.g., Vim Help File. There are 176 language names shared between lists (around 27%; code+data).
Wikipedia languages not contained in Stack v2 include dialects of Basic, C, Lisp, Pascal, and shell, along with languages I recognised. Stack v2 languages not contained in the Wikipedia list include a variety of build and configuration files, names I did not recognise and what looked like documentation and data files.
Stack v2 has a broad brush approach to language classification. There is only one Pascal (perhaps the most widely used language in the early days of the IBM PC, Turbo Pascal, does not get a mention, and neither does UCSD Pascal), and assembler languages can vary a lot between cpus (Stack v2 lists: Assembly, Motorola 68K Assembly, Parrot Assembly, WebAssembly, Unix Assembly).
The Online Historical Encyclopaedia of Programming Languages lists information on 8,945 languages. Most of these probably got no further than being implemented in themselves by the language designer (often for a PhD thesis).
The Stack v2’s definition of a non-trivial quantity is at least 1,000 files having a given filename suffix, e.g., .cpp denoting C++ source. I can understand that this limit might exclude some niche languages from long ago (e.g., Coral 66), but why isn’t there any Algol 60 source?
I suspect that many ‘earlier’ languages are not included because the automated source submission process requires that the code be accessible via one of five version control systems. A lot of older source is stored in tar/zip files, accessed via ftp directories or personal web pages. Software Heritage’s Collect and Curate Legacy Code does not yet appear to provide a process for submitting source available in these forms.
While I think that Open source code has the same language usage characteristics as Closed source, I continue to meet people who question this assumption. I doubt that the question will ever get a definitive answer, not least because of an unwillingness to invest the resources needed to do a large sample comparison.
I would expect there to be at least 100 times as much Closed source as Open source, if only because there are a lot more people writing Closed source.
Recent Comments