Percolation of the impact of coding mistakes through a program
Programs containing serious coding mistakes can sometimes work surprisingly well. Experienced developers invariably have a story to tell about a program in production use that contained a coding mistake so bad, that it should have prevented the program producing any reliably output. My story relates to a Z80 cpu emulator I had written, which was successfully booting/running CP/M and several applications. One application was sometimes behaving erratically. I eventually traced the problem to the implementation of one of the add instructions (there are 13 special cases), which had been cut/pasted from the implementation of the corresponding subtract instruction, except that I had forgotten to change the result calculation from using a subtract to using an add, i.e., the instruction was performing a subtract, not an add. I was flabbergasted that so much emulated code appeared to be working in the presence of what to me was a crippling coding mistake.
There have been a handful of studies investigating the ability of programs containing coding mistakes to function correctly, or at least well enough to be usable.
- The earliest paper I have found is from 2005; Rinard, Cadar and Nguyen changed the termination condition of 326
for-loopsin the Pine email client, with<becoming<=, and>becoming>=. While the resulting program exhibited obvious anomalies, the researchers were able to use it to send and receive email, - a study by Danglot, Preux, Baudry and Monperrus investigated the propagation of single perturbations in 10 short Java programs (42 to 568 LOC, perturbed by adding/subtracting 1 from an expression somewhere in the code). The plot below shows the likelihood that a perturbation at some point in the code will have no impact on the output; code+data,

- a study by Cho of the impact of soft errors (i.e., radiation induced bit-flips) found that over 80% of bit-flips had no detectable impact on program behavior.
This week I attended the 63rd CREST Open Workshop; the topic was genetic improvement of software, i.e., GI randomly combines members of a population of programs, only keeping the children that pass some fitness test, rinses and repeats until one or more programs reach some acceptance threshold.
The GI community recently discovered that program output is often unaffected by a small perturbation to program execution, e.g., randomly adding one to the result of a binary operation.
A study by Langdon, Al-Subaihin and Clark tracked the effect of perturbations in the evaluation of an expression tree. The expression trees were created using genetic programming, with the fitness function being the difference between the value obtained by evaluating the expression tree and a sixth order polynomial. The binary operators in the expression tree were multiply and addition, with the leaf node value, x, taking a value between -0.97789 and 0.979541; the trees were a lot deeper than the one below, containing between 8.9k and 863k nodes/leafs, with tree depth varying from 121 to 5,103.
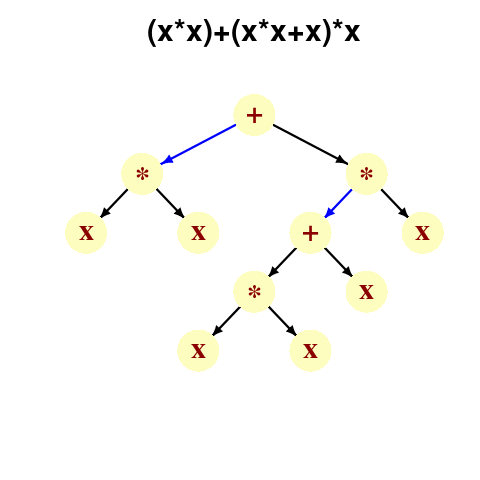
During the evaluation of an expression tree the result of one of the multiply/add operations was perturbed by adding one to its value. The subsequent evaluation of the remainder of the expression tree was tracked, comparing original/perturbed calculated values until either the root node was reached (and the final result was different), or the original/perturbed subtree result values synchronized, i.e., became the same. The distance, in nodes, between perturbation and value synchronization was recorded.
In all, ten expression trees were created, and each node in every tree was perturbed once per run; there were 10 runs using 10 different values of x.
The plot below shows results from two expression trees (different colors). Each point is the distance before original/perturbed values synchronised (for those cases where this happened) against the number of runs having this distance (for the same tree; code+data, and thanks to Bill for explaining things):
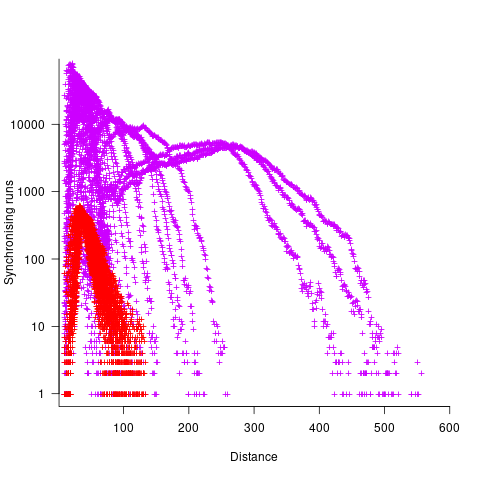
For the larger tree, there is a distinct pattern for each of the ten input values, x. This shows that synchronisation distance can be affected by the input value (which is to be expected). Perhaps this pattern is not present in the smaller tree, or the points are too close together to see it.
The opportunities available to a perturbation for travelling some distance depends on the size and characteristics of the expression tree, with a large thin tree providing more opportunities for longer distance travel than a large bushy tree.
It will take some well thought through experiments to unpick the contributions made by the tree characteristics, problem characteristics, and the prevalence of binary operators unlikely to be affected by small changes to their operand value, e.g., there is roughly a 50% chance that a relational comparison will be unaffected by a small change to one of its operands.
If you know of any other studies investigating coding mistake percolation, please let me know.
Recent Comments