Impact of number of files on number of review comments
Code review is often discussed from the perspective of changes to a single file. In practice, code review often involves multiple files (or at least pull-based reviews do), which begs the question: Do people invest less effort reviewing files appearing later?
TLDR: The number of review comments decreases for successive files in the pull request; by around 16% per file.
The paper First Come First Served: The Impact of File Position on Code Review extracted and analysed 219,476 pull requests from 138 Java projects on Github. They also ran an experiment which asked subjects to review two files, each containing a seeded coding mistake. The paper is relatively short and omits a lot of details; I’m guessing this is due to the page limit of a conference paper.
The plot below shows the number of pull requests containing a given number of files. The colored lines indicate the total number of code review comments associated with a given pull request, with the red dots showing the 69% of pull requests that did not receive any review comments (code+data):
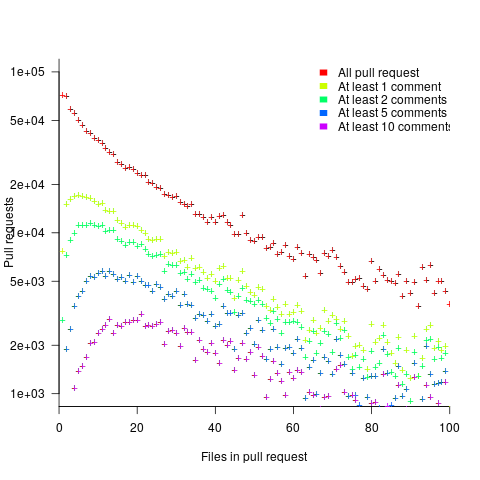
Many factors could influence the number of comments associated with a pull request; for instance, the number of people commenting, the amount of changed code, whether the code is a test case, and the number of files already reviewed (all items which happen to be present in the available data).
One factor for which information is not present in the data is social loafing, where people exert less effort when they are part of a larger group; or at least I did not find a way of easily estimating this factor.
The best model I could fit to all pull requests containing less than 10 files, and having a total of at least one comment, explained 36% of the variance present, which is not great, but something to talk about. There was a 16% decline in comments for successive files reviewed, test cases had 50% fewer comments, and there was some percentage increase with lines added; number of comments increased by a factor of 2.4 per additional commenter (is this due to importance of the file being reviewed, with importance being a metric not present in the data).
The model does not include information available in the data, such as file contents (e.g., Java, C++, configuration file, etc), and there may be correlated effects I have not taken into account. Consequently, I view the model as a rough guide.
Is the impact of file order on number of comments a side effect of some unrelated process? One way of showing a causal connection is to run an experiment.
The experiment run by the authors involved two five files, each with the first and last containing one seeded coding mistake. The 102 subjects were asked to review the two five files, with mistake file order randomly selected. The experiment looks well-structured and thought through (many are not), but the analysis of the results is confused.
The good news is that the seeded coding mistake in the first file was much more likely to be detected than the mistake in the second last file, and years of Java programming experience also had an impact (appearing first had the same impact as three years of Java experience). The bad news is that the model (a random effect model using a logistic equation) explains almost none of the variance in the data, i.e., these effects are tiny compared to whatever other factors are involved; see code+data.
What other factors might be involved?
Most experiments show a learning effect, in that subject performance improves as they perform more tasks. Having subjects review many pairs of files would enable this effect to be taken into account. Also, reviewing multiple pairs would reduce the impact of random goings-on during the review process.
The identity of the seeded mistake did not have a significant impact on the model.
Review comments are an important issue which is amenable to practical experimental investigation. I hope that the researchers run more experiments on this issue.
(I haven’t looked at the paper in detail yet … just a skim…)
The paper, when discussing how they looked at complementary evidence, didn’t say much about how they chose _which_ open-source projects they chose (other than “star-count”) or _which_ PRs within that project.
And another confounding factor _might_ be that this data is from _public_ repositories. Behavior of developers when doing code reviews (on PRs or otherwise) in private repositories might be different.
These things might introduce bias because of project-specific participant behavior _not_ reflected directly in PR comments. For example, projects may not have a practice of _closing_ abandoned PRs. Or there may be other channels to discuss – even _review_ – a PR outside of comments on the PR itself (e.g., Slack/Telegram/Teams/email) that cause PRs to get revised by their author.
For example, it many companies I’ve worked at it is common practice, when you see a PR that is too bit/complicated/tricky/not-really-necessary-for-current-sprint to review you just walk up to the perp in question and tell him to revise it/SPLIT IT UP into multiple PRs/stop working on it until some OTHER work that will cause major problems or resolve major issues with THIS PR gets checked in/abandon it altogether.
Nevertheless, I agree with the basic result, based on my observations of my own behavior and that of my peers in PRs/code reviews I’ve done/reviewed.
I think work could be done by the creators of various review tools (not just the built-in ones that Github/Gitlab/Bitbucket provide) on file order specifically. Even aside from things like presenting some files in _random_ order to alleviate the issue discussed here, but more. Pretty much the _only_ way review tools (that I’ve seen, and I’ve seen a bunch) _ever_ present files is in the hierarchical source file system view – sorted depth-first and alphabetically at each level of the tree. And this is _most often_ the _least_ useful order in which to review files. For example, in _my_ experience of my _own_ behavior – it is annoying and off-putting and even discouraging to be faced with a bunch of files to review at _the top of the review_ that are basically _irrelevant_ – file types that _don’t really need_ to be reviewed yet may have a lot of changes. Another thing is reviewing “detail” files before reviewing the “overall”/”big picture”/”organizing”/”motivating” files. (I frequently put a “review files in this order” list in the opening PR comment for my own large PRs for this reason.) Because it is human nature to just review the files in the order they’re presented – even though “depth-first alphabetically” is just an easy decision for the _tool implementer_ and has _nothing to do_ with the _content_ of the code.
(I guess what I implied but forgot to explicitly say in my previous comment is that this out-of-band commenting/reviewing of PRs – which would be a project/repo-specific thing – might bias results by leaving out there a bunch of PRs that were only commented in-band by a subset of reviewers – maybe even the least skilled reviewers (because the more skilled reviewers went directly to the author and gave feedback face-to-face.))
@David Bakin
Star count is a widely used research metric for selecting non-trivial Github repos.
Open source repositories have their problems, not least of which being that any Joe Smoe can make a ‘contribution’. This has a big impact on the quality of fault report data, but probably has a lot less impact on pull requests.
With regard to out of band requests, it has been found that serious faults sometimes/often get handled via email, rather than the normal channels.
A lot of the research is machine learning based, i.e., chuck some data into a learner, push some buttons, and write some techno babble. Predicting which pull requests will be accepted is a common question.
The paper Pull Request Decisions Explained: An Empirical Overview looks interesting, but I have not had time to go through it. The author has done other interesting work in this area.