Archive
2021 in the programming language standards’ world
Last Tuesday I was on a Webex call (the British Standards Institute’s use of Webex for conference calls predates COVID 19) for a meeting of IST/5, the committee responsible for programming language standards in the UK.
There have been two developments whose effect, I think, will be to hasten the decline of the relevance of ISO standards in the programming language world (to the point that they are ignored by compiler vendors).
- People have been talking about switching to online meetings for years, and every now and again someone has dialed-in to the conference call phone system provided by conference organizers. COVID has made online meetings the norm (language working groups have replaced face-to-face meetings with online meetings). People are looking forward to having face-to-face meetings again, but there is talk of online attendance playing a much larger role in the future.
The cost of attending a meeting in person is the perennial reason given for people not playing an active role in language standards (and I imagine other standards). Online attendance significantly reduces the cost, and an increase in the number of people ‘attending’ meetings is to be expected if committees agree to significant online attendance.
While many people think that making it possible for more people to be involved, by reducing the cost, is a good idea, I think it is a bad idea. The rationale for the creation of standards is economic; customer costs are reduced by reducing
diversityincompatibilities across the same kind of product., e.g., all standard conforming compilers are consistent in their handling of the same construct (undefined behavior may be consistently different). When attending meetings is costly, those with a significant economic interest tend to form the bulk of those attending meetings. Every now and again somebody turns up for a drive-by-shooting, i.e., they turn up for a day to present a paper on their pet issue and are never seen again.Lowering the barrier to entry (i.e., cost) is going to increase the number of drive-by shootings. The cost of this spray of pet-issue papers falls on the regular attendees, who will have to spend time dealing with enthusiastic, single issue, newbies,
- The International Organization for Standardization (ISO is the abbreviation of the French title) has embraced the use of inclusive terminology. The ISO directives specifying the Principles and rules for the structure and drafting of ISO and IEC documents, have been updated by the addition of a new clause: 8.6 Inclusive terminology, which says:
“Whenever possible, inclusive terminology shall be used to describe technical capabilities and relationships. Insensitive, archaic and non-inclusive terms shall be avoided. For the purposes of this principle, “inclusive terminology” means terminology perceived or likely to be perceived as welcoming by everyone, regardless of their sex, gender, race, colour, religion, etc.
New documents shall be developed using inclusive terminology. As feasible, existing and legacy documents shall be updated to identify and replace non-inclusive terms with alternatives that are more descriptive and tailored to the technical capability or relationship.”
The US Standards body, has released the document INCITS inclusive terminology guidelines. Section 5 covers identifying negative terms, and Section 6 deals with “Migration from terms with negative connotations”. Annex A provides examples of terms with negative connotations, preceded by text in bright red “CONTENT WARNING: The following list contains material that may be harmful or
traumatizing to some audiences.”“Error” sounds like a very negative word to me, but it’s not in the annex. One of the words listed in the annex is “dummy”. One member pointed out that ‘dummy’ appears 794 times in the current Fortran standard, (586 times in ‘dummy argument’).
Replacing words with negative connotations leads to frustration and distorted perceptions of what is being communicated.
I think there will be zero real world impact from the use of inclusive terminology in ISO standards, for the simple reason that terminology in ISO standards usually has zero real world impact (based on my experience of the use of terminology in ISO language standards). But the use of inclusive terminology does provide a new opportunity for virtue signalling by members of standards’ committees.
While use of inclusive terminology in ISO standards is unlikely to have any real world impact, the need to deal with suggested changes of terminology, and new terminology, will consume committee time. Most committee members tend to a rather pragmatic, but it only takes one or two people to keep a discussion going and going.
Over time, compiler vendors are going to become disenchanted with the increased workload, and the endless discussions relating to pet-issues and inclusive terminology. Given that there are so few industrial strength compilers for any language, the world no longer needs formally agreed language standards; the behavior that implementations have to support is controlled by the huge volume of existing code. Eventually, compiler vendors will sever the cord to the ISO standards process, and outside the SC22 bubble nobody will notice.
Estimating using a granular sequence of values
When asked for an estimate of the time needed to complete a task, should developers be free to choose any numeric value, or should they be restricted to selecting from a predefined set of values (e.g, the Fibonacci numbers, or T-shirt sizes)?
Allowing any value to be chosen would appear to provide the greatest flexibility to make an accurate estimate. However, estimating is an intrinsically uncertain process (i.e., the future is unknown), and it is done by people with varying degrees of experience (which might be used to help guide their prediction about the future).
Restricting the selection process to one of the values in a granular sequence of numbers has several benefits, including:
- being able to adjust the gaps between permitted values to match the likely level of uncertainty in the task effort, or the best accuracy resolution believed possible,
- reducing the psychological stress of making an estimate, by explicitly giving permission to ignore the smaller issues (because they are believed to require a total effort that is less than the sequence granularity),
- helping to maintain developer self-esteem, by providing a justification when an estimate turning out to be inaccurate, e.g., the granularity prevented a more accurate estimate being made.
Is there an optimal sequence of granular values to use when making task estimates for a project?
The answer to this question depends on what is attempting to be optimized.
Given how hard it is to get people to produce estimates, the first criterion for an optimal sequence has to be that people are willing to use it.
I have always been struck by the ritualistic way in which the Fibonacci sequence is described by those who use it to make estimates. Rituals are an effective technique used by groups to help maintain members’ adherence to group norms (one of which might be producing estimates).
A possible reason for the tendency to use round numbers might estimate-values is that this usage is common in other social interactions involving numeric values, e.g., when replying to a request for the time of day.
The use of round numbers, when developers have the option of selecting from a continuous range of values, is a developer imposed granular sequence. What form do these round number sequences take?
The plot below shows the values of each of the six most common round number estimates present in the BrightSquid, SiP, and CESAW (project 615) effort estimation data sets, plus the first six Fibonacci numbers (code+data):
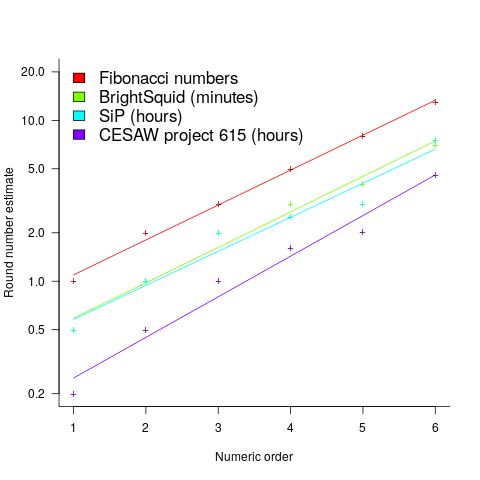
The lines are fitted regression models having the form:  (there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
(there is a small variation in the value of the constant; the smallest value for project 615 was probably calculated rather than being human selected).
This plot shows a consistent pattern of use across multiple projects (I know of several projects that use Fibonacci numbers, but don’t have any publicly available data). Nothing is said about this pattern being (near) optimal in any sense.
The time unit of estimation for this data was minutes or hours. Would the equation have the same form if the time unit was days, would the constant still be around  . I await the data needed to answer this question.
. I await the data needed to answer this question.
This brief analysis looked at granular sequences from the perspective of the distribution of estimates made. Perhaps it makes more sense to base a granular estimation sequence on the distribution of actual task effort. A topic for another post.
What is known about software effort estimation in 2021
What do we know about software effort estimation, based on evidence?
The few publicly available datasets (e.g., SiP, CESAW, and Renzo) involve (mostly) individuals estimating short duration tasks (i.e., rarely more than a few hours). There are other tiny datasets, which are mostly used to do fake research. The patterns found across these datasets include:
- developers often use round-numbers,
- the equation:
 , where
, where  is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,
is a constant that varies between projects, often explains around 50% of the variance present in the data. This equation shows that developers under-estimate short tasks and over-estimate long tasks. The exponent,  , applies across most projects in the data,
, applies across most projects in the data, - individuals tend to either consistently over or under estimate,
- developer estimation accuracy does not change with practice. Possible reasons for this include: variability in the world prevents more accurate estimates, developers choose to spend their learning resources on other topics.
Does social loafing have an impact on actual effort? The data needed to answer this question is currently not available (the available data mostly involves people working on their own).
When working on a task, do developers follow Parkinson’s law or do they strive to meet targets?
The following plot suggests that one or the other, or both are true (data):
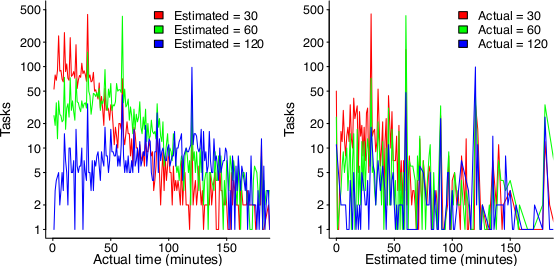
On the left: Each colored lines shows the number of tasks having a given actual implementation time, when they were estimated to take 30, 60 or 120 minutes (the right plot reverses the role of estimate/actual). Many of the spikes in the task counts are at round numbers, suggesting that the developer has fixated on a time to finish and is either taking it easy or striving to hit it. The problem is distinguishing them mathematically; suggestions welcome.
None of these patterns of behavior appear to be software specific. They all look like generic human behaviors. I have started emailing researchers working on project analytics in other domains, asking for data (no luck so far).
Other patterns may be present for many projects in the existing data, we have to wait for somebody to ask the right question (if one exists).
It is also possible that the existing data has some unusual characteristics that don’t apply to most projects. We won’t know until data on many more projects becomes available.
Production of software may continue to be craft based
Andrew Carnegie made his fortune in the steel industry, and his autobiography is a fascinating insight into the scientific vs. craft/folklore approach to smelting iron ore. Carnegie measured the processes involved in smelting; he tracked the input and outputs involved in the smelting process, and applied the newly available scientific knowledge (e.g., chemistry) to minimize the resources needed to extract iron from ore. Other companies continued to treat Iron smelting as a suck-it-and-see activity, driven by personal opinion and the application of techniques that had worked in the past.
The technique of using what-worked-last-time can be a successful strategy when the variability of the inputs is low. In the case of smelting Iron there was a lot of variability in the Iron ore, Limestone and Coke fed into the furnaces. The smelting companies in Carnegie’s day ‘solved’ this input variability problem by restricting their purchase of raw materials to mines that delivered material that worked last time.
Hiring an experienced chemist (the only smelting company to do so), Carnegie found out that the quality of ore (i.e., percentage Iron content) in some mines with a high reputation was much lower than the ore quality of some mines with a low reputation; Carnegie was able to obtain a low price for high quality ore because other companies did not appreciate its characteristics (and shunned using it). Other companies were unable to extract Iron from high quality ore because they stuck to using a process that worked for lower quality ore (the amount of Limestone and Coke added to the smelting process has to be adjusted based on the Iron content of the ore, otherwise the process may deliver poor results, or even fail to produce Iron; see chapter 13).
When Carnegie’s application of scientific knowledge, and his competitors’ opinion driven production, is combined with being a good businessman, it’s no surprise that Carnegie made a fortune from his Iron smelting business.
What are the parallels between iron smelting in Carnegie’s day and the software industry?
An obvious parallel is the industry dominance of opinion driven processes. But then, the lack of any scientific basis for the processes involved in building software systems would seem to make drawing parallels a pointless exercise.
Let’s assume that there was a scientific basis for some of the major processes involved in software engineering. Would any of these science-based processes be adopted?
The reason for using science based knowledge and mechanization is to reduce costs, which may lead to increased profits or just staying in business (in a Red Queen’s race).
Agriculture is an example of a business where science and mechanization dominate, and building construction is a domain where this has not happened. Perhaps building construction will become more mechanized when unknown missing components become available (mechanization was available for agricultural processes in the 1700s, but they did not spread for a century or two, e.g., threshing machines).
It’s possible to find parallels between software engineering and the smelting process, agriculture, and building construction. In fact, it parallels can probably be found between software engineering and any other major business domain.
Drawing parallels between software engineering and other major business domains creates a sense of familiarity. In practice, software is unlike most existing business domains in that software products are one-off creations of an intangible good, which has (virtually) zero cost of reproduction, while the economics of creating tangible goods (e.g., by smelting, sowing and reaping, or building houses) is all about reducing the far from zero cost of reproduction.
Perhaps the main take-away from the history of the production of tangible goods is that the scientific method has not always supplanted the craft approach to production.
Recent Comments