Archive
Beta release of data analysis chapters: Evidence-based software engineering
When I started my evidence-based software engineering book, nobody had written a data analysis book for software developers, so I had to write one (in fact, a book on this topic has still to be written). When I say “I had to write one”, what I mean is that the 200 pages in the second half of my evidence-based software engineering book contains a concentrated form of such a book.
This 200 pages is now on beta release (it’s 186 pages, if the bibliography is excluded); chapters 8 to 15 of the draft pdf. Originally I was going to wait until all the material was ready, before making a beta release; the Coronavirus changed my plans.
Here is your chance to learn a new skill during the lockdown (yes, these are starting to end; my schedule has not changed, I’m just moving with the times).
All the code+data is available for you to try out any ideas you might have.
The software engineering material, the first half of the book, is also part of the current draft pdf, and the polished form should be available on beta release in about 6 weeks.
If you have a comment or find a problem, either email me or raise an issue on the book’s Github page.
Yes, a few figures and tables still bump into each other. I’m loath to do very fine-tuning because things will shuffle around a bit with minor changes to the words.
I’m thinking of running some online sessions around each chapter. Watch this space for information.
Predicting the future with data+logistic regression
Predicting the peak of data fitted by a logistic equation is attracting a lot of attention at the moment. Let’s see how well we can predict the final size of a software system, in lines of code, using logistic regression (code+data).
First up is the size of the GNU C library. This is not really a good test, since the peak (or rather a peak) has been reached.
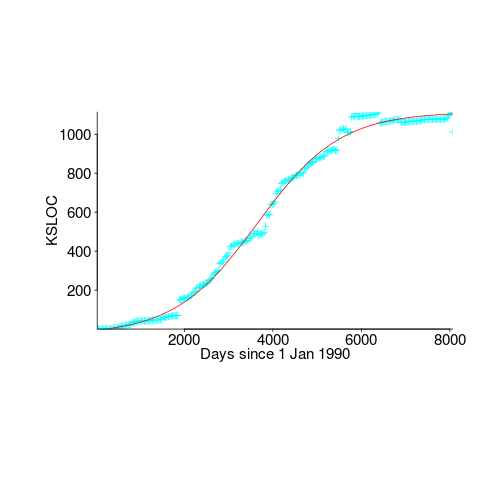
We need a system that has not yet reached an easily recognizable peak. The Linux kernel has been under development for many years, and lots of LOC counts are available. The plot below shows a logistic equation fitted to the kernel data, assuming that the only available data was up to day: 2,900, 3,650, 4,200, and 5,000+ (code+data). Can you tell which fitted line corresponds to which number of days?
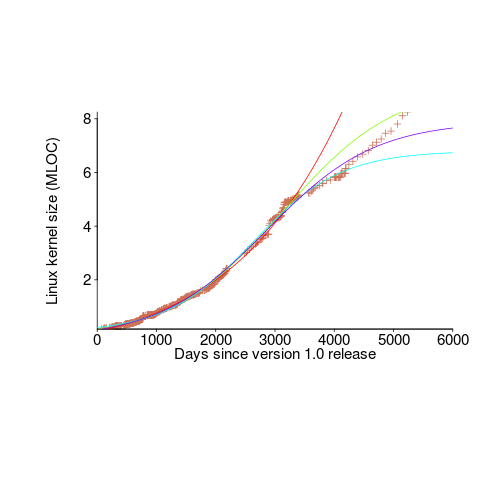
The underlying ‘problem’ is that we are telling the fitting software to fit a particular equation; the software does what it has been told to do, and fits a logistic equation (in this case).
A cubic polynomial is also a great fit to the existing kernel data (red line to the left of the blue line), and this fitted equation can be extended into future (to the right of the blue line); dotted lines are 95% confidence bounds. Do any readers believe the future size of the Linux kernel predicted by this cubic model?
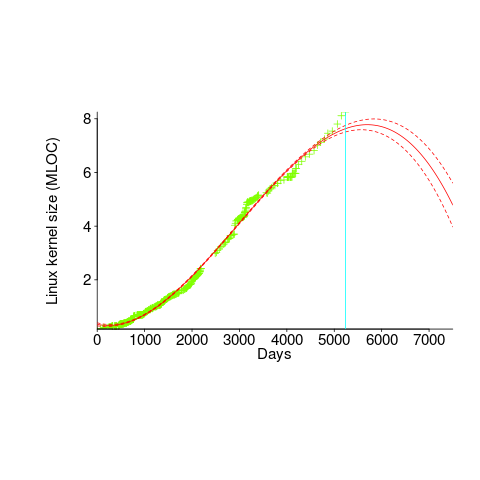
Predicting the future requires lots of data on the underlying processes that drive events. Modelling events is an iterative process. Build a model, check against reality, adjust model, rinse and repeat.
If the COVID-19 experience trains people to be suspicious of future predictions made by models, it will have done something positive.
Motzkin paths and source code silhouettes
Consider a language that just contains assignments and if-statements (no else arm). Nesting level could be used to visualize programs written in such a language; an if represented by an Up step, an assignment by a Level step, and the if-terminator (e.g., the } token) by a Down step. Silhouettes for the nine possible four line programs are shown in the figure below (image courtesy of Wikipedia). I use the term silhouette because the obvious terms (e.g., path and trace) have other common usage meanings.

How many silhouettes are possible, for a function containing  statements? Motzkin numbers provide the answer; the number of silhouettes for functions containing from zero to 20 statements is: 1, 1, 2, 4, 9, 21, 51, 127, 323, 835, 2188, 5798, 15511, 41835, 113634, 310572, 853467, 2356779, 6536382, 18199284, 50852019. The recurrence relation for Motzkin numbers is (where is the total number of steps, i.e., statements):
statements? Motzkin numbers provide the answer; the number of silhouettes for functions containing from zero to 20 statements is: 1, 1, 2, 4, 9, 21, 51, 127, 323, 835, 2188, 5798, 15511, 41835, 113634, 310572, 853467, 2356779, 6536382, 18199284, 50852019. The recurrence relation for Motzkin numbers is (where is the total number of steps, i.e., statements):
m_n = (2n+1)m_{n-1}+3(n-1)m_{n-2}")
Human written code contains recurring patterns; the probability of encountering an if-statement, when reading code, is around 17% (at least for the C source of some desktop applications). What does an upward probability of 17% do to the Motzkin recurrence relation? For many years, I have been keeping my eyes open for possible answers (solving the number theory involved is well above my mathematics pay grade). A few days ago, I discovered weighted Motzkin paths.
A weighted Motzkin path is one where the Up, Level and Down steps each have distinct weights. The recurrence relationship for weighted Motzkin paths is expressed in terms of number of colored steps, where:  is the number of possible colors for the Level steps, and
is the number of possible colors for the Level steps, and  is the number of possible colors for Down steps; Up steps are assumed to have a single color:
is the number of possible colors for Down steps; Up steps are assumed to have a single color:
m_n = d(2n+1)m_{n-1}+(4c-d^2)(n-1)m_{n-2}")
setting:  and
and  (i.e., all kinds of step have one color) recovers the original relation.
(i.e., all kinds of step have one color) recovers the original relation.
The different colored Level steps might be interpreted as different kinds of non-nesting statement sequences, and the different colored Down steps might be interpreted as different ways of decreasing nesting by one (e.g., a goto statement).
The connection between weighted Motzkin paths and probability is that the colors can be treated as weights that add up to 1. Searching on “weighted Motzkin” returns the kind of information I had been looking for; it seems that researchers in other fields had already discovered weighted Motzkin paths, and produced some interesting results.
If an automatic source code generator outputs the start of an if statement (i.e., an Up step) with probability  , an assignment (i.e., a Level step) with probability
, an assignment (i.e., a Level step) with probability  , and terminates the
, and terminates the if (i.e., a Down step) with probability  , what is the probability that the function will contain at least
, what is the probability that the function will contain at least  statements? The answer, courtesy of applying Motzkin paths in research into clone cell distributions, is:
statements? The answer, courtesy of applying Motzkin paths in research into clone cell distributions, is:
![P_n=sum{i=0}{delim{[}{(n-2)/2}{]}}(matrix{2}{1}{{n-2} {2i}})C_{2i}a^{i}b^{n-2-2i}c^{i+1}](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_960.5_57086dac25a2ff31c2230f0791800e35.png "P_n=sum{i=0}{delim{[}{(n-2)/2}{]}}(matrix{2}{1}{{n-2} {2i}})C_{2i}a^{i}b^{n-2-2i}c^{i+1}")
where:  is the
is the  ‘th Catalan number, and that
‘th Catalan number, and that [...] is a truncation; code for an implementation in R.
In human written code we know that  , because the number of statements in a compound-statement roughly has an exponential distribution (at least in C).
, because the number of statements in a compound-statement roughly has an exponential distribution (at least in C).
There has been some work looking at the number of peaks in a Motzkin path, with one formula for the total number of peaks in all Motzkin paths of length n. A formula for the number of paths of length , having  peaks, would be interesting.
peaks, would be interesting.
Motzkin numbers have been extended to what is called higher-rank, where Up steps and Level steps can be greater than one. There are statements that can reduce nesting level by more than one, e.g., breaking out of loops, but no constructs increase nesting by more than one (that I can think of). Perhaps the rather complicated relationship can be adapted to greater Down steps.
Other kinds of statements can increase nesting level, e.g., for-statements and while-statements. I have not yet spotted any papers dealing with the case where an Up step eventually has a corresponding Down step at the appropriate nesting level (needed to handle different kinds of nest-creating constructs). Pointers welcome. A related problem is handling if-statements containing else arms, here there is an associated increase in nesting.
What characteristics does human written code have that results in it having particular kinds of silhouettes? I have been thinking about this for a while, but have no good answers.
If you spot any Motzkin related papers that you think could be applied to source code analysis, please let me know.
Update
A solution to the Number of statement sequences possible using N if-statements problem.
Comments on the COVID-19 model source code from Imperial
At the end of March a paper modelling the impact of various scenarios on the spread of COVID-19 infections, by the MRC Centre for Global Infectious Disease Analysis at Imperial College, appears to have influenced the policy of the powers that be. This group recently started publishing their modelling code on GitHub (good for them).
Most of my professional life has been spent analyzing other peoples’ code, for one reason or another (mostly Fortran, then Pascal, and then C). I had heard that the Imperial software was written in C, but the released code is written in R (as of six hours ago, there is the start of a Python version). Ok, I can work with R, but my comments will be general, since I don’t have lots of in depth experience reading R code.
The code comes from a research context, and is evolving, i.e., some amount of messiness is to be expected.
There is not a lot of code to talk about (248 lines setting things up, 111 lines for a Stan model, 371 lines of plotting code, and 85 lines of utility code). The analysis is performed by creating a model using the Stan statistical inference language (in which the high level structure of the problem is specified, compiled to a lower level form and then run; the Stan language is very similar to R). These days, lots of problems are coded using a relatively small number of lines that call fancy libraries to do the heavy lifting. It is becoming rare to have to write tens of thousands of lines of code to solve a problem.
I have two points to make about the code, all designed to reduce the likelihood of mistakes being made by the person working on the source. These points mainly apply to the Stan code, because that is where the important stuff happens, but are equally applicable to all code.
- Numeric literals are embedded in the code, values include:
2.4,1.0,0.5,0.03,1e-5, and1e-9. These values obviously mean something to the person who wrote the code, and they can probably be interpreted by experts in the spread of virus infections. But why are they scattered about the code, rather than appearing together (as a sequence of assignments to variables with meaningful names)? Having all the constants in one place makes it easier to spot when a mistake has been made, e.g., one value has been changed without a corresponding change in another value; it also makes it easier for people new to the code to figure out what is going on, - when commenting out code, make it very obvious, e.g., have
/**********************on its own line, and*****************************/on its own line. Using just/*and*/makes it easy to miss that code has been commented out.
Why have they started a Python implementation? Perhaps somebody on the team is more comfortable working with Python (when deadlines loom, it is always best to go with what you know).
Having both an R and Python version is good, in that coding mistakes are likely to show up as inconsistencies in the results produced. It’s always good to have the output of two independently written programs to compare (apart from the fact it may cost twice as much).
The README mentions performance issues. I imagine that most of the execution time is spent in the Stan code, so R vs. Python is not a performance issue.
Any reader with expertise tuning Stan models for performance might like to check out the code. I’m sure the Imperial folk would be happy to hear about worthwhile speed-ups.
Update
The R source code of the EuroMOMO model, which aims to “… explain number of deaths by a baseline, influenza activity and extreme ambient temperature.”
Recent Comments