Source code has a brief and lonely existence
The majority of source code has a short lifespan (i.e., a few years), and is only ever modified by one person (i.e., 60%).
Literate programming is all well and good for code written to appear in a book that the author hopes will be read for many years, but this is a tiny sliver of the source code ecosystem. The majority of code is never modified, once written, and does not hang around for very long; an investment is source code futures will make a loss unless the returns are spectacular.
What evidence do I have for these claims?
There is lots of evidence for the code having a short lifespan, and not so much for the number of people modifying it (and none for the number of people reading it).
The lifespan evidence is derived from data in my evidence-based software engineering book, and blog posts on software system lifespans, and survival times of Linux distributions. Lifespan in short because Packages are updated, and third-parties change/delete APIs (things may settle down in the future).
People who think source code has a long lifespan are suffering from survivorship bias, i.e., there are a small percentage of programs that are actively used for many years.
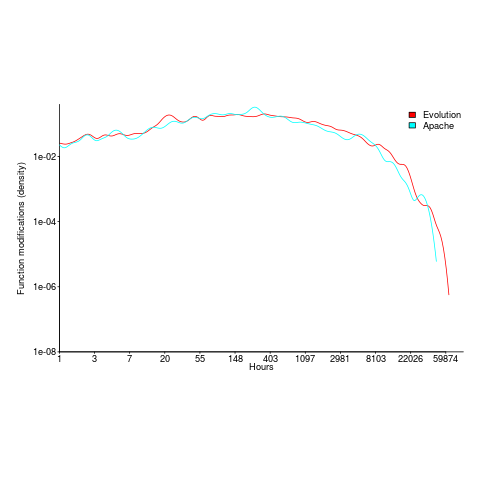
Around 60% of functions are only ever modified by one author; based on a study of the change history of functions in Evolution (114,485 changes to functions over 10 years), and Apache (14,072 changes over 12 years); a study investigating the number of people modifying files in Eclipse. Pointers to other studies that have welcome.
One consequence of the short life expectancy of source code is that, any investment made with the expectation of saving on future maintenance costs needs to return many multiples of the original investment. When many programs don’t live long enough to be maintained, those with a long lifespan have to pay the original investments made in all the source that quickly disappeared.
One benefit of short life expectancy is that most coding mistakes don’t live long enough to trigger a fault experience; the code containing the mistake is deleted or replaced before anybody notices the mistake.
Update: a few days later
I was remiss in not posting some plots for people to look at (code+data).
The plot below shows number of function, in Evolution, modified a given number of times (left), and functions modified by a given number of authors (right). The lines are a bi-exponential fit.

What is the interval (in hours) between between modifications of a function? The plot below has a logarithmic x-axis, and is sort-of flat over most of the range (you need to squint a bit). This is roughly saying that the probability of modification in hours 1-3 is the same as in hours 3-7, and hours, 7-15, etc (i.e., keep doubling the hour interval). At round 10,000 hours function modification probability drops like a stone.
I’m not sure you have enough data to make the claim that “majority of source code has a short lifespan (i.e., a few years), and is only ever modified by one person.” Google is famous for trying a bunch of things and ruthlessly culling unsuccessful projects so I’m not sure that data is representative of our industry as a whole. Linux distros are also suspects for being non-representative.
In my work experience, code lives for many, many years. And, if I had to guess, I’d say over the last 20 years I’ve spent about 70% of my time modifying existing code and 30% writing new code.
Do you think you might reach a different conclusion if you “magically” had access to a truly random sample of all software? For web, example embedded, IT systems, banking systems, militarily systems, government systems, etc.? Is it possible that your conclusion is colored by availability bias?
I’m also curious about your thoughts on creating a self fulfilling prophecy. If developers de-prioritize maintainability isn’t that going to force those systems to be scrapped sooner rather than later because they are difficult to maintain?
@Blaine
Google certainly has a high turnover in supported services; the IBM data in the same post shows a much slower turnover (perhaps these are the two extremes for today’s world).
The uses of software is still expanding, and 50 years from now the rate of change is likely to be much lower.
Nearly all the lifespan data is based on open source projects. How representative are these of closed source projects? I have certainly worked on lots of software that did not last many years, and one system that is still being used (I don’t know how much of my code remains).
I know of many banking systems that have had a lifetime of a year or two, or never actually went live.
One open source project that appears to have stabilized is the GNU C library. This is because it has been around for so long, and the functions that need to be supported don’t change much.
The results are certainly biased by availability. I am dependent on availability of research data, and researchers are dependent on availability of source code.
Maintenance is already de-prioritized by management because they know fickleness of the world in which they operate.
Many of the claims of ‘improving maintainability’ are pure arm waving. Evidence for doing this-that or the-other to improve maintainability is very thin on the ground. It’s all personal opinion.
Extrapolating from Evolution/Eclipse to the entire industry does not seem reasonable to me. A quick perusal of company logs seems to suggest otherwise but then, we produce embedded code expected to run for a while.
@Nemo
The analysis has to start somewhere, and yes more data is needed.
I imagine that your company source control contains lots of individual developer code that may or may not make it into a company product (that is the nature of development). Once part of a company product, code is likely to attract more developers making changes.
What percentage of individual developer code makes it into a product that is shipped? This is the question companies need to answer when providing cost/benefit guidelines for their developers regarding upfront investment in code.
Derek,
A thought provoking post. I’ve heard (read?) you say before that most code doesn’t last and its something I’ve never really worked through the full implications of.
Your post generate more questions in my mind than answers. Maybe you have some answers?
To start with, you mention that most code is only changed by one programmer. I wonder, if the reverse true? – how many pieces of code does one programmer work on?
One would assume that most programmers work on the same sections of code again and again. But does that mean they only work on their “own” parts? – or do they range into others.
That statistically “one programmer works on one piece of code” is true does not tell us whether this is a good thing or a bad thing. Is this something to accept and encourage? Or something to work against?
Which raises the question of code quality: is it better where the changes come from one brain or many?
– although the difficulty defining “code quality” and “better” is probably make this hard to answer
I’m also trying to reconcile “most code doesn’t last” with the power law distribution of code changes – introduced to me by James Noble but he may not have originated it, I think Les Hatton has some work on it too.
This suggests that while some code changes very frequently other code goes a long time without changes. Right now I believe both your finding and the power law distribution to be true and I’m trying to work out how these two fit together.
I wonder if there is a code-lifecycle to be observed?
For example: in the first instance code is written, over a relatively short period of time the code is revisited, changed, and even totally replace severn times.
Say it takes 10 rewrites to get the code stable within a year. After that the code “works” and isn’t touched for years. Statistically you would be correct: 9 out of 10 pieces of code haven’t lived very long. Yet the power law will still hold because initially that code was in the “changes a lot” section and over time the final code migrates to the long tail.
Please keep up the good work!
Right after posting that comment two more thoughts occurred to me.
Any data you have on the life expectancy of code is certainly biased to show longer life expectancy than is actually the case. Any snapshot of a code base (e.g. a git repository, a Linux distribution) only shows the code which was deemed good enough to check-in or ship. In getting code to that state programmers write and discard code along the way – only in text books does perfect code get written in a single pass!
What is actually being demonstrated is the organic nature of software.
Which brings me to point 2, this may of occurred to me as happened to be walking in Kew Gardens.
Nature replaces itself: the life expectancy of a tree leaf is – at a guess – half a year.
I quick search tells me that human blood cells last for about 3 months (https://stanfordbloodcenter.org/how_long_do_red/) while some other human tells last many years.
What interests me is less hot long any given set of lines-of-code lasts but how long the system as a whole lasts. Its entirely possible that over a few years every line of Linux will be replaced (in the same way my body replaces cells) but the overall system remains the same (like my body).
Perhaps the question one should be asking is: in a world were code is transient (soft!) how can we make the transition easier?
@Allan Kelly
How many pieces of code does a developer work on? An interesting question that I have never thought about. I will try and find out.
I have updated the post with some plots. When functions are the unit of measure, the best fitting plot is a bi-exponential (i.e., sum of two exponentials). Is there a power-law of code changes? I cannot recall one, will have a rummage around. As far as I know, Les has not done any work looking at Github commits (which is where most of this data comes from).
Developers, and development groups, vary in their commit habits. Some commit straight away, while others commit when the code is working. This means that code may be created and deleted without ever being recorded (in the version control system), and some code will be modified by more than one author without it being recorded (because they decided not to commit their work).
Software is worked on because there is an external need. The software world is still going through rapid changes, so there is lots of code churn. For instance, devices drivers generate much of the growth of Linux; take away new hardware and the need for more devices drivers goes away. Many decades from now I expect the rate of change to be slower.
The way to make transient easier is to stop worrying about future maintenance, which probably won’t happen. It’s likely to be cheaper to pay more maintaining the code that does survive.
@Blaine
There’s a distinction to be made between the amount of code actually modified by others a small percentage and the time they spent banging their heads trying to figure out what the heck the code does. Maintenance of bad code is time-consuming and doesn’t produce many modifications of the original code.
An interesting and thought-provoking article however like all conclusions based on any statistical analysis it is necessary to not read into the data more than it says. It is easy to try to see in the results what we think should be there without considering other alternatives as to why the data looks the way it does.
First of all, let me preface this by saying that I have personal anecdotal experience that code does have a short life span. Of several dozen projects I have work on in my career only a handful are still in active use and development. That being said, looking at statistics such as these and making such conclusions is only marginally better than my anecdotal experience.
I think it is important to separate the concept of software lifespan from the concept of software development life cycle. I think what you have actually captured in your data is not so much an analysis of the former but of the latter. Fundamentally software lifespan lives far outside the realm of source control systems.
I am not sure that function modification over time by either quantity or duration are very useful statistic for measuring source code life span. Putting these graphs in perspective it simply appears that you are pointing out the obvious. Many functions are written by one or two authors and then never modified again. This phenomenon really has nothing to do with the lifespan of the code and is an artifact of the software development lifecycle. Software is written, tested and fixed. Once a function does what it is supposed to, it need not be modified.
The claim that function modification probability “drops like a stone” around 10,000 hours further supports just this view. If we take the hours to simply mean age then 10,000 hours is slightly over 1 year. I am not at all surprised that this is the case. Given the release and testing cycles of many projects, it is easy to see how after about a year function modification or churn would ebb. As features are finalized and locked for a release function modification would naturally decline. Again once a function is written, tested and working why would it ever need to be modified. Of course, this doesn’t mean that the function is no longer used it just means that it has stabilized.
@Justin
Thanks for your extensive comment.
The plots at the bottom of the article are one part of the data. There is other data, linked to in the post, relating to code and system lifetime, e.g., the IBM and Google system lifetime data.
70% of your time, but how about your lines produced?
Having worked in corporate IT for 40 years, the lifespan of our code is measured in decades. Once it is written and running the business, there is little to no tolerance for change.
My experience in corporate sector is very similar – lifespan of our code is almost neve measured in less than few years and can be much more.