Archive
Medieval guilds: a tax collection bureaucracy
The medieval guild is sometimes held up as the template for an institution dedicated to maintaining high standards, and training the next generation of craftsmen.
“The European Guilds: An economic analysis” by Sheilagh Ogilvie takes a chainsaw (i.e., lots of data) to all the positive things that have been said about medieval guilds (apart from them being a money making machine for those on the inside).
Guilds manipulated markets (e.g., drove down the cost of input items they needed, and kept the prices they charged high), had little or no interest in quality, charged apprentices for what little training they received, restricted entry to their profession (based on the number of guild masters the local population could support in a manner expected by masters), and did not hesitate to use force to enforce the rules of the guild (should a member appear to threaten the livelihood of other guild members).
Guild wars is not the fiction of an online game, guilds did go to war with each other.
Given their focus on maximizing income, rather than providing customer benefits, why did guilds survive for so many centuries? Guilds paid out significant sums to influence those in power, i.e., bribes. Guilds paid annual sums for the exclusive rights to ply their trade in geographical areas; it’s all down on Vellum.
Guilds provided the bureaucracy needed to collect money from the populace, i.e., they were effectively tax collectors. Medieval rulers had a high turn-over, and most were not around long enough to establish a civil service. In later centuries, the growth of a country’s population led to the creation of government departments, that were stable enough to perform tax collecting duties more efficiently that guilds; it was the spread of governments capable of doing their own tax collecting that killed off guilds.
A zero-knowledge proofs workshop
I was at the Zero-Knowledge proofs workshop run by BinaryDistict on Monday and Tuesday. The workshop runs all week, but is mostly hacking for the remaining days (hacking would be interesting if I had a problem to code, more about this at the end).
Zero-knowledge proofs allow person A to convince person B, that A knows the value of x, without revealing the value of x. There are two kinds of zero-knowledge proofs: an interacting proof system involves a sequence of messages being exchanged between the two parties, and in non-interactive systems (the primary focus of the workshop), there is no interaction.
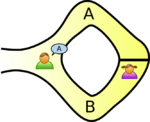
The example usually given, of a zero-knowledge proof, involves Peggy and Victor. Peggy wants to convince Victor that she knows how to unlock the door dividing a looping path through a tunnel in a cave.
The ‘proof’ involves Peggy walking, unseen by Victor, down path A or B (see diagram below; image from Wikipedia). Once Peggy is out of view, Victor randomly shouts out A or B; Peggy then has to walk out of the tunnel using the path Victor shouted; there is a 50% chance that Peggy happened to choose the path selected by Victor. The proof is iterative; at the end of each iteration, Victor’s uncertainty of Peggy’s claim of being able to open the door is reduced by 50%. Victor has to iterate until he is sufficiently satisfied that Peggy knows how to open the door.
As the name suggests, non-interactive proofs do not involve any message passing; in the common reference string model, a string of symbols, generated by person making the claim of knowledge, is encoded in such a way that it can be used by third-parties to verify the claim of knowledge. At the workshop we got an overview of zk-SNARKs (zero-knowledge succinct non-interactive argument of knowledge).
The ‘succinct’ component of zk-SNARK is what has made this approach practical. When non-interactive proofs were first proposed, the arguments of knowledge contained around one-terabyte of data; these days common reference strings are around a kilobyte.
The fact that zero-knowledge ‘proof’s are possible is very interesting, but do they have practical uses?
The hackathon aspect of the workshop was designed to address the practical use issue. The existing zero-knowledge proofs tend to involve the use of prime numbers, or the factors of very large numbers (as might be expected of a proof system that is heavily based on cryptographic techniques). Making use of zero-knowledge proofs requires mapping the problem to a form that has a known solution; this is very hard. Existing applications involve cryptography and block-chains (Zcash is a cryptocurrency that has an option that provides privacy via zero-knowledge proofs), both heavy users of number theory.
The workshop introduced us to two languages, which could be used for writing zero-knowledge applications; ZoKrates and snarky. The weekend before the workshop, I tried to install both languages: ZoKrates installed quickly and painlessly, while I could not get snarky installed (I was told that the first two hours of the snarky workshop were spent getting installs to work); I also noticed that ZoKrates had greater presence than snarky on the web, in the form of pages discussing the language. It seemed to me that ZoKrates was the market leader. The workshop presenters included people involved with both languages; Jacob Eberhardt (one of the people behind ZoKrates) gave a great presentation, and had good slides. Team ZoKrates is clearly the one to watch.
As an experienced hack attendee, I was ready with an interesting problem to solve. After I explained the problem to those opting to use ZoKrates, somebody suggested that oblivious transfer could be used to solve my problem (and indeed, 1-out-of-n oblivious transfer does offer the required functionality).
My problem was: Let’s say I have three software products, the customer has a copy of all three products, and is willing to pay the license fee to use one of these products. However, the customer does not want me to know which of the three products they are using. How can I send them a product specific license key, without knowing which product they are going to use? Oblivious transfer involves a sequence of message exchanges (each exchange involves three messages, one for each product) with the final exchange requiring that I send three messages, each containing a separate product key (one for each product); the customer can only successfully decode the product-specific message they had selected earlier in the process (decoding the other two messages produces random characters, i.e., no product key).
Like most hackathons, problem ideas were somewhat contrived (a few people wanted to delve further into the technical details). I could not find an interesting team to join, and left them to it for the rest of the week.
There were 50-60 people on the first day, and 30-40 on the second. Many of the people I spoke to were recent graduates, and half of the speakers were doing or had just completed PhDs; the field is completely new. If zero-knowledge proofs take off, decisions made over the next year or two by the people at this workshop will impact the path the field follows. Otherwise, nothing happens, and a bunch of people will have interesting memories about stuff they dabbled in, when young.
Lehman ‘laws’ of software evolution
The so called Lehman laws of software evolution originated in a 1968 study, and evolved during the 1970s; the book “Program Evolution: processes of software change” by Lehman and Belady was published in 1985.
The original work was based on measurements of OS/360, IBM’s flagship operating system for the computer industries flagship computer. IBM dominated the computer industry from the 1950s, through to the early 1980s; OS/360 was the Microsoft Windows, Android, and iOS of its day (in fact, it had more developer mind share than any of these operating systems).
In its day, the Lehman dataset not only bathed in reflected OS/360 developer mind-share, it was the only public dataset of its kind. But today, this dataset wouldn’t get a second look. Why? Because it contains just 19 measurement points, specifying: release date, number of modules, fraction of modules changed since the last release, number of statements, and number of components (I’m guessing these are high level programs or interfaces). Some of the OS/360 data is plotted in graphs appearing in early papers, and can be extracted; some of the graphs contain 18, rather than 19, points, and some of the values are not consistent between plots (extracted data); in later papers Lehman does point out that no statistical analysis of the data appears in his work (the purpose of the plots appears to be decorative, some papers don’t contain them).
One of Lehman’s early papers says that “… conclusions are based, comes from systems ranging in age from 3 to 10 years and having been made available to users in from ten to over fifty releases.“, but no other details are given. A 1997 paper lists module sizes for 21 releases of a financial transaction system.
Lehman’s ‘laws’ started out as a handful of observations about one very large software development project. Over time ‘laws’ have been added, deleted and modified; the Wikipedia page lists the ‘laws’ from the 1997 paper, Lehman retired from research in 2002.
The Lehman ‘laws’ of software evolution are still widely cited by academic researchers, almost 50-years later. Why is this? The two main reasons are: the ‘laws’ are sufficiently vague that it’s difficult to prove them wrong, and Lehman made a large investment in marketing these ‘laws’ (e.g., publishing lots of papers discussing these ‘laws’, and supervising PhD students who researched software evolution).
The Lehman ‘laws’ are not useful, in the sense that they cannot be used to make predictions; they apply to large systems that grow steadily (i.e., the kind of systems originally studied), and so don’t apply to some systems, that are completely rewritten. These ‘laws’ are really an indication that software engineering research has been in a state of limbo for many decades.
Update: Added numbers from appendix of “Software Engineering Metrics and Models” by Conte, Dunsmore, and Shen.
PCTE: a vestige of a bygone era of ISO standards
The letters PCTE (Portable Common Tool Environment) might stir vague memories, for some readers. Don’t bother checking Wikipedia, there is no article covering this PCTE (although it is listed on the PCTE acronym page).
The ISO/IEC Standard 13719 Information technology — Portable common tool environment (PCTE) —, along with its three parts, has reached its 5-yearly renewal time.
The PCTE standard, in itself, is not interesting; as far as I know it was dead on arrival. What is interesting is the mindset, from a bygone era, that thought such a standard was a good idea; and, the continuing survival of a dead on arrival standard sheds an interesting light on ISO standards in the 21st century.
PCTE came out of the European Union’s first ESPRIT project, which ran from 1984 to 1989. Dedicated workstations for software developers were all the rage (no, not those toy microprocessor-based thingies, but big beefy machines with 15 inch displays, and over a megabyte of memory), and computer-aided software engineering (CASE) tools were going to provide a huge productivity boost.
PCTE is a specification for a tool interface, i.e., an interface whereby competing CASE tools could provide data interoperability. The promise of CASE tools never materialized, and they faded away, removing the need for an interface standard.
CASE tools and PCTE are from an era where lots of managers still thought that factory production methods could be applied to software development.
PCTE was a European-funded project coordinated by a (at the time) mainframe manufacturer. Big is beautiful, and specifications with clout are ISO standards (ECMA was used to fast track the document).
At the time Ada was the language that everybody was going to be writing in the future; so, of course, there is an Ada binding (there is also a C one, cannot ignore reality too much).
Why is there still an ISO standard for PCTE? All standards are reviewed every 5-years, countries have to vote to keep them, or not, or abstain. How has this standard managed to ‘live’ so long?
One explanation is that by being dead on arrival, PCTE never got the chance to annoy anybody, and nobody got to know anything about it. Standard’s committees tend to be content to leave things as they are; it would be impolite to vote to remove a document from the list of approved standards, without knowing anything about the subject area covered.
The members of IST/5, the British Standards committee responsible (yes, it falls within programming languages), know they know nothing about PCTE (and that its usage is likely to be rare to non-existent) could vote ABSTAIN. However, some member countries of SC22 might vote YES, because while they know they know nothing about PCTE, they probably know nothing about most of the documents, and a YES vote does not require any explanation (no, I am not suggesting some countries have joined SC22 to create a reason for flunkies to spend government money on international travel).
Prior to the Internet, ISO standards were only available in printed form. National standards bodies were required to hold printed copies of ISO standards, ready for when an order to arrive. When a standard having zero sales in the last 5-years, came up for review a pleasant person might show up at the IST/5 meeting (or have a quiet word with the chairman beforehand); did we really want to vote to keep this document as a standard? Just think of the shelf space (I never heard them mention the children dead trees). Now they have pdfs occupying rotating rust.
Recent Comments