Archive
Modular vs. monolithic programs: a big performance difference
For a long time now I have been telling people that no experiment has found a situation where the treatment (e.g., use of a technique or tool) produces a performance difference that is larger than the performance difference between the subjects.
The usual results are that differences between people is the source of the largest performance difference, successive runs are the next largest (i.e., people get better with practice), and the smallest performance difference occurs between using/not using the technique or tool.
This is rather disheartening news.
While rummaging through a pile of books I had not looked at in many years, I (re)discovered the paper “An empirical study of the effects of modularity on program modifiability” by Korson and Vaishnavi, in “Empirical Studies of Programmers” (the first one in the series). It’s based on Korson’s 1988 PhD thesis, with the same title.
There were four experiments, involving seven people from industry and nine students, each involving modifying a 900(ish)-line program in some way. There were two versions of each program, they differed in that one was written in a modular form, while the other was monolithic. Subjects were permuted between various combinations of program version/problem, but all problems were solved in the same order.
The performance data (time to complete the task) was published in the paper, so I fitted various regressions models to it (code+data). There is enough information in the data to separate out the effects of modular/monolithic, kind of problem and subject differences. Because all subjects solved problems in the same order, it is not possible to extract the impact of learning on performance.
The modular/monolithic performance difference was around twice as large as the difference between subjects (removing two very poorly performing subjects reduces the difference to 1.5). I’m going to have to change my slides.
Would the performance difference have been so large if all the subjects had been experienced developers? There is not a lot of well written modular code out there, and so experienced developers get lots of practice with spaghetti code. But, even if the performance difference is of the same order as the difference between developers, that is still a very worthwhile difference.
Now there are lots of ways to write a program in modular form, and we don’t know what kind of job Korson did in creating, or locating, his modular programs.
There are also lots of ways of writing a monolithic program, some of them might be easy to modify, others a tangled mess. Were these programs intentionally written as spaghetti code, or was some effort put into making them easy to modify?
The good news from the Korson study is that there appears to be a technique that delivers larger performance improvements than the difference between people (replication needed). We can quibble over how modular a modular program needs to be, and how spaghetti-like a monolithic program has to be.
Evidence-based election campaigning
I was at a hackathon on evidence-based election campaigning yesterday, organized by Campaign Lab.
My previous experience with political oriented hackathons was a Lib Dem hackathon; the event was only advertised to party members and I got to attend because a fellow hackathon-goer (who is a member) invited me along. We spent the afternoon trying to figure out how to extract information on who turned up to vote, from photocopies of lists of people eligible to vote marked up by the people who hand out ballot papers.
I have also been to a few hackathons where the task was to gather and analyze information about forthcoming, or recent, elections. There did not seem to be a lot of information publicly available, and I had assumed that the organization, and spending power, of the UK’s two main parties (i.e., Conservative and Labour) meant that they did have data.
No, the main UK political parties don’t have lots of data, in fact they don’t have very much at all, and make hardly any use of what they do have.
I had a really interesting chat with Campaign Lab’s Morgan McSweeney, about political campaigning, and how they have not been evidence-based. There were lots of similarities with evidence-based software engineering, e.g., a few events (such the Nixon vs. Kennedy and Bill Clinton elections) created campaigning templates that everybody else now follows. James Moulding drew diagrams showing Labour organization and Conservative non-organization (which looked like a Dalek) and Hannah O’Rourke spoiled us with various kinds of biscuits.
An essential component of evidence-based campaigning is detailed knowledge of the outcome, such as: how many votes did each candidate get? Based on past hackathon experience, I thought this data was only available for recent elections, but Morgan showed me that Wikipedia had constituency level results going back many years. Here was a hackathon task; collect together constituency level results, going back decades, in one file.
Following the Wikipedia citations led me to Richard Kimber’s website, which had detailed results at the constituency level going back to 1945. The catch was that there was a separate file for each constituency; I emailed Richard, asking for a file containing everything (Richard promptly replied, the only files were the ones on the website).
Pivot.
The following plot was created using some of the data made available during a hackathon at the Office of National Statistics (sometime in 2015). We (Pavel+others and me) did not make much use of this plot at the time, but it always struck me as interesting. I showed it to the people at this hackathon, who sounded interested. The plot shows the life-expectancy for people living in a constituency where Conservative(blue)/Labour(red) candidate won the 2015 general election by a given percentage margin, over the second-placed candidate.
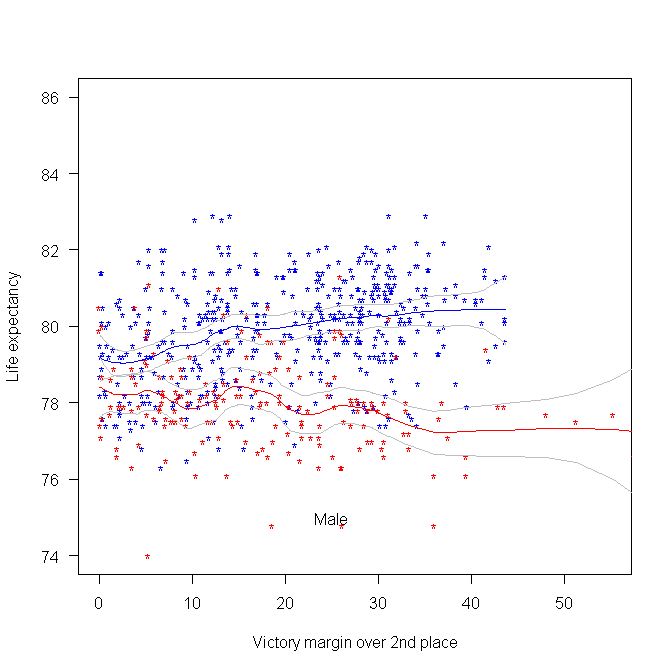
Rather than scrape the election data (added to my TODO list), I decided to recreate the plot and tidy up the associated analysis code; it’s now available via the CampaignLab Github repo
My interpretation of the difference in life-expectancy is that the Labour strongholds are in regions where there is (or once was) lots of heavy industry and mining; the kind of jobs where people don’t live long after retiring.
Offer of free analysis of your software engineering data
Since the start of this year, I have been telling people that I willing to analyze their software engineering data for free, provided they are willing to make the data public; I also offer to anonymize the data for them, as part of the free service. Alternatively you could read this book, and do the analysis yourself.
What will you get out of me analyzing your data?
My aim is to find patterns of behavior that will be useful to you. What is useful to you? You have to be the judge of that. It is possible that I will not find anything useful, or perhaps any patterns at all; this does not happen very often. Over the last year I have found (what I think are useful) patterns in several hundred datasets, with one dataset that I am still scratching my head over it.
Data analysis is a two-way conversation. I find some patterns, and we chat about them, hopefully you will say one of them is useful, or point me in a related direction, or even a completely new direction; the process is iterative.
The requirement that an anonymized form of the data be made public is likely to significantly reduce the offers I receive.
There is another requirement that I don’t say much about: the data has to be interesting.
What makes software engineering data interesting, or at least interesting to me?
There has to be lots of it. How much is lots?
Well, that depends on the kind of data. Many kinds of measurements of source code are generally available by the truck load. Measurements relating to human involvement in software development are harder to come by, but becoming more common.
If somebody has a few thousand measurements of some development related software activity, I am very interested. However, depending on the topic, I might even be interested in a couple of dozen measurements.
Some measurements are very rare, and I would settle for as few as two measurements. For instance, multiple implementations of the same set of requirements provides information on system development variability; I was interested in five measurements of the lines of source in five distinct Pascal compilers for the same machine.
Effort estimation data used to be rare; published papers sometimes used to include a table containing the estimate/actual data, which was once gold-dust. These days I would probably only be interested if there were a few hundred estimates, but it would depend on what was being estimated.
If you have some software engineering data that you think I might be interested in, please email to tell me something about the data (and perhaps what you would like to know about it). I’m always open to a chat.
If we both agree that it’s worth looking at your data (I will ask you to confirm that you have the rights to make it public), then you send me the data and off we go.
Recent Comments