Archive
The world view of research in software engineering
For a long time I have been trying to figure out why so much research in software engineering is so obviously unconnected to the reality of software development.
As might have been guessed, the answer has been staring me in the face for some time.
Many researchers in software engineering have a modified mathematicians’ world view of research, i.e., investigate things we find interesting (the mathematicians’ view) and some years from now industry will discover our work and apply it (the modification). I have had multiple academics essentially say this to me and I had not appreciated that I need to argue against a world view (not specific points of that view). This mathematician world view also explains why my questions about evidence receive such baffled looks; and, I am regularly told that experiments cannot be done, or are meaningless, in software engineering research.
Which research field’s world view might be closest to software engineering? I would nominate drug discovery.
Claims made by researchers in drug discovery are expected to be backed up with evidence. There are problems to be solved (e.g., diseases to be cured) and researchers try out ideas by running experiments. They don’t put lots of time and effort into creating a new drug, propose this drug as cure for some disease and then wait for industry to run some experiments, to see if the claims are true. I’m a regular reader of In The Pipeline, an interesting drug discover blog that is accessible to those outside the field.
How do I argue against a world view? I have no idea; even if I did, I am not looking to start a crusade.
At least I now have a model of the situation that makes sense. Next month, I will be attending some workshops where there will be lots of researchers and I will get to try out my new insight.
A 1948 viewpoint on developer vs. computer time
For a long time now developer time has been a lot more expensive than computer time. The idea that developers should organize what they do, so as to maximize the efficiency of computer time rather than their own time, is considered to be an echo from a bygone age.
Until recently, I thought the transition from this bygone age, when computer time was considered more important than developer time, started in the late 1960s. Don’t ask me why I thought this, put it down to personal bias.
I was recently reading A Survey of Eniac Operations and Problems: 1946-1952, published in 1952, and what did I find:
“Early in 1948, R. F. Clippinger and some of his associates, in the course of coding the solution of …, were forced to adopt a different method of using the Eniac in order to fit their problem on the machine. …. The experience with this method (first discussed in reference 1), led J. von Neumann to suggest the use of a serial code for control of the Eniac. Such a code was devised and employed with the Eniac beginning in March 1948. Operation of the Eniac with this code was several times slower than either the original method of direct programming or the code for parallel operation. However, the resulting simplification of coding techniques and other advantages far outweighed this disadvantage.”
In other words, in 1948, the people using one of the few computers in the world, which clocked at 100KHz, considered developer time to be more important than computer time.
Major players in evidence-based software engineering
Who are the major players in evidence-based software engineering?
How might ‘majorness’ of players be calculated? For me, the amount of interesting software engineering data they have made publicly available is the crucial factor. Any data published in a book, paper or report is enough to be considered interesting. How interesting is data published on a web page? This is a tough question, let’s dodge the question to start with, and consider the decades before the start of 2000.
In the academic world performance is based on number of papers published, the impact factor of where they were published and number of citations of those papers. This skews the results in favor of those with lots of students (who tack their advisor’s name on the end of papers published) and those who are good at marketing.
Historians of computing have primarily focused on the evolution of hardware and are slowly moving to discuss software (perhaps because microcomputers have wiped out nearly every hardware vendor). So we will have to wait perhaps a decade or two for tentative/definitive historian answer.
The 1950s
Computers and Automation is a criminally underused resource (a couple of PhDs worth of primary data here). A lot of the data is hardware related, but software gets a lot more than a passing mention.
The US military published lots of hardware data, but software does not get mentioned much.
The 1960s
Computers and Automation are still publishing.
The US military still publishing data; again mostly hardware related.
Datamation, a weekly news magazine, published a lot of substantial material on the software and hardware ecosystems as they evolved.
Kenneth Knight’s analysis of computer performance is an example of the kind of data analysis that many people undertook for hardware, which was rarely done for software.
The 1970s
The US military are still leading the way; we are in the time of Rome. Air Force officers studying for a Master’s degree publish more software engineering data than all academics combined over this and the next two decades.
“Data processing technology and economics” by Montgomery Phister is 720 A4 pages packed with graphs and tables of numbers. Despite citing earlier sources, this has become the primary source for a lot of subsequent researchers; this is understandable in a pre-internet age. Now we have Bitsavers and the Internet Archive, and the cited primary source can be downloaded.
NASA is surprisingly low volume.
The 1980s
Rome falls (i.e., the work gets outsourced to a university) and the false prophets (i.e., academics doing non-evidence based work) multiply and prosper. There are hushed references to trouble makers performing unclean acts experiments in the wilderness.
A few people working in the wilderness, meaning that the quantity of data being produced drops by at least an order of magnitude.
The 1990s
Enough time has passed for people to be able to refer to the wisdom of the ancients.
There are still people in the wilderness howling at the moon, and performing unclean acts experiments.
The 2000s
Repositories of Open source and bug reports grow and prosper. Evidence-based software engineering research starts to become mainstream.
There are now groups of people doing software engineering research.
What about individuals as major players? A vaguely scientific way of rating individual impact, on evidence-based software engineering, is to count the number of papers researchers have published, that are cited by a book claiming to discuss all the important/interesting publicly available software engineering data (code+data).
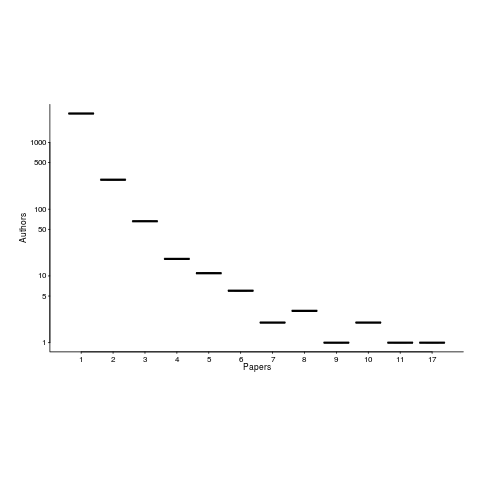
The 1,521 2,035 papers cited, by this book, had 3,716 5,095 authors, of which 3,095 4,210 were different. The authors who appeared most often are listed below (count on the right, and yes, at number 3 2 is a theoretician; I have cited myself nine 17 times, but two of those are to websites hosting data; Updated numbers to published version).
Magne Jorgensen 20 17
Massimiliano Di Penta 13 10
Anne Chao 10 11
Dag I. K. Sjoberg 10
Joseph Henrich 10
Ahmed E. Hassan 9 8
Christian Kästner 9
Sven Apel 9
Tom Mens 9
Audris Mockus 8
Christian Bird 8
Stanislas Dehaene 8
Andreas Zeller 7
Dror G. Feitelson 7 6
Gabriele Bavota 7
Giuliano Antoniol 7
Krzysztof Czarnecki 7 6
Rocco Oliveto 7
Thomas Zimmermann 7
Benoit Baudry 6
Bram Adams 6
Daniel M. German 6
Gerd Gigerenzer 6
Gregorio Robles 6
Lutz Prechelt 6
Victor R. Basili 6
Martin Monperrus 6
Alexander Serebrenik 5 6
The number of authors/papers follows the usual pattern of many people writing one paper.
Who might I have missed? The business school researchers don’t get a mention because their data is often covered by a confidentiality agreement. The machine learning crowd are just embarrassing.
Suggestions for major players welcome.
Business school research in software engineering is some of the best
There is a group of software engineering researchers that don’t feature as often as I would like in my evidence-based software engineering book; academics working in business schools.
Business school academics have written some of the best papers I have read on software engineering; the catch is that the data they use is confidential. For somebody writing a book that only discusses a topic if there is data publicly available, this is a problem.
These business school researchers show that it is possible for academics to obtain ‘interesting’ software engineering data from industry. My experience with talking to researchers in computing departments is that most are too involved in their own algorithmic bubble to want to talk to anybody else.
One big difference between the data analysis papers written by academics in computing departments and business schools, is statistical sophistication. Computing papers are still using stone-age pre-computer age techniques, the business papers use a wide range of sophisticated techniques (sometimes cutting edge).
There is one aspect of software engineering papers written by business school researchers that grates with me, many of the authors obviously don’t understand software engineering from a developer’s perspective; well, obviously, they are business oriented people.
The person who has done the largest amount of interesting software engineering research, whose work I don’t (yet; I will find a way) discuss, is Chris Kemerer; a researcher who has a long list of empirical papers going back to the late 1980s, and rarely gets cited by papers by people in computing departments (I am the only person I know, who limits themself to papers where the data is publicly available).
Moving to the 12th cycle in fault prediction modeling
Most software fault prediction papers are based on a false assumption, i.e., a list of dates when a fault was first experienced, by a program, contains enough information to build a model that has a connection to reality. A count of faults that have been experienced twice is also required, to fit a basic model that has some mathematical connection to reality.
I had thought that people had moved on from writing papers that fitted yet more complicated equations to one of the regularly used data sets. No, it seems they have just switched to publishing someplace they have not been seen before.
Table 1 lists the every increasing number of cycles within cycles; the new model is proposed as the 12th refinement (the table is a summary, lots of forks have been proposed over the years). I have this sinking feeling there is another paper in the works, one that ‘benchmarks’ the new equation using a collection of the other regular characters data sets that appear in papers of this kind.
Fitting an equation to data of first experience of a fault is little better than fitting noise.
As Planck famously said, science advances one funeral at a time.
Recent Comments