Estimating the number of distinct faults in a program
In an earlier post I gave two reasons why most fault prediction research is a waste of time: 1) it ignores the usage (e.g., more heavily used software is likely to have more reported faults than rarely used software), and 2) the data in public bug repositories contains lots of noise (i.e., lots of cleaning needs to be done before any reliable analysis can done).
Around a year ago I found out about a third reason why most estimates of number of faults remaining are nonsense; not enough signal in the data. Date/time of first discovery of a distinct fault does not contain enough information to distinguish between possible exponential order models (technical details; practically all models are derived from the exponential family of probability distributions); controlling for usage and cleaning the data is not enough. Having spent a lot of time, over the years, collecting exactly this kind of information, I was very annoyed.
The information required, to have any chance of making a reliable prediction about the likely total number of distinct faults, is a count of all fault experiences, i.e., multiple instances of the same fault need to be recorded.
The correct techniques to use are based on work that dates back to Turing’s work breaking the Enigma codes; people have probably heard of Good-Turing smoothing, but the slightly later work of Good and Toulmin is applicable here. The person whose name appears on nearly all the major (and many minor) papers on population estimation theory (in ecology) is Anne Chao.
The Chao1 model (as it is generally known) is based on a count of the number of distinct faults that occur once and twice (the Chao2 model applies when presence/absence information is available from independent sites, e.g., individuals reporting problems during a code review). The estimated lower bound on the number of distinct items in a closed population is:

and its standard deviation is:
![S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}](https://shape-of-code.com/wp-content/plugins/wpmathpub/phpmathpublisher/img/math_977.5_e69346120e72f31d04a47c9fcf64c4dd.png "S_{sd-est}={f_1}/{f_2}k sqrt{f_2(0.5/{k}+{f_1}/{f_2} [1+0.25 {f_1}/{f_2}])}")
where:  is the estimated number of distinct faults,
is the estimated number of distinct faults,  the observed number of distinct faults,
the observed number of distinct faults,  the total number of faults,
the total number of faults,  the number of distinct faults that occurred once,
the number of distinct faults that occurred once,  the number of distinct faults that occurred twice,
the number of distinct faults that occurred twice,  .
.
A later improved model, known as iChoa1, includes counts of distinct faults occurring three and four times.
Where can clean fault experience data, where the number of inputs have been controlled, be obtained? Fuzzing has become very popular during the last few years and many of the people doing this work have kept detailed data that is sometimes available for download (other times an email is required).
Kaminsky, Cecchetti and Eddington ran a very interesting fuzzing study, where they fuzzed three versions of Microsoft Office (plus various Open Source tools) and made their data available.
The faults of interest in this study were those that caused the program to crash. The plot below (code+data) shows the expected growth in the number of previously unseen faults in Microsoft Office 2003, 2007 and 2010, along with 95% confidence intervals; the x-axis is the number of faults experienced, the y-axis the number of distinct faults.
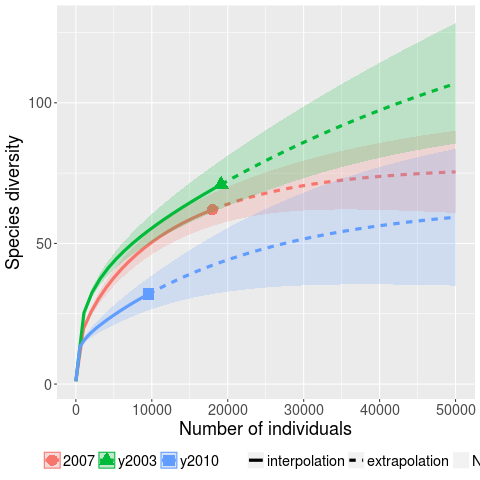
The take-away point: if you are analyzing reported faults, the information needed to build models is contained in the number of times each distinct fault occurred.
Recent Comments