Double exponential performance hit in C# compiler
Yesterday I was reading a blog post on the performance impact of using duplicated nested types in a C# generic class, such as the following:
class Class<A, B, C, D, E, F> { class Inner : Class<Inner, Inner, Inner, Inner, Inner, Inner> { Inner.Inner inner; } } |
Ah, the joys of exploiting a language specification to create perverse code 🙂
The author, Matt Warren, had benchmarked the C# compiler for increasing numbers of duplicate types; good man. However, the exponential fitted to the data, in the blog post, is obviously not a good fit. I suspected a double exponential might be a better fit and gave it a go (code+data).
Compile-time data points and fitted double-exponential below:
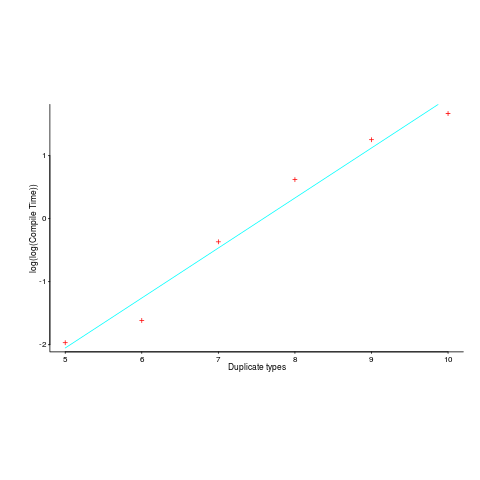
Yes, for compile time the better fit is:  and for binary size:
and for binary size:  , where
, where  ,
,  are some constants and
are some constants and  the number of duplicates.
the number of duplicates.
I had no idea what might cause this pathological compiler performance problem (apart from the pathological code) and did some rummaging around. No luck; I could not find any analysis of generic type implementation that might be used to shine some light on this behavior.
Ideas anybody?
Off-topic : a study of dozens of programs written in a security contest : https://cybersecurity.ieee.org/blog/2017/08/28/michael-hicks-on-why-building-security-in-requires-new-ways-of-thinking/
I have not read the paper to see whether the methodology is correct, or if the sample size allows relevant results or only anecdotal evidence, but they seem to at least *try* doing it right : “Next what we’d like to do is dig into these findings. For example, we are devising an experiment to compare, in a controlled setting, programmers who are trained in C and C++ with programmers who start that way but then are taught a safer programming language. We’re thinking about using Go for that comparison. Using this setup, we can more safely conclude causation rather than correlation.”