Archive
Vanity project or real research?
I gave a talk at the CREST Open Workshop yesterday. Many of those attending and speaking were involved in empirical work of one kind or another. My experience is that researchers involved in empirical work, in software engineering, feel the need to justify using this approach to research, because it is different from what many others in the field do. I want to reverse this perception; those not doing empirical work are the ones that should feel the need to justify their approach to research.
Evidence obtained from experiments and measurements are the basis of the scientific method.
I started by contrasting a typical software engineering researcher’s view of their work (both images from Wikipedia under a Creative Commons Attribution-ShareAlike License):
.jpg)
with a common industry view of academic researchers:

The reputation of those doing evidence based research is being completely overshadowed by those who use ego and bluster to promote their claims. We needed an effective label for work that is promoted using ego and bluster, and I proposed vanity projects (the work done by the ego and bluster crowd does not deserve to be referred to as research). Yes, there are plenty of snake-oil salesmen in industry, but that is another issue.
Vanity projects being passed off as research should be named and shamed.
Next time you are in the audience listening to claims made by the speaker about the results of his/her research, that are not backed up by experiments or measurements, ask them why decided to pursue a vanity project rather than proper research.
Data-set update to “Empirical software engineering using R”
The pile of papers, books and data-sets, relating to previously released draft chapters of my Empirical software engineering book, has been growing, and cluttering up my mind. I decided to have a clear-out.
A couple of things stood out.
There are around 25 data-sets that have been promised but not yet arrived. If you encounter anybody who mentions they promised to send me data, please encourage them to spend some time doing this. I don’t want to add a new category, promised but never delivered, to the list of email responses.
There has been an increase in data-sets not being used because I already have something better. This is a good sign, data quality is increasing. One consequence is that a growing number of ‘historical’ data-sets have fallen by the wayside. This is a good thing, most data-sets analysed in papers are very low quality and only used because nothing else was available.
One of my reasons for making draft releases was to prompt people to suggest data I had missed. This has not happened yet; come on people, suggest some data I don’t yet know about.
About a third of the pile got included in the latest draft, a third had been superseded by something better, and a third are still waiting for promised data.
Now, back to the reliability chapter.
Grace Hopper: Manager, after briefly being a programmer
In popular mythology, Grace Hopper is a programmer who wrote one of the first compilers. I think the reality is that Hopper did some programming, but quickly moved into management; a common career path for freshly minted PhDs and older people entering computing (Hopper was in her 40s when she started); her compiler management work occurred well after many other compilers had been written.
What is the evidence?
Hopper is closely associated with Cobol. There is a lot of evidence for at least 28 compilers in 1957, well before the first Cobol compiler (can a compiler written after the first 28 be called one of the first?)
The A-0 tool, which Hopper worked on as a programmer in 1951-52, has been called a compiler. However, the definition of Compile used sounds like today’s assembler and the definition of Assemble used sounds like today’s link-loader (also see: section 7 of Digital Computers – Advanced Coding Techniques for Hopper’s description of what A-2, a later version, did).
The ACM’s First Glossary of Programming Terminology, produced by a committee chaired by Hopper in June 1954.
Routine – a set of coded instructions arranged in proper sequence to direct the computer to perform a desired operation or series of operations. See also Subroutine.
Compiler (Compiling Routine) – an executive routine which, before the desired computation is started, translates a program expressed in pseudo-code into machine code (or into another pseudo-code for further translation by an interpreter). In accomplishing the translation, the compiler may be required to:
…
Assemble – to integrate the subroutines (supplied, selected, or generated) into the main routine, i.e., to:
Adapt – to specialize to the task at hand by means of preset parameters.
Orient – to change relative and symbolic addresses to absolute form.
Incorporate – to place in storage.
Hopper’s name is associated with work on the MATH-MATIC and ARITH-MATIC Systems, but her name does not appear in the list of people who wrote the manual in 1957. A programmer working on these systems is likely to have been involved in producing the manual.
After the A-0 work, all of Hopper’s papers relate to talks she gave, committees she sat on and teams she led, i.e., the profile of a manager.
À la carte Entropy
My observation that academics treat Entropy as the go-to topic, when they have no idea what else to talk about, has ruffled a few feathers. David Clark, one of the organizers of a workshop on Information Theory and Software Testing has invited me to give a talk on Entropy (the title is currently Entropy for the uncertain, but this state might change :-).
Complaining about the many ways entropy is currently misused in software engineering would be like shooting fish in a barrel, and equally pointless. I want to encourage people to use entropy in a meaningful way, and to stop using Shannon entropy just because it is the premium brand of entropy.
Shannon’s derivation of the iconic formula  depends on various assumptions being true. While these conditions look like they might hold for some software engineering problems, they clearly don’t hold for others. It may be possible to use other forms of entropy for some of these other problems; Shannon became the premium brand of entropy because it was first to market, the other entropy products have not had anyone championing their use, and academics follow each other like sheep (it’s much easier to get a paper published by using the well-known brands).
depends on various assumptions being true. While these conditions look like they might hold for some software engineering problems, they clearly don’t hold for others. It may be possible to use other forms of entropy for some of these other problems; Shannon became the premium brand of entropy because it was first to market, the other entropy products have not had anyone championing their use, and academics follow each other like sheep (it’s much easier to get a paper published by using the well-known brands).
Shannon’s entropy has been generalized, with the two most well-known being (in the limit  , both converge to Shannon entropy):
, both converge to Shannon entropy):
Rényi entropy in 1961: ")
Tsallis entropy in 1988: ")
All of these formula reduce a list of probabilities to a single value. A weighting is applied to each probability, and this weighted value is summed to produce a single value that is further manipulated. The probability weighting functions are plotted below:
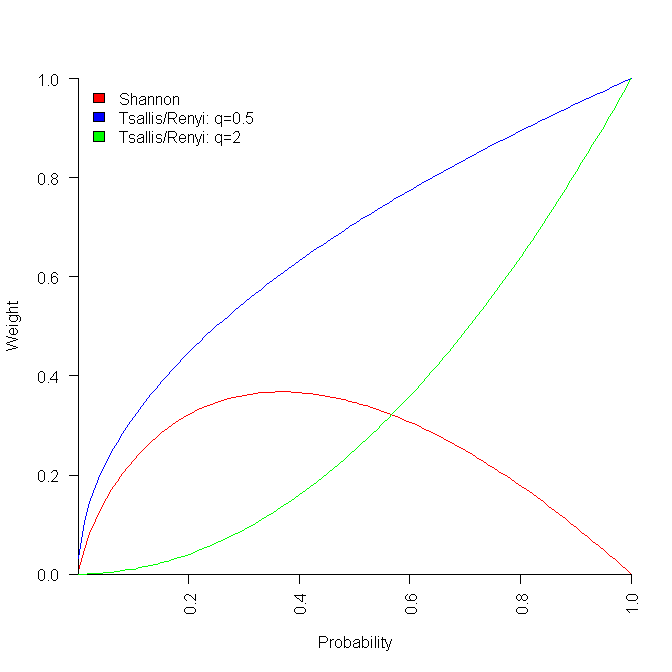
Under what conditions might one of these two forms of entropy be used (there are other forms)? I have been rummaging around looking for example uses, and could not find many.
There are some interesting papers about possible interpretations of the  parameter in Tsallis entropy: the most interesting paper I have found shows a connection with the correlation between states, e.g., preferential attachment in networks. This implies that Tsallis entropy is the natural first candidate to consider for systems exhibiting power law characteristics. Another paper suggests
parameter in Tsallis entropy: the most interesting paper I have found shows a connection with the correlation between states, e.g., preferential attachment in networks. This implies that Tsallis entropy is the natural first candidate to consider for systems exhibiting power law characteristics. Another paper suggests  derives from variation in the parameter of an exponential equation.
derives from variation in the parameter of an exponential equation.
Some computer applications: a discussion of Tsallis entropy and the concept of non-extensive entropy, along with an analysis of statistical properties of hard disc workloads, the same idea applied to computer memory.
Some PhD thesis: Rényi entropy, with  , for error propagation in software architectures, comparing various measures of entropy as a metric for the similarity of program execution traces, plus using Rényi entropy in cryptography
, for error propagation in software architectures, comparing various measures of entropy as a metric for the similarity of program execution traces, plus using Rényi entropy in cryptography
As you can see, I don’t have much to talk about. I’m hoping my knowledgeable readers can point me at some uses of entropy in software engineering where the author has put some thought into which entropy to use (which may have resulted in Shannon entropy being chosen; I’m only against this choice when it is made for brand name reasons).
Registration for the workshop is open, so turn up and cheer me on.
Roll your own weighting plot:
p_vals=seq(0.001, 1.001, by=0.01) plot(p_vals, -p_vals*log(p_vals), type="l", col="red", ylim=c(0, 1), xaxs="i", yaxs="i", xlab="Probability", ylab="Weight") q=0.5 lines(p_vals, p_vals^q, type="l", col="blue") q=2 lines(p_vals, p_vals^q, type="l", col="green") |
Double exponential performance hit in C# compiler
Yesterday I was reading a blog post on the performance impact of using duplicated nested types in a C# generic class, such as the following:
class Class<A, B, C, D, E, F> { class Inner : Class<Inner, Inner, Inner, Inner, Inner, Inner> { Inner.Inner inner; } } |
Ah, the joys of exploiting a language specification to create perverse code 🙂
The author, Matt Warren, had benchmarked the C# compiler for increasing numbers of duplicate types; good man. However, the exponential fitted to the data, in the blog post, is obviously not a good fit. I suspected a double exponential might be a better fit and gave it a go (code+data).
Compile-time data points and fitted double-exponential below:
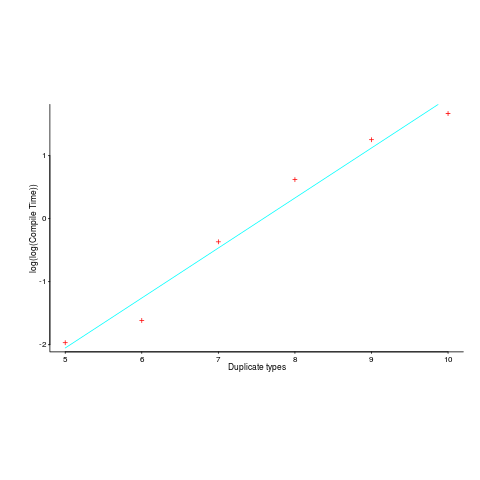
Yes, for compile time the better fit is:  and for binary size:
and for binary size:  , where
, where  ,
,  are some constants and
are some constants and  the number of duplicates.
the number of duplicates.
I had no idea what might cause this pathological compiler performance problem (apart from the pathological code) and did some rummaging around. No luck; I could not find any analysis of generic type implementation that might be used to shine some light on this behavior.
Ideas anybody?
Huge effort data-set for project phases
I am becoming a regular reader of software engineering articles written in Chinese and Japanese; or to be more exact, I am starting to regularly page through pdfs looking at figures and tables of numbers, every now and again cutting-and-pasting sequences of logograms into Google translate.
A few weeks ago I saw the figure below, and almost fell off my chair; it’s from a paper by Yong Wang and Jing Zhang. These plots are based on data that is roughly an order of magnitude larger than the combined total of all the public data currently available on effort break-down by project phase.
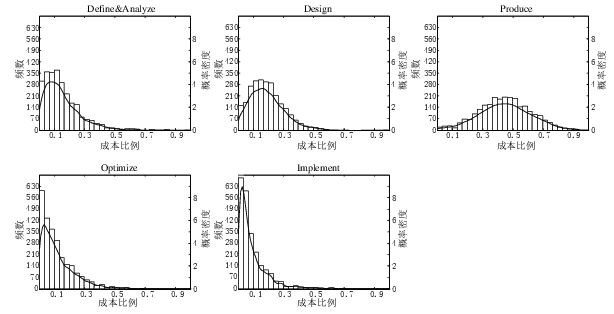
Projects are often broken down into phases, e.g., requirements, design, coding (listed as ‘produce’ above), testing (listed as ‘optimize’), deployment (listed as ‘implement’), and managers are interested in knowing what percentage of a project’s budget is typically spent on each phase.
Projects that are safety-critical tend to have high percentage spends in the requirements and testing phase, while in fast moving markets resources tend to be invested more heavily in coding and deployment.
Research papers on project effort usually use data from earlier papers. The small number of papers that provide their own data might list effort break-down for half-a-dozen projects, a few require readers to take their shoes and socks off to count, a small number go higher (one from the Rome period), but none get into three-digits. I have maybe a few hundred such project phase effort numbers.
I emailed the first author and around a week later had 2,570 project phase effort (man-hours) percentages (his co-author was on marriage leave, which sounded a lot more important than my data request); see plot below (code+data).
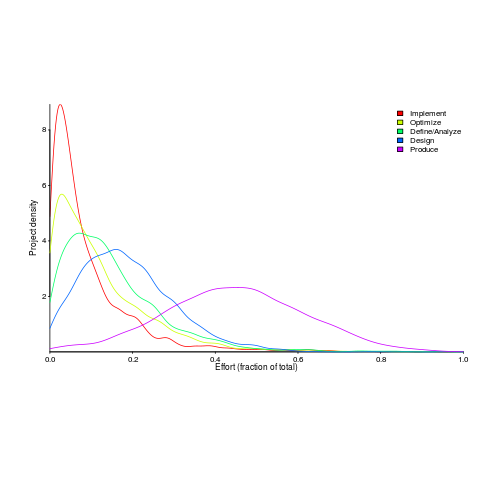
I have tried to fit some of the obvious candidate distributions to each phase, but none of the fits were consistently good across the phases (see code for details).
This project phase data is from small projects, i.e., one person over a few months to ten’ish people over more than a year (a guess based on the total effort seen in other plots in the paper).
A typical problem with samples in software engineering is their small size (apart from bugs data, lots of that is available, at least in uncleaned form). Having a sample of this size means that it should be possible to have a reasonable level of confidence in the results of statistical tests. Now we just need to figure out some interesting questions to ask.
Recent Comments