Archive
Experimental method for measuring benefits of identifier naming
I was recently came across a very interesting experiment in Eran Avidan’s Master’s thesis. Regular readers will know of my interest in identifiers; while everybody agrees that identifier names have a significant impact on the effort needed to understand code, reliably measuring this impact has proven to be very difficult.
The experimental method looked like it would have some impact on subject performance, but I was not expecting a huge impact. Avidan’s advisor was Dror Feitelson, who kindly provided the experimental data, answered my questions and provided useful background information (Dror is also very interested in empirical work and provides a pdf of his book+data on workload modeling).
Avidan’s asked subjects to figure out what a particular method did, timing how long it took for them to work this out. In the control condition a subject saw the original method and in the experimental condition the method name was replaced by local and parameter names were replaced by single letter identifiers; in all cases the method name was replaced by xxx andxxx. The hypothesis was that subjects would take longer for methods modified to use ‘random’ identifier names.
A wonderfully simple idea that does not involve a lot of experimental overhead and ought to be runnable under a wide variety of conditions, plus the difference in performance is very noticeable.
The think aloud protocol was used, i.e., subjects were asked to speak their thoughts as they processed the code. Having to do this will slow people down, but has the advantage of helping to ensure that a subject really does understand the code. An overall slower response time is not important because we are interested in differences in performance.
Each of the nine subjects sequentially processed six methods, with the methods randomly assigned as controls or experimental treatments (of which there were two, locals first and parameters first).
The procedure, when a subject saw a modified method was as follows: the subject was asked to explain the method’s purpose, once an answer was given (or 10 mins had elapsed) either the local or parameter names were revealed and the subject had to again explain the method’s purpose, and when an answer was given the names of both locals and parameters was revealed and a final answer recorded. The time taken for the subject to give a correct answer was recorded.
The summary output of a model fitted using a mixed-effects model is at the end of this post (code+data; original experimental materials). There are only enough measurements to have subject as a random effect on the treatment; no order of presentation data is available to look for learning effects.
Subjects took longer for modified methods. When parameters were revealed first, subjects were 268 seconds slower (on average), and when locals were revealed first 342 seconds slower (the standard deviation of the between subject differences was 187 and 253 seconds, respectively; less than the treatment effect, surprising, perhaps a consequence of information being progressively revealed helping the slower performers).
Why is subject performance less slow when parameter names are revealed first? My thoughts: parameter names (if well-chosen) provide clues about what incoming values represent, useful information for figuring out what a method does. Locals are somewhat self-referential in that they hold local information, often derived from parameters as initial values.
What other factors could impact subject performance?
The number of occurrences of each name in the body of the method provides an opportunity to deduce information; so I think time to figure out what the method does should less when there are many uses of locals/parameters, compared to when there are few.
The ability of subjects to recognize what the code does is also important, i.e., subject code reading experience.
There are lots of interesting possibilities that can be investigated using this low cost technique.
Linear mixed model fit by REML ['lmerMod']
Formula: response ~ func + treatment + (treatment | subject)
Data: idxx
REML criterion at convergence: 537.8
Scaled residuals:
Min 1Q Median 3Q Max
-1.34985 -0.56113 -0.05058 0.60747 2.15960
Random effects:
Groups Name Variance Std.Dev. Corr
subject (Intercept) 38748 196.8
treatmentlocals first 64163 253.3 -0.96
treatmentparameters first 34810 186.6 -1.00 0.95
Residual 43187 207.8
Number of obs: 46, groups: subject, 9
Fixed effects:
Estimate Std. Error t value
(Intercept) 799.0 110.2 7.248
funcindexOfAny -254.9 126.7 -2.011
funcrepeat -560.1 135.6 -4.132
funcreplaceChars -397.6 126.6 -3.140
funcreverse -466.7 123.5 -3.779
funcsubstringBetween -145.8 125.8 -1.159
treatmentlocals first 342.5 124.8 2.745
treatmentparameters first 267.8 106.0 2.525
Correlation of Fixed Effects:
(Intr) fncnOA fncrpt fncrpC fncrvr fncsbB trtmntlf
fncndxOfAny -0.524
funcrepeat -0.490 0.613
fncrplcChrs -0.526 0.657 0.620
funcreverse -0.510 0.651 0.638 0.656
fncsbstrngB -0.523 0.655 0.607 0.655 0.648
trtmntlclsf -0.505 -0.167 -0.182 -0.160 -0.212 -0.128
trtmntprmtf -0.495 -0.184 -0.162 -0.184 -0.228 -0.213 0.673 |
An Almanac of the Internet
My search for software engineering data has turned me into a frequent buyer of second-hand computer books, many costing less than the postage of £2.80. When the following suggestion popped up along-side a search, I could not resist; there must be numbers in there!

The concept of an Almanac will probably be a weird idea to readers who grew up with search engines and Wikipedia. But yes, many years ago, people really did make a living by manually collecting information and selling it in printed form.
One advantage of the printed form is that updating it requires a new copy, the old copy lives on unchanged (unlike web pages); the disadvantage is taking up physical space (one day I will probably abandon this book in a British rail coffee shop).
Where did Internet users hang out in 1997?
The history of the Internet, as it appeared in 1997.

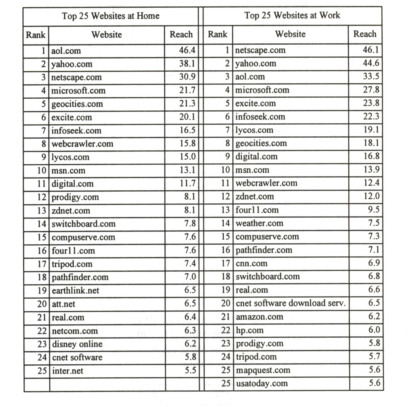
Of course, a list of web sites is an essential component of an Internet Almanac:

Investing in the gcc C++ front-end
I recently found out that RedHat are investing in improving the C++ front-end of gcc, i.e., management have assigned developers to work in this area. What’s in it for RedHat? I’m told there are large companies (financial institutions feature) who think that using some of the features added to recent C++ standards (these have been appearing on a regular basis) will improve the productivity of their developers. So, RedHat are hoping this work will boost their reputation and increase their sales to these large companies. As an ex-compiler guy (ex- in the sense of being promoted to higher levels that require I don’t do anything useful), I am always in favor or companies paying people to work on compilers; go RedHat.
Is there any evidence that features that have been added to any programming language improved developer productivity? The catch to this question is defining programmer productivity. There have been several studies showing that if productivity is defined as number of assembly language lines written per day, then high level languages are more productive than assembler (the lines of assembler generated by the compiler were counted, which is rather compiler dependent).
Of the 327 commits made this year to the gcc C++ front-end, by 29 different people, 295 were made by one of 17 people employed by RedHat (over half of these commits were made by two people and there is a long tail; nine people each made less than four commits). Measuring productivity by commit counts has plenty of flaws, but has the advantage of being easy to do (thanks Jonathan).
Recent Comments